

Die Bildersuche hat heutzutage eine immer größere Bedeutung. Nutzerinnen und Nutzer möchten Informationen nicht mehr ausschließlich über Text finden. Sie wollen diese auch direkt über Bilder suchen, vergleichen und verstehen. Ob es um das Erkennen von Produkten, Orten, Personen, Objekten oder visuellen Ähnlichkeiten geht: Die Bildersuche ermöglicht ein schnelles und intuitives Entdecken von Inhalten.
Dank moderner Technologien der künstlichen Intelligenz, insbesondere Computer Vision, ist es heutzutage möglich, dass Bilder automatisch analysiert und mit passenden Informationen verknüpft werden. Die Bildersuche ermöglicht es, nicht nur über einen bestimmten Begriff nach Bildern zu suchen, sondern auch ein Bild selbst als Suchanfrage zu verwenden.
Dieser Blogbeitrag untersucht das Prinzip der Bildersuche. Wir erklären, warum sie so bekannt und wichtig geworden ist, wie sie grundsätzlich funktioniert und geben einen Überblick über verschiedene Arten der Bildersuche. Das Weiteren schauen wir uns an, wie ein Bild technisch analysiert wird und welche Rolle Computer Vision dabei spielt.
Warum Bildersuche?
In den letzten Jahren haben visuelle Inhalte im Internet enorm an Bedeutung gewonnen. Bilder begegnen uns überall, sei es in sozialen Medien, in Online-Shops oder auf Webseiten. Sie helfen uns, Informationen schneller zu begreifen, Produkte besser zu vergleichen oder Inhalte leichter einzuordnen. Aus diesem Grund ist es oft nicht ausreichend, nur mit Text zu suchen. Nutzerinnen und Nutzer möchten Bilder schnell finden, vergleichen oder weitere Informationen zu einem Bild erhalten. An dieser Stelle kommt die Bildersuche ins Spiel.
Die Bildersuche kann Zeit sparen und die Suche verfeinern, vor allen wenn man ein Produkt, einen Ort oder ein ähnliches Bild finden möchte.
Was ist Bildersuche?
Allgemein bedeutet Bildersuche, dass passende Bilder zu einer bestimmten Eingabe gefunden werden. Diese Eingabe kann variieren. Man kann zum Beispiel einen Suchbegriff eingeben oder ein vorhandenes Bild hochladen. Im ersten Fall sucht das System nach Bildern, die inhaltlich zur Texteingabe passen. Gibt man zum Beispiel „rotes Handy“ ein, erscheinen passenden Bilder von roten Handys. Im Gegensatz dazu erfolgt bei einer Bildeingabe die Analyse des Bildes selbst. Anschließend sucht das System nach ähnlichen oder identischen Bildern.
Außerdem ist die Bildersuche ein nützliches Werkzeug, um die Herkunft eines Bildes zu ermitteln oder um zu überprüfen, ob ein Bild echt ist oder bearbeitet wurde.
Was ist Computer Vision?
Computer Vision ist ein wichtiger Teilgebiet der künstlichen Intelligenz. Es geht darum, Bilder, Videos und andere visuelle Informationen automatisch zu verarbeiten und zu analysieren.
Künstliche Intelligenz versucht, bestimmte Fähigkeiten des menschlichen Denkens nachzubilden. Computer Vision hingegen orientiert sich an der Art und Weise, wie Menschen visuelle Informationen erkennen, verarbeiten und interpretieren. Moderne Algorithmen können Bildinhalte erkennen, bestimmte Teile eines Bildes analysieren und daraus Informationen gewinnen. Mit dieser Grundlage können Systeme Objekte identifizieren, Muster erkennen, Entscheidungen unterstützen oder Empfehlungen geben.
Computer Vision wird in vielen Bereichen eingesetzt. Ein Beispiel ist die Bildersuche, bei der ähnliche oder passende Bilder zu einer Eingabe gefunden werden. Weitere Anwendungen sind die Gesichtserkennung und die Analyse von medizinischen Bilder. Auch beim autonomen Fahren spielt Computer Vision eine wichtige Rolle. Fahrzeuge müssen ihre Umgebung durch Kameras analysieren, um sicher zu fahren.
Verschiedene Arten von Bildersuche
Es gibt verschiedene Arten der Bildersuche. Der Unterschied liegt darin, auf welcher Grundlage die Suche erfolgt und wie Bilder analysiert oder miteinander verglichen werden.
In diesem Beitrag konzentrieren wir uns auf die am häufigsten verwendeten und am weitesten verbreiteten Methoden der Bildersuche. Eine vollständige Übersicht über alle Verfahren würde den Rahmen dieses Beitrags sprengen.
Keyword-basierte Bildersuche
Bei der keyword-basierten Bildersuche sucht der Nutzer mit Begriffen oder kurzen Beschreibungen. Das ist eine klassische Form der Bildersuche, die hinter vielen bekannten Suchmaschinen steckt.
Dabei wird nicht unbedingt das Bild selbst analysiert. Das System sucht vor allem in den Textinformationen, die mit dem Bild verbunden sind. Dazu gehören zum Beispiel der Alt-Text, der Bildtitel, der Dateiname, Bildunterschriften oder auch der Text auf der Webseite in der Nähe des Bildes.
Man kann das als eine Art Anreicherung durch Metadaten verstehen. Das Bild wird also durch zusätzliche Informationen beschrieben, damit es später besser gefunden werden kann. Je genauer und strukturierter diese Informationen sind, desto besser kann das Bild über Text gefunden werden. Für die Suche können in diesem Fall Ansätze wie lexikalische Suche, semantische Suche oder eine Kombination aus beiden verwendet werden. Dieser Ansatz ist sehr nützlich für eine allgemeinere Bildersuche und Recherche.
Bei der Produktsuche in einem Online-Shop kann diese Art der Bildersuche eine wichtige Rolle spielen. Produktbilder werden besser gefunden, wenn sie mit passenden Produktnamen, Kategorien und Attributen verbunden sind.
Reverse Image Search
Bei der Reverse Image Search, also der umgekehrten Bildersuche, startet die Suche nicht mit einem Textbegriff, sondern mit einem vorhandenen Bild.
Der Nutzer lädt dafür ein Bild hoch oder fügt eine Bild-URL ein. Danach analysiert das Suchsystem dieses Bild und vergleicht es mit bereits indexierten Bildern in einer Datenbank.
So lassen sich gleiche oder ähnliche Bilder finden. Man kann zum Beispiel herausfinden, wo ein Bild ursprünglich veröffentlicht wurde, auf welchen Webseiten es noch verwendet wird, oder ähnliche Bilder und Produkte entdecken.
Technisch betrachtet analysieren solche Systeme visuelle Merkmale wie Farben, Formen, Muster, Kanten oder Texturen. Diese Informationen werden oft in eine mathematische Darstellung umgewandelt und dann mit vielen gespeicherten Bildern verglichen.
Reverse Image Search kann technisch auf unterschiedliche Weise umgesetzt werden. Grundsätzlich lassen sich dabei zwei Ansätze unterscheiden: ein direkter und ein indirekter Ansatz.
Beim direkten Ansatz wird das Bild selbst verarbeitet. Ein Vision-Modell wandelt es direkt in ein sogenanntes Bild-Embedding um. Dabei handelt es sich um eine numerische Darstellung und beschreibt seine visuellen Eigenschaften. Diese Embeddings können anschließend in einer Vektordatenbank gespeichert werden. Wenn ein Nutzer ein Bild hochlädt, wird auch dieses Bild mit demselben Modell in ein Embedding umgewandelt und mit den gespeicherten Embeddings verglichen. Der Vorteil dieses Ansatzes ist, dass visuelle Ähnlichkeiten meist sehr gut erkannt werden können.
Beim indirekten Ansatz wird das Bild nicht direkt über seine visuellen Merkmale gesucht. Stattdessen erzeugt ein Vision-Modell zuerst eine Beschreibung des Bildes. Diese Beschreibung wird anschließend wie normaler Text verarbeitet, vektorisiert und für die Suche gespeichert. Im Prinzip wird danach ähnlich gearbeitet wie bei der keyword-basierten Bildersuche, nur dass die Textinformationen automatisch aus dem Bild erzeugt werden. Dieser Ansatz lässt sich oft leichter in bestehende Textsuche- oder RAG-Systeme integrieren, weil am Ende mit Text gearbeitet wird. Gleichzeitig können dabei aber visuelle Details verloren gehen. Zwei Bilder können ähnlich beschrieben werden, obwohl sie visuell unterschiedlich aussehen. Umgekehrt können kleine, aber wichtige visuelle Unterschiede in der Beschreibung fehlen.
Für eine effizientere Bildersuche kann es sinnvoll sein, beide Ansätze zu kombinieren. So werden nicht nur visuelle Ähnlichkeiten berücksichtigt, sondern auch zusätzliche Textinformationen, die die Suche verbessern können.
Reverse Image Search kann in verschiedenen Bereichen eingesetzt werden. Häufig wird sie genutzt, um zu prüfen wo ein Bild zuerst veröffentlicht wurde, ob es schon auf anderen Webseiten verwendet wird oder ob es aus einem anderen Zusammenhang stammt. Auch für Faktenchecks, beim Urheberrecht und im E-Commerce kann sie nützlich sein, zum Beispiel um Bildkopien, ähnliche Produkte oder die Verwendung von Produktbildern auf anderen Plattformen zu erkennen.
Visual Similarity Search
Bei der Visual Similarity Search sucht man nach Bildern, die ähnlich aussehen. Technisch kann das ähnlich funktionieren wie bei der Reverse Image Search. Auch hier können Bilder zum Beispiel in Bild-Embeddings umgewandelt und miteinander verglichen werden.
Der Unterschied liegt vor allem im Ziel der Suche. Bei Reverse Image Search geht es meistens darum, das gleiche Bild, Kopien oder fast identische Versionen zu finden. Visual Similarity Search sucht eher nach Bildern, die ähnlich wirken. Wichtig hier ist, dass bestimmte visuelle Merkmale übereinstimmen, zum Beispiel Farben, Formen, Muster, Texturen, Layout oder Stil.
Aus diesem Grung ist Visual Similarity Search besonders interessant für Bereiche wie Mode, Interior Design oder E-Commerce. Wenn ein Nutzer ein Produkt öffnet, kann der Online-Shop automatisch ähnliche Artikel anzeigen.
Weitere Arten der Bildersuche
Neben den bereits genannten Methoden gibt es noch weitere Arten der Bildersuche. Einige davon konzentrieren sich nicht auf das gesamte Bild, sondern auf bestimmte Merkmale wie Farben, Muster, Texture oder einzelne Objekte.
Bei der Color-Based Image Search werden Bilder vor allem über ihre Farben gesucht. Technisch kann dafür ein Farbhistogramm verwendet werden. Dabei wird analysiert, welche Farben oder Farbbereiche in einem Bild wie stark vorkommen. Auf dieser Grundlage lassen sich Bilder mit einer ähnlichen Farbverteilung finden.
Bei der Pattern-Based Image Search steht die Suche nach Mustern und Texturen im Vordergrund. Dazu gehören zum Beispiel Streifen, Punkte, geometrische Formen oder Oberflächen wie Stoff, Holz, Leder oder Stein. Das System versucht solche Merkmale aus dem Bild zu extrahieren und mit anderen Bildern zu vergleichen. Diese Art der Suche kann besonders dort nützlich sein, wo das Aussehen eines Materials oder Designs wichtig ist, zum Beispiel bei Textilien, Tapeten, Möbeln oder Produktdesign.
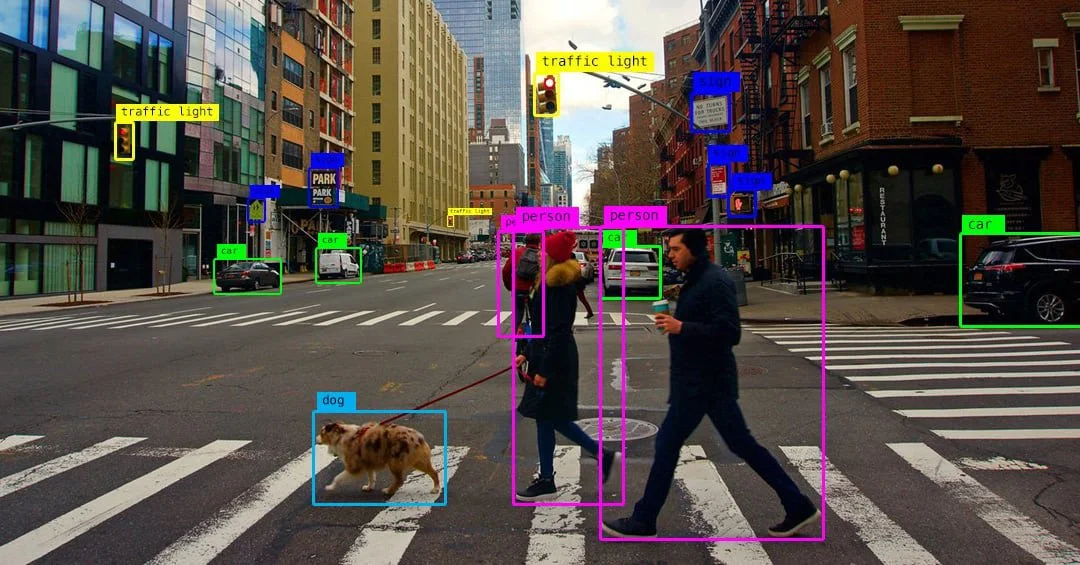
Eine weitere Richtung ist die Object and Facial Recognition Search. Hier versucht das System, konkrete Inhalte innerhalb eines Bildes zu erkennen, zum Beispiel Gesichter, Produkte, Logos, Fahrzeuge oder auch Text im Bild. Bei der Objekterkennung kann ein Nutzer zum Beispiel einen bestimmten Bereich im Bild markieren, etwa eine Tasche oder eine Lampe. Das System sucht anschließend nach diesem Objekt oder ähnlichen Produkten. Das System sucht dann nach genau diesem Objekt oder nach ähnlichen Produkten.
Bei der Gesichtserkennung steht dagegen die Person im Mittelpunkt. Das System analysiert Merkmale eines Gesichts und vergleicht sie mit Gesichtern aus einer Datenbank oder mit öffentlich verfügbaren Bildern im Internet. Gerade bei dieser Methode spielen Datenschutz und rechtliche Vorgaben eine besonders große Rolle.
Wie wird ein Bild verarbeitet?
Das drei Layer System
Bei der Verarbeitung von Bildern mit neuronalen Netzwerken kann man vereinfacht von einem 3-Layer-System sprechen. Dieses System hilft dabei zu verstehen, wie ein Bild analysiert und für die Suche nutzbar gemacht wird.
Der erste Layer umfasst Machine Vision und Pattern Recognition. In diesem Schritt wird das Bild durch ein neuronales Netzwerk verarbeitet, zum Beispiel durch ein CNN (Convolutional Neural Network) oder ein Transformer-basiertes Vision-Modell. Das System versucht dabei, visuelle Merkmale zu erkennen, etwa Objekte, Farben, Formen, Muster oder Gesichter. Auch Text im Bild, kann über OCR (Optical Character Recognition) erkannt und weiterverarbeitet werden.
Nach der Extraktion von den Merkmalen geht es im zweiten Layer um Vector Embeddings und Similarity Matching. Hier passiert im Grunde das, was wir oben bereits beschrieben haben: Bilder werden in Embeddings umgewandelt und anschließend mit gespeicherten Embeddings verglichen, um visuell ähnliche Ergebnisse zu finden.
Der dritte Layer umfasst Contextual Layering und Ranking Signals. Hier kommen zusätzliche Informationen hinzu, die nicht direkt aus dem Bild selbst stammen. Dazu gehören Alt-Text, Dateiname, Bildunterschriften, strukturierte Daten, das Thema der Webseite oder auch Nutzersignale. Diese Informationen können beeinflussen, welche Ergebnisse am Ende weiter oben angezeigt werden.
Die wichtige Idee dahinter ist: Bildersuche basiert nicht nur auf dem visuellen Inhalt eines Bildes. Gute Suchsysteme kombinieren visuelle Merkmale, Embeddings und Kontextsignale, um möglichst relevante Ergebnisse zu liefern.
Fazit und Ausblick
Bildersuche umfasst heute verschiedene Ansätze, die je nach Ziel und Anwendungsfall eingesetzt werden können. Moderne Systeme nutzen Computer Vision, Embeddings, Metadaten und Kontextinformationen, damit Bilder besser analysiert und gefunden werden können. Besonders interessant wird Bildersuche dort, wo visuelle Informationen eine wichtige Rolle spielen, zum Beispiel in Online-Shops und digitalen Medien. Dort kann sie helfen, Inhalte schneller zu finden, ähnliche Ergebnisse vorzuschlagen und die Suche insgesamt effizienter zu machen.


