

Deep Learning, ein allgemein einsetzbares Verfahren des Maschinellen Lernens, hat in den letzten Jahren dafür gesorgt, dass vielfältige Anwendungen von Künstlicher Intelligenz (KI) im Alltag und in der Industrie erfolgreich eingesetzt werden können: Autonomes Fahren dank Erkennung von Objekten in Bilddaten, natürlichsprachlich gesteuerte Computerassistenten, alltagstaugliche automatische Übersetzung zwischen verschiedenen Sprachen, Schachprogramme, die selbst den amtierenden Weltmeister schlagen, Deep-Fakes und vieles mehr. Der Erfolg von KI ist so maßgeblich von Deep Learning geprägt, dass viele nur Deep Learning als „echte KI“ ansehen, obwohl KI natürlich viele andere Methoden umfasst.
Deep Learning kann prinzipiell auf beliebige Daten und für vielfältige Aufgaben verwendet werden. Das gilt insbesondere für sprachliche Daten wie Audioaufnahmen oder Texte, aber auch für jede andere Art von sogenannten unstrukturierten Daten wie Bilder, um daraus strukturierte Informationen oder „Bedeutungen“ automatisiert zu gewinnen. So kann der Computer einen bestimmten Satz in einer Tonaufzeichnung erkennen und ihm eine entsprechende erwünschte Aktion zuordnen.
Aber wie funktioniert das, und wie kann ein Computer mit Hilfe von Deep Learning Sprache verstehen? Wir wagen hier das Prinzip mal anzureißen, um ein Gefühl für mögliche Anwendungen zu vermitteln.
Grundprinzip Neuronale Netze
Deep Learning bezieht sich auf die Verwendung von sogenannten Neuronalen Netzen mit vielen Schichten (daher das „deep“), um mit Hilfe eines Computers ein Problem zu lösen.
Neuronale Netze sind mathematische Modelle, die sich an die Funktionsweise der Neuronen in unserem Gehirn anlehnen: Ein Neuron im Netz kann die Signale anderer Neuronen als Input entgegennehmen und entscheiden, ein spezifisches Signal als Output an andere Neuronen weiterzuleiten, die wiederum selber entsprechend reagieren können, und so weiter. Ein Neuron ist letzten Endes nichts anderes als eine mathematische Funktion. Neuronale Netze für das Maschinelle Lernen gibt es schon seit den fünfziger Jahren, aber erst die heutzutage verfügbaren Rechenkapazitäten und Möglichkeiten zur parallelen Berechnung mit Graphik-Prozessoren haben es möglich gemacht Netze mit vielen Neuronen, wie sie im Deep Learning verwendet werden, für komplexe Aufgaben zu entwickeln.
Der Aufbau eines solchen Netzes ist immer ähnlich: Eine Gruppe von Neuronen im Netz stellt die Eingangsschicht für den Dateninput dar, zum Beispiel einzelne Pixel von Fotos. Am anderen Ende gibt es eine Ausgangsschicht, die den gewünschten Output zurückgibt, zum Beispiel im Bild erkannte Objekte wie „Mensch“, „Katze“ oder „Auto“. Dazwischen kommunizieren mehrere Schichten von Neuronen miteinander („Hidden Layers“), die dazu dienen, immer mehr Details und Muster im Input zu erfassen und Schicht für Schicht zu immer komplexeren Merkmalen zusammenführen, bis über den finalen Output entschieden werden kann. Bei Bildern kann man sich den Prozess so vorstellen:
Computer Vision:
Bilddaten (Pixeln) -> Kanten -> Formen -> Objekte
Die verschiedenen Schichten und die Vielzahl der Neuronen beim Deep Learning ermöglichen erst, aus großen Datenmengen komplexe Aufgaben zu lösen und so beispielsweise aus Pixeln Objekte zu abstrahieren.
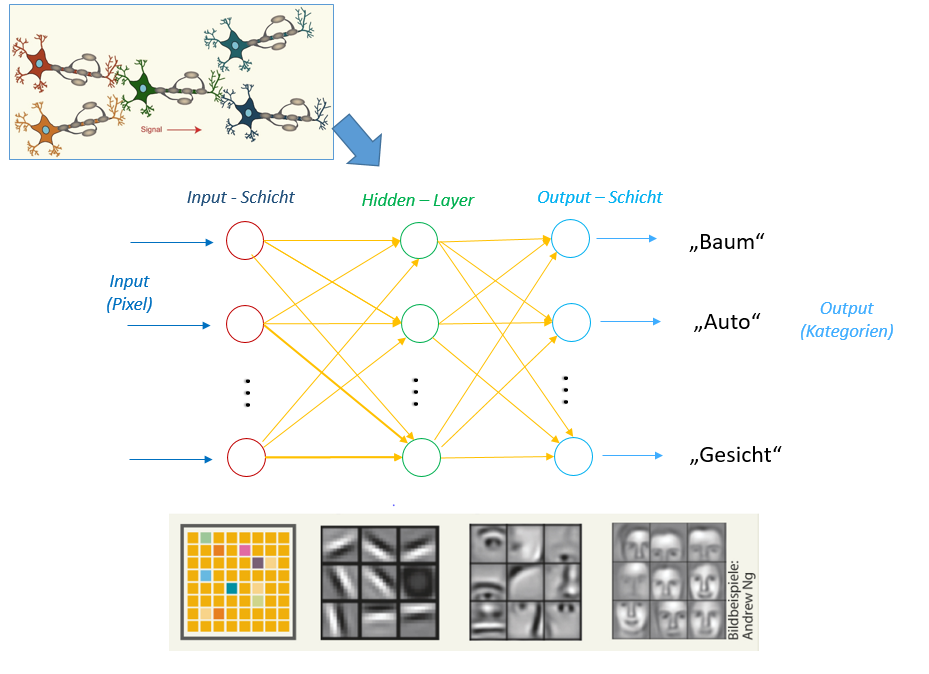
Dafür muss man aber jedes einzelne Neuron im Netz richtig „einstellen“, also das Zusammenspiel der einzelnen Funktionen im Modell anhand von sehr vielen Inputbeispielen optimieren – ein sehr rechenintensiver Vorgang, der als Training bezeichnet wird. Ein großer Teil der Kunst liegt auch darin, für das jeweilige Problem die beste Anordnung der Neuronen-Schichten zu finden.
Die Bedeutung von Sprache mit dem Computer modellieren
Bei der Verarbeitung von sprachlichen Daten mit Deep Learning ist das Prinzip genau das gleiche. Schicht für Schicht können so zum Beispiel aus einer langen Zeichenfolge, einem Input-Text, Wörter, grammatikalische Muster bis hin zu „Bedeutungen“ für einzelne Wörter oder Aussagen erfasst werden.
Natural Language Processing:
Textdaten (Zeichenfolgen) -> Wörter -> Kontextmerkmale -> Strukturmustern -> „Bedeutung“
Wie kann man sich diese vom Computer abstrahierte Bedeutung eines Worts vorstellen? Beispielsweise stellt eine bestimmte Art von Neuronalen Netzen, sogenannte Word2vec Modelle, die Bedeutung von Wörtern als eine Vielzahl von automatisch gewonnenen Merkmalen dar, die Auskunft darüber geben, wie ein Wort verwendet wird. Im Computer wird diese Information als eine lange Kolonne von Zahlen (Vektor) für die einzelnen Merkmale ausgedrückt.
Wie Merkmale die spezifische Verwendung eines bestimmten Wortes beschreiben können und was diese mit dessen Bedeutung zu tun hat, lässt sich mit einem Beispiel veranschaulichen: Wenn Sie ein Wort „X“ nicht kennen, aber verstehen wollen, und Beispiel-Sätze wie diese lesen:
X hat mir gestern gesagt, dass er nicht kommt.
Ich erwarte einen Anruf von X.
Hallo, X!
Dann kommen Sie relativ schnell zu dem Schluss, dass in diesem Fall mit „X“ eine bestimmte Person gemeint ist. „sagen“, „anrufen“, „hallo“ sind alles Wörter, die im Zusammenhang mit Personen vorkommen – das wissen Sie bereits. Wenn Sie umgekehrt nicht viel über „Personen“ wüssten, aber einige Namen von Personen kennen würden, könnten Sie gezielt in Texten nach Stellen suchen, in denen diese Namen vorkommen, solche Kontexte sammeln und so typische Merkmale gewinnen und etwas darüber erfahren, wie über Personen geredet wird – gewissermaßen was „Person“ „bedeutet“.
Ein Computer geht ähnlich vor: Er sammelt all die Kontexte für ein Wort und berechnet eine Vielzahl typischer Merkmale für diesen Kontext, die er als Zahlenvektor darstellt – dadurch beschreibt er die Bedeutung des Worts. Das interessante dabei ist, dass man mit den Vektoren rechnen kann. Zwei sehr ähnliche Vektoren können so Synonyme wie „Auto“ und „PKW“ darstellen. Auch andere Beziehungen lassen sich in diesem Modell „berechnen“.
Die Gleichung:
Berlin ist zu Deutschland wie Tegucigalpa zu Y
kann mit Hilfe eines Neuronalen Netzes gelöst werden:
Y = Honduras.
Das Prinzip zur Darstellung der Bedeutung einzelner Wörter lässt sich auch auf ganze Sätze oder Abschnitte übertragen, wofür Netze mit einem anderen Aufbau verwendet werden.
Deep Learning verwenden
Die Voraussetzung, um aus der Vielfalt sprachlicher Ausdrücke abstrakte Bedeutungen und Beziehungen mit einem Neuronalen Netz einfangen zu können, ist ein ausreichend gutes Training. Das Netz muss anhand von ausreichend vielen Datenbeispielen und Rechenleistung soweit optimiert werden, dass jedes einzelne Neuron richtig eingestellt wird, was in der Praxis das Erlernen von Millionen von Parameter für das gesamte Netz bedeutet.
Eine Sprache wie Englisch mit Hilfe von Deep Learning allgemein zu modellieren, kann sehr schnell sehr aufwändig werden. So hat die Non-Profit-Organisation openAI GPT3 entwickelt, ein sehr leistungsfähiges Neuronales Netz für Englisch, das vielfältige Anwendungen in hoher Qualität ermöglicht: Textgenerierung, automatische Zusammenfassung, Klassifikation, Übersetzung und Question-Answering. Laut Angaben hat openAI mindestens 4,6 Mio. USD investiert, um GPT3 mit 2 TB reinem Text (genauer gesagt 499 Milliarden Wortvorkommen) zu trainieren und so 175 Milliarden Parameter zu optimieren.
Für andere Sprachen wie Deutsch kann man auf weniger allgemein gerichtete, vortrainierte Deep-Learning-Modelle zurückgreifen, die das Standard-Vokabular gut abdecken und frei verfügbar sind. Für eine spezielle Domäne ist es ebenfalls möglich, mit begrenzten Aufwand Modelle der allgemeinen Sprache zu ergänzen, um Fachbegriffe zu berücksichtigen.
Deep Learning erschafft so neue Interaktionsformen zwischen Mensch und Computer und damit Möglichkeiten, sprachlich kodiertes Wissen zu erfassen und verfügbar zu machen.


