

Im ersten Teil dieser Blogserie haben wir zwei grundlegende Strategien zur Verbesserung der Suche in RAG-Systemen betrachtet: die hybride Suche und die asymmetrischen Embedding-Modelle. Beide verfolgen das Ziel, die Relevanz und Präzision der abgerufenen Informationen zu erhöhen.
Im zweiten Teil haben wir zwei Strategien untersucht, mit denen sich die Relevanz und Genauigkeit von Suchergebnissen in RAG-Systemen verbessern lässt: Reranking, umgesetzt mit Cross-Encodern oder LLM as Judge, und HyDE – Hypothetical Document Embeddings. Beide Ansätze nutzen die Stärken großer Sprachmodelle, um die Auswahl relevanter Passagen zu verfeinern und so die Antwortqualität zu erhöhen.
In diesem dritten Beitrag richten wir den Blick auf zwei weitere Wege, das Retrieval gezielt zu optimieren: Knowledge Graphs und wie sie im GraphRAG eingesetzt werden, sowie Embedding-Tuning, also die Anpassung von Embedding-Modellen an spezifische Domänen. Beide Methoden verbessern die Art und Weise, wie Wissen im Retrieval abgebildet und genutzt wird, und tragen dazu bei, RAG-Systeme noch präziser und robuster zu machen.
Inhaltsverzeichnis
Knowledge Graphs
Wenn wir Inhalte so organisieren wollen, dass die Suche schnell, zielgenau und erklärbar wird, sind Knowledge Graphs eine der wirkungsvollsten Möglichkeiten.
Ein Knowledge Graph verknüpft Daten als Entitäten und ihre Beziehungen – also als Knoten und Kanten mit Bedeutung. Statt isolierter Dokumente entsteht ein Netzwerk aus Fakten und Verbindungen.
In einem solchen Graphen (siehe Abbildung 1) stehen die Knoten für zentrale Entitäten: Personen, Orte, Organisationen, Konzepte oder Ereignisse – also die Dinge, über die wir etwas wissen wollen.
Die Kanten beschreiben die Beziehungen zwischen diesen Entitäten: Eine Person arbeitet_für eine Firma, ein Kapitel ist_Teil_von einem Buch, ein Urteil hat_Datum. Jede Kante hat eine Bezeichnung, die angibt, welche Art von Beziehung zwischen den Entitäten besteht.
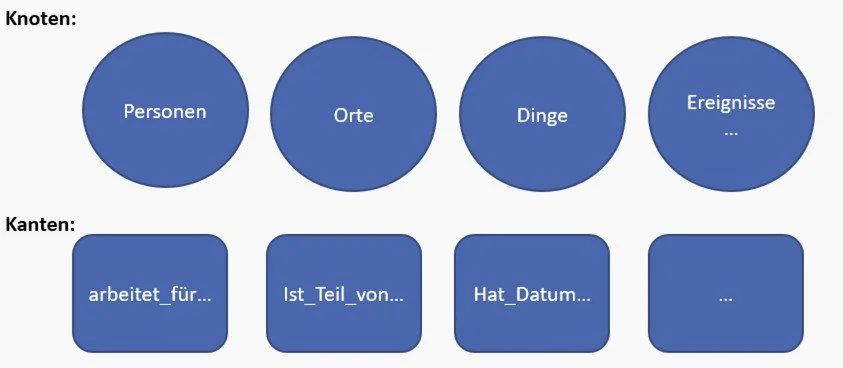
Damit wird Wissen nicht mehr nur gesammelt, sondern strukturiert miteinander vernetzt. So lassen sich nicht nur einzelne Begriffe identifizieren, sondern auch ihre Beziehungen verstehen – etwa, wer mit wem arbeitet, welche Elemente zusammengehören oder welche Ereignisse miteinander verbunden sind.
Gerade dieses Zusammenspiel aus Knoten und Kanten macht den Knowledge Graph so wertvoll besonders für RAG-Systeme, in denen wir gezielt entlang von Beziehungen suchen können. Dadurch lassen sich relevantere Passagen finden und vollständigere Antworten generieren.
Abbildung 2 zeigt den Unterschied zwischen einer tabellarischen und einer Graph-Representation.
Links sehen wir die tabellarische Darstellung: Zwei Zeilen beschreiben, dass John Smith mit Lucy Smith verheiratet ist – und umgekehrt. Das ist zwar verständlich, erfordert aber zwei Einträge für dieselbe Beziehung. In größeren Datensätzen führt das schnell zu Redundanzen und dazu, dass Informationen aus mehreren Tabellen oder Zeilen erst zusammengeführt werden müssen.
Rechts dagegen die Graph-Darstellung: Zwei Knoten (John, Lucy) und zwei Kanten vom Typ married_to, weil die Beziehung wechselseitig ist. Der Vorteil liegt auf der Hand: Beziehungen sind hier eigene Elemente im Modell. Man kann ihnen Schritt für Schritt folgen – etwa mit einer Abfrage wie: „Zeig mir alle Personen, die mit John verheiratet sind.“
Kommt später neues Wissen hinzu – etwa über Kinder, Wohnorte oder Arbeitgeber, lässt sich der Graph einfach erweitern, indem neue Knoten und Kanten ergänzt werden. Das funktioniert, ohne das Schema anzupassen oder komplexe Joins zu bauen.
Kurz gesagt: Eine Tabelle eignet sich gut für Listen und Attribute, ein Graph dagegen, wenn Beziehungen und Verknüpfungspfade im Mittelpunkt stehen. Und genau das ist in RAG-Systemen entscheidend, um zusammenhängende Belege gezielt zu finden.

GraphRAG
Knowledge Graphs können gezielt im sogenannten GraphRAG eingesetzt werden. Dabei werden die Graph-Repräsentationen genutzt, um Dokumente im RAG-Prozess gezielter und vollständiger abzurufen.
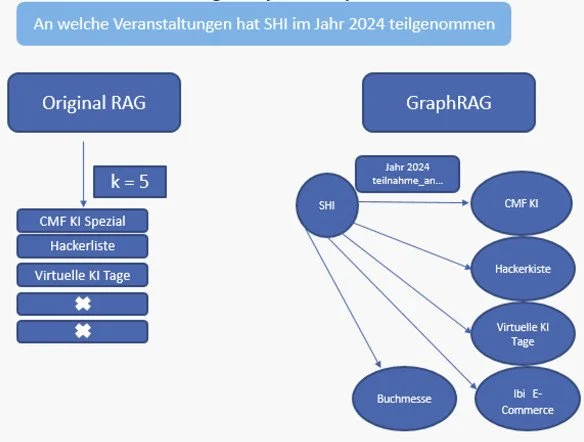
Abbildung 3 veranschaulicht den Unterschied zwischen dem klassischen RAG-Verfahren und GraphRAG.
Links sehen wir das klassische RAG: Es liefert die Top-k semantisch ähnlichsten Passagen. Das ist schnell, stößt aber an Grenzen.
Wenn beispielsweise SHI an mehreren Veranstaltungen teilgenommen hat, liegen diese Informationen oft über viele Dokumente verteilt. Gibt es kein einzelnes Dokument, das alle Events des Jahres 2024 gemeinsam aufführt, kann klassisches RAG kein „Alles-in-einem“-Ergebnis liefern – die Trefferliste bleibt lückenhaft oder unsortiert.
Rechts zeigt sich die Variante GraphRAG:
Zuerst wird der Startknoten „SHI“ bestimmt.
Dann erfolgt eine Beziehungssuche im Graphen: Vom SHI-Knoten aus folgen wir der Kante teilnahme_an und filtern nach Jahr = 2024. Auf diese Weise erhalten wir alle passenden Event-Knoten – auch dann, wenn es kein einzelnes Sammeldokument gibt, das sie alle enthält.
So entsteht ein vollständiges, strukturiertes Ergebnis: CMF KI, Hackerkiste, Virtuelle KI-Tage, Buchmesse, E-Commerce. Mit GraphRAG nutzen wir also Beziehungen statt reiner Textähnlichkeit – und erreichen dadurch vollständigere, geordnete Ergebnisse sowie präzisere Antworten im RAG-System, insbesondere bei Fragen, deren Informationen über mehrere Dokumente verteilt sind.
Embedding-Tuning
Das Embedding-Tuning stellt einen weiteren Ansatz dar, um die Qualität des Retrievals in RAG-Systemen zu verbessern. Dabei wird ein bestehendes Embedding-Modell finetuned, damit es die Fachsprache und Begriffe einer Domäne besser versteht.
In vielen Domänen stoßen Basis-Modelle an ihre Grenzen: Abkürzungen, Produktnamen oder interne IDs werden oft uneinheitlich dargestellt oder falsch interpretiert.
Das Finetuning eines Embedding-Modells wirkt sich direkt auf RAG aus: Das Retrieval liefert relevantere Treffer und eine bessere Reihenfolge der Ergebnisse, sodass das LLM mit präziserem Kontext arbeiten kann.
Embedding-Tuning kommt dann zum Einsatz, wenn andere in dieser Blogserie vorgestellte Maßnahmen, wie hybride Suche, Reranking, GraphRAG oder HyDE – noch nicht ausreichen, etwa bei sehr spezifischen Begriffen oder spezialisierten Dokumentarten. Das Verfahren ist deutlich aufwendiger, da es hochwertige Trainingsdaten benötigt, die die sprachlichen und semantischen Strukturen der Ziel-Domäne repräsentieren. Zudem ist es rechenintensiv und erfordert in der Regel den Einsatz von GPUs, um das Finetuning effizient durchführen zu können.
Ein häufig verwendetes Format von Trainingsdaten ist ein positives Paar – bestehend aus einer Query und der dazu passenden Passage.
Darüber hinaus kommen Triplets zum Einsatz: eine Query, eine positive Passage und eine negative Passage. Auf diese Weise lernt das Modell explizit, relevante und irrelevante Inhalte voneinander zu unterscheiden.
Ein weiteres Format sind pairwise Präferenzen. Hier wird dem Modell für dieselbe Query gezeigt, dass Passage A besser zur Anfrage passt als Passage B. Es handelt sich also um Vergleiche zwischen zwei Kandidaten, nicht um absolute Bewertungen.
Je nach Trainingsziel und gewählter Loss-Funktion kommen unterschiedliche Datenformate zum Einsatz. Die Loss-Funktion legt fest, wie das Modell aus den Trainingsdaten lernt, also ob es einzelne Paare bewertet, Unterschiede zwischen zwei Passagen vergleicht oder ganze Rangfolgen optimiert. Entscheidend ist: Mit diesen Formaten zeigen wir dem Modell ganz konkret, welche Inhalte zusammengehören und welche nicht. Das ist die Grundlage dafür, dass das getunte Embedding-Modell im Retrieval später relevantere und verlässlichere Treffer liefert.
Fazit und Ausblick
In dieser dreiteiligen Blogserie haben wir zentrale Strategien vorgestellt, um das Retrieval in RAG-Systemen gezielt zu verbessern.
Im ersten Teil standen die hybride Suche und asymmetrische Embedding-Modelle im Fokus: Die hybride Suche kombiniert die lexikalische und die semantische Stärke, während asymmetrische Embedding-Modelle das Prinzip kurze Query – langes Dokument nutzen, um die semantische Relevanzbewertung zu optimieren.
Der zweite Beitrag widmete sich dem Reranking, umgesetzt mit Cross-Encodern oder LLM as Judge, sowie HyDE – Hypothetical Document Embeddings. Beide Methoden nutzen die Leistungsfähigkeit großer Sprachmodelle, um relevante Passagen genauer zu identifizieren und das Retrieval gezielt zu verfeinern.
Im dritten Teil schließlich haben wir gezeigt, wie sich mit Knowledge Graphs und GraphRAG Beziehungen zwischen Informationen abbilden lassen und wie ein Finetuning des Embedding-Modells dafür sorgt, dass Embeddings die sprachlichen Strukturen spezialisierter Fachdomänen besser erfassen. Gemeinsam machen diese Ansätze deutlich, dass Retrieval heute weit über reine Ähnlichkeitsmessung hinausgeht. Durch die Verbindung von semantischer Repräsentation, strukturiertem Wissen und domänenspezifischer Anpassung entstehen RAG-Systeme, die relevantere und konsistentere Ergebnisse liefern.


