

Wichtige Begriffe und einige Anwendungsbeispiele für die neuronale Suche
Wie kann ich mit Machine Learning die Intention von Suchanfragen erfassen? Und was kann ich damit sonst noch tun? Diese und andere Fragen beantworten wir in zwei Blogartikeln, die eine Einführung in das Thema Neuronale Netzwerke für Suchmaschinen bieten.
Im Folgenden klären wir zunächst wichtige Begriffe und stellen einige Anwendungsmöglichkeiten vor. Im zweiten Teil, den wir demnächst veröffentlichen, wird es dann um einen technisch tieferen Einblick gehen, und wir zeigen, wie eine semantische Such mit Hilfe von Apache Solr umgesetzt werden kann.
Inhaltsverzeichnis:
- Neural Search und klassische Suche: der Unterschied
- Semantische Suche: Textsuche mit Neural Search
- Anwendungen von Neural Search: einige Beispiele
a. Semantische Suche
b. Reranking
c. Hybride Suche - Transformer Modelle: was kann man damit sonst noch machen?
a. Multimodale Suche
b. Eigennamenerkennung (Named Entity Recognition) - Fazit und Ausblick
Neural Search und klassische Suche: der Unterschied
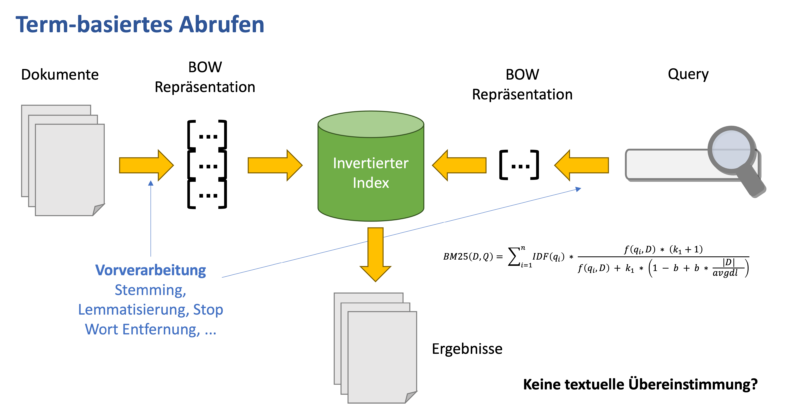
Im Bereich der Suche gibt es verschiedene Technologien und Ansätze, um Kunden zu ermöglichen, diejenigen Informationen und Produkte zu finden, die sie benötigen. Klassische Suchmaschinen benutzen hierbei eine sogenannte syntaktische Suche. Sie suchen nach Produkten und Texten, die entweder die Wörter der Suche exakt enthalten oder rein textuell damit zusammenhängen.
Die syntaktische Suche läuft, sehr vereinfacht dargestellt, folgendermaßen ab:
- Die Wörter aus der Suchanfrage werden gegen die Wörter in den Dokumenten abgeglichen. Für jedes Treffer-Dokument wird die Anzahl, wie oft jedes Wort darin vorkommt, gespeichert.
- Diese Zahlen werden dann damit verglichen, wie oft diese Wörter in den verschiedenen Dokumenten vorkommen. Hierbei werden Wörter, die allgemein weniger oft vorkommen, stärker gewichtet.
- Anhand der Übereinstimmung wird ein Relevanzwert berechnet, und die Dokumente mit den höchsten Werten werden ausgeliefert.
Die neuronale Suche – im Englischen bekannt als Neural Search – bietet hingegen einen anderen Ansatz. Sie benutzt sogenannte Transformer, um Dokumente und Suchanfragen auf ihre gegenseitige Relevanz zu bewerten. Transformer sind eine Kategorie von neuronalen Netzwerken, die sich besonders eignen, um größere Ein- und Ausgaben wie Texte oder Bilder zu verarbeiten.
Semantische Suche: Textsuche mit Neural Search
Bei der Textsuche werden als Transformer sogenannte Large Language Models (Große Sprachmodelle) eingesetzt. Im Gegensatz zur klassischen Suche wird hier die semantische Bedeutung der Suchbegriffe höher bewertet. Deshalb ist diese Form der Suche auch als semantische Suche oder „Semantic Search“ bekannt.
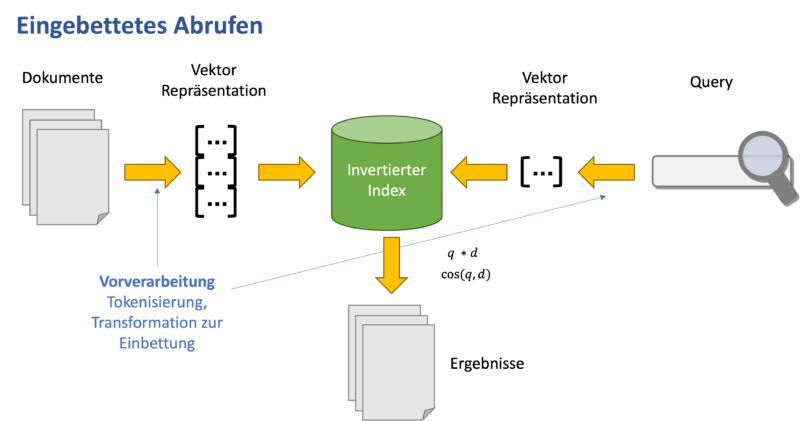
Ein großes Sprachmodell analysiert Suchanfragen und Teile von Dokumenten als Ganzes und ordnet diese dann in einem Vektorraum ein. Das ist – grob gesagt – ein Raum mit sehr vielen Dimensionen, in dem jede Richtung für einen anderen Aspekt der Bedeutung steht. Zum Beispiel: Eine Dimension sagt aus, wie viel das Dokument mit Tieren zu tun; eine andere Dimension gibt Auskunft darüber, mit welchem Land es zu tun hat; etc.
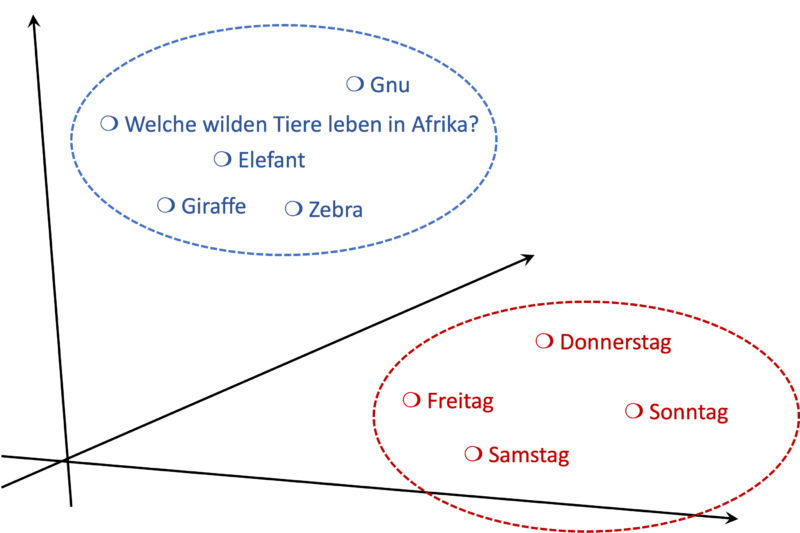
Suchanfragen und Dokumente, die eng miteinander verwandt sind, liegen deshalb in diesem Vektorraum nah aneinander. Hierbei werden also nicht nur die Wörter erfasst, sondern auch ihre tatsächliche Bedeutung. Je nach Einsatzbereich kann die Relevanz auf andere Art interpretiert oder bewertet werden. Bei juristischen Urteilen bildet sich die Relevanz aus ähnlichen Argumentationen oder Themenbereichen; bei Kleidungsstücken in einem Webshop zum Beispiel aus ihrer Saisonalität und dem Stil.
Anwendungen von Neural Search: einige Beispiele
Transformer Modelle können für verschiedene Aufgaben eingesetzt werden. Der Fokus unserer zwei Blogartikel liegt auf der Beurteilung von Relevanz von Treffern zu einer Suchanfrage. Aber auch weitere Möglichkeiten werden wir kurz besprechen.
Semantische Suche
Bei der semantischen Suche wird die gesamte Menge an Dokumenten durchsucht. Hierbei werden die Dokumente getrennt von der Suchanfrage vom Transformer verarbeitet. Im Vorfeld wird für jedes Dokument ein Vektor berechnet, der seine verschiedenen Bedeutungen erfasst. Die Vektoren für die Dokumente müssen nur einmalig berechnet werden und können dann in einem Index abgespeichert werden. Das verhindert, dass bei jeder Suche sehr große Berechnungen ausgeführt werden müssen.
Zur Suchzeit wird für die Suchanfrage ebenfalls ein Vektor berechnet und kontrolliert, welche Dokumente in der Nähe im Vektorraum liegen. Allerdings ist die exakte Ermittlung der sogenannten „Nächsten Nachbarn“ (Nearest Neighbors) bei einer großen Menge an Dokumenten auch sehr intensiv. Damit Suchanfragen nicht zu lange dauern, wird deshalb zu Näherungsverfahren gegriffen.
In rezenten Versionen von Apache Solr und Elasticsearch stehen diese Verfahren zur Verfügung und können ohne viel Aufwand und Komplexität benutzt werden. Voraussetzung dafür ist allerdings, dass das Transformer Modell für den Aufgabenbereich optimiert ist. Ohne eine Feinjustierung des Modells an den Aufgabenbereich (Finetuning) können nur sehr bedingt relevantere Dokumente gefunden werden als bei der klassischen Volltextsuche. Die Menge an vorhandenen Modellen und Anpassungsmethoden wächst allerdings zügig, was den Aufwand der Feinjustierung deutlich verringert.
Reranking
Beim Reranking wird eine kleinere Anzahl an Dokumenten zusammen mit der Suchanfrage bearbeitet. Dieses Verfahren liefert eine deutlich bessere Beurteilung der Relevanz als eine getrennte Verarbeitung. Allerdings müssen die Vektoren für jede Suchanfrage neu berechnet werden. Schon bei relativ kleinen Mengen an Dokumenten wird dies rechnerisch viel zu intensiv für eine normale Suche.
Deshalb wird Reranking benutzt, um die Ergebnisse einer vorgeschalteten Suche – zum Beispiel einer syntaktischen Suche oder einer ersten semantischen Suche – zu verfeinern. Im Gegensatz zur Suche liefert Reranking auch schon gute Ergebnisse ohne eine Feinjustierung des Sprachmodells. Deshalb kann es leicht in bestehende Workflows integriert werden, ohne dass ein Training des Modells geplant oder Trainingsdaten erstellt werden müssen. Eine Feinjustierung des Sprachmodells verbessert die Ergebnisse des Rerankings dennoch stark.
Wenn Reranking in Zusammenarbeit mit syntaktischer Suche verwendet wird, kann es die Ergebnisse nach semantischer Relevanz sortieren. Allerdings fehlen im Vergleich zur semantischen Suche gegebenenfalls relevante Dokumente, da sie von der syntaktischen Suche erst gar nicht als Treffer eingestuft werden. Auch Reranking können Sie in den neuesten Versionen von Apache Solr und Elasticsearch einsetzen.
Hybride Suche
Verschiedene Benchmarks zeigen, dass die semantische Suche einer syntaktischen Suche deutlich überlegen ist, solange das Sprachmodell für den Anwendungsbereich optimiert ist. Weitere Relevanzgewinne können erzielt werden durch die Kombination von semantischer und syntaktischer Suche.
Bei der sogenannten hybriden Suche werden parallel eine syntaktische und eine semantische Suche durchgeführt. Die Resultate der beiden Suchanfragen werden danach zusammengeführt. Dieser Ansatz hat allerdings den Nachteil, dass für beide Verfahren jeweils ein getrennter Index geführt werden muss.
Transformer Modelle: was kann man damit sonst noch machen?
Neben der Textsuche gibt es auch andere Aufgaben, bei denen Transformer Modelle helfen können, mehr aus Ihren Daten zu holen. Einige konkrete Beispiele bespricht unser Blog „Mit Deep Learning den Kunden mehr Fachwissen verfügbar machen“ .
Multimodale Suche
Um Suchanfragen und Dokumente bei neuronaler Suche miteinander vergleichen zu können, braucht man nur einen Vektor. Welche Form die Suchanfrage oder das Dokument dabei vorher hat, ist irrelevant. Transformer Modelle können nicht nur die Bedeutung von Text erfassen, sondern zum Beispiel auch auf Bildern erkennen, was dargestellt ist. So können Sie zum Beispiel alle Bilder mit einem roten Kleid finden, ohne dass die Wörter „Rot“ oder „Kleid“ in der Beschreibung stehen. Es gibt außerdem Transformer Modelle für Musik, Video und noch viel mehr.
Eigennamenerkennung (Named Entity Recognition)
In Dokumenten können mithilfe von Sprachmodellen Eigennamen identifiziert und klassifiziert werden. Hierbei handelt es sich zum Beispiel um Personen, Organisationen oder Orte. Wenn diese im Text identifiziert werden, können zum Beispiel Ortsangaben stärker gewichtet werden, ohne dass eine Liste mit allen Orten geführt werden muss.
Die Kategorien können auch passend zum Anwendungsfall definiert werden. Beispielsweise können in juristische Texten die Gerichtshöfe als Kategorie aufgeführt werden, oder Medikamente im medizinischen Umfeld.
Fazit und Ausblick
Neural Search ermöglicht es, auf eine andere Art zu suchen. Dabei muss die Suchanfrage nicht mehr genau abgestimmt sein auf den Wortlaut des gesuchten Textes, sondern vielmehr das, was mit der Suche gemeint ist.
Semantische Suche stellt keinen Ersatz zu syntaktischer Suche dar, sondern vielmehr eine Ergänzung. In Form einer hybriden Suche können sie sich gegenseitig unterstützen, um relevantere Suchergebnisse zu liefern.
Was bei der Umsetzung von semantischer Suche beachtet werden sollte, und wie diese mithilfe von Apache Solr gelingen kann, wird Thema des Blogartikels sein, den wir in Kürze hier veröffentlichen.


