

Apache Solr hat sich seit seiner Gründung stetig weiterentwickelt und mit jeder Version leistungsstärkere Funktionen zur Suchoptimierung hinzugefügt. Einer der zentralen Ansätze in diesem Bereich ist die neuronale Suche mit Dense Vector Search. Dabei wird nicht nur nach Schlüsselwörtern, sondern nach semantischen Bedeutungen gesucht, mithilfe von speziell trainierten Modellen aus dem Bereich des Deep und Machine Learnings, die Text in numerische Repräsentationen umwandeln. Neben der Vektorsuche bietet Solr weitere intelligente Features, die Machine Learning nutzen, um die Qualität der Suchergebnisse zu optimieren. Diese Features existieren bereits in älteren Versionen von Apache Solr, doch mit den Fortschritten in der künstlichen Intelligenz gewinnen sie zunehmend an Bedeutung. Da Machine Learning eine immer wichtigere Rolle bei der Optimierung und Verbesserung von Suchergebnissen spielt, werden auch diese Funktionen kontinuierlich weiterentwickelt.
In diesem Blogbeitrag werfen wir einen genaueren Blick auf drei Machine Learning-gestützte Komponenten in Apache Solr.
Zunächst betrachten wir Learning to Rank, eine Methode zur Relevanzoptimierung, die durch trainierte Modelle das Ranking der Suchergebnisse verbessert. Anschließend gehen wir auf die Klassifikation ein, mit der Dokumente mithilfe von Machine Learning intelligent in verschiedene Klassen eingeteilt werden können. Schließlich werfen wir einen Blick auf Clustering, das eine automatische Gruppierung ähnlicher Dokumente ermöglicht.
Wenn Sie mehr über die neuronale Suche mit Dense Vector Search erfahren möchten, lesen Sie unseren vorherigen Blogbeitrag mit dem Titel: Neuronale Suche mit Dense Vector Search in Apache Solr.
Inhaltsverzeichnis
1. Learning to Rank (LTR)
LTR ist ein Modul in Apache Solr, das mit Version 6.4 integriert wurde. Es ermöglicht Machine Learning-Rankingmodelle in den Suchprozess zu integrieren. Solr bietet bereits Standard-Rankingalgorithmen wie TF-IDF und BM25, die bei der Berechnung der Relevanz von Suchergebnissen helfen.
TF-IDF (Term Frequency – Inverse Document Frequency) bewertet, wie wichtig ein Begriff innerhalb eines Dokuments ist. Dabei wird berücksichtigt, wie oft der Begriff im Dokument vorkommt (Term Frequency) und wie selten er in allen Dokumenten des Index vorkommt (Inverse Document Frequency). Begriffe, die häufig in einem Dokument erscheinen, aber insgesamt selten im gesamten Index vorkommen, erhalten eine höhere Gewichtung.
BM25 ist eine Weiterentwicklung von TF-IDF, die eine genauere Relevanzbewertung ermöglicht. Neben der Häufigkeit eines Begriffs im Dokument und seiner Seltenheit im Index, berücksichtigt BM25 zusätzlich die Länge des Dokuments. Außerdem wird der Einfluss sehr häufig vorkommender Begriffe begrenzt, sodass diese ab einer bestimmten Häufigkeit die Relevanz nicht weiter unnötig erhöhen. Dadurch liefert BM25 oft präzisere Suchergebnisse als TF-IDF. Beide Ansätze sind zwar effizient, können sich aber nicht dynamisch an verschiedene Suchanfragen oder Nutzerabsichten anpassen.
Um das Ranking weiter zu verbessern, bietet LTR die Möglichkeit, Suchergebnisse mit trainierten Machine Learning-Modellen gezielt zu optimieren. Das Kernprinzip von der Ranking-Optimierung besteht darin, eine erste Menge von Suchergebnissen zu ermitteln und anschließend eine Re-Ranking-Phase durchzuführen. In dieser Phase werden die Top-N-Dokumente mithilfe eines trainierten Modells neu bewertet, um die relevantesten Ergebnisse weiter nach oben zu sortieren (siehe Abbildung 1: Re-Ranking mit LTR).
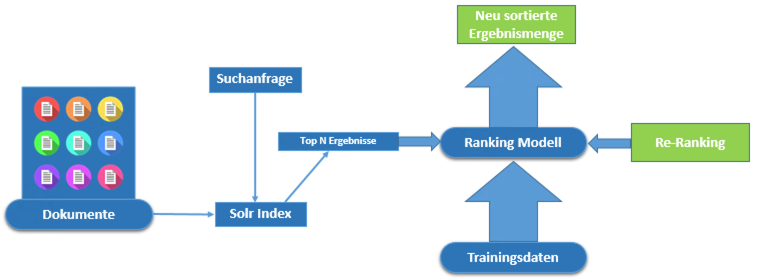
Ein Learning-to-Rank-Modell wird zunächst außerhalb von Solr trainiert und anschließend in Solr hochgeladen. Das trainierte Modell bewertet im Re-Ranking-Prozess die Suchergebnisse erneut, um die relevantesten Dokumente präziser zu gewichten und ihre Reihenfolge zu optimieren.
Um ein Machine Learning-Modell für LTR zu trainieren, sind geeignete Trainingsdaten erforderlich. Diese Daten geben dem Modell vor, wie es die verschiedenen Features gewichten soll, um eine optimale Relevanzbewertung zu erreichen.
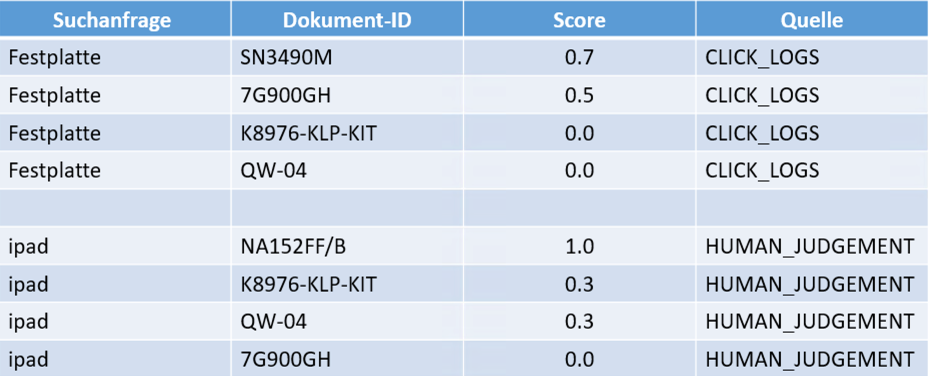
Wie in Abbildung 2 dargestellt, bestehen die Trainingsdaten im Fall von LTR typischerweise aus einer Sammlung von Suchanfragen, den dazugehörigen Dokumenten und deren idealen Rankings oder Relevanzwerten. Die Suchanfrage ist der eingegebene Begriff, nach dem gesucht wurde, und der Relevanzwert (Score) ist die Zahl, die angibt, wie relevant das Dokument für die gegebene Suchanfrage ist.
Die Dokumente können aus unterschiedlichen Quellen stammen (Quelle), und ihre Relevanz für eine Suchanfrage kann auf verschiedene Weise bewertet werden. Für die Relevanzbewertung spielen insbesondere Nutzerinteraktionen und Menschenannotationen eine zentrale Rolle. Bei Nutzerinteraktionen werden Aktionen der Nutzer, wie Klicks, oder andere Interaktionen mit den Suchergebnissen, erfasst. Diese Daten dienen als Indikatoren für die Relevanz eines Dokuments. Ein einfaches Beispiel: Für jede Suchanfrage wird gezählt, wie oft auf ein bestimmtes Dokument geklickt wurde. Je häufiger ein Dokument angeklickt wird, desto höher könnte sein Relevanzwert sein.
Bei Menschenannotationen bewerten Personen die Relevanz von Dokumenten für bestimmte Suchanfragen. Dies kann durch Expertenteams oder über Crowdsourcing-Plattformen erfolgen, auf denen Teilnehmer die Dokumente mit Labels wie beispielsweise „Perfekt“, „Gut“, „Fair“ oder „Nicht relevant“ kennzeichnen. Diese qualitativen Bewertungen werden anschließend in numerische Relevanzwerte umgewandelt, die als Trainingsdaten für das Modell dienen.
Durch das Training mit diesen Daten lernt das Modell, welche Dokumente für eine Suchanfrage besonders relevant sind und entsprechend höher gerankt werden sollten, um die Suchqualität und Nutzerzufriedenheit zu maximieren.
2. Klassifikation
Nachdem wir nun LTR betrachtet haben, wenden wir uns der Klassifikation zu. Klassifikation bedeutet, mithilfe von Beispieldaten mit bekannten Kategorien zu bestimmen, zu welcher Kategorie eine neue Beobachtung gehört. Ein klassisches Beispiel dafür ist ein E-Mail-Spamfilter, der E-Mails als „Spam“ oder „kein Spam“ einordnet. Ebenso wird die Dokumentklassifikation genutzt, um Dokumente automatisch Themenbereichen wie z.B. „Rechnung“ oder „Vertrag“ zuzuweisen.
Normalerweise benötigt man für die Klassifikation ein vortrainiertes Modell, um Dokumente einer Kategorie zuzuordnen. Das würde bedeuten, dass ein Modell für die Klassifikation in Solr zunächst außerhalb von Solr trainiert und anschließend in das System integriert werden müsste. Apache Solr geht hier jedoch einen anderen Weg: Es nutzt die bereits indexierten Dokumente mit ihren vorhandenen Kategorien als Trainingsdaten. Dadurch entfällt der Aufwand, ein externes Modell zu trainieren oder zu importieren. Neue Dokumente können automatisch klassifiziert werden – basierend auf den Informationen im Index.
Die Klassifikation wurde mit Version 6.3 in Apache Solr eingeführt und kann auf zwei Arten durchgeführt werden:
- Während der Indexierung: Ein Update Request Processor wird verwendet, um neuen Dokumenten automatisch eine Klasse zuzuweisen, basierend auf den bereits im Index vorhandenen Daten.
- Während der Abfrage: Die Klassifikation erfolgt zur Laufzeit, ähnlich wie beim More Like This-Feature.
Besonders interessant ist die Klassifikation während der Indexierung, da der Update Processor die Dokumente analysiert, klassifiziert, ein Klassenfeld hinzufügt und sie dann für weitere Verarbeitungsschritte bereitstellt.
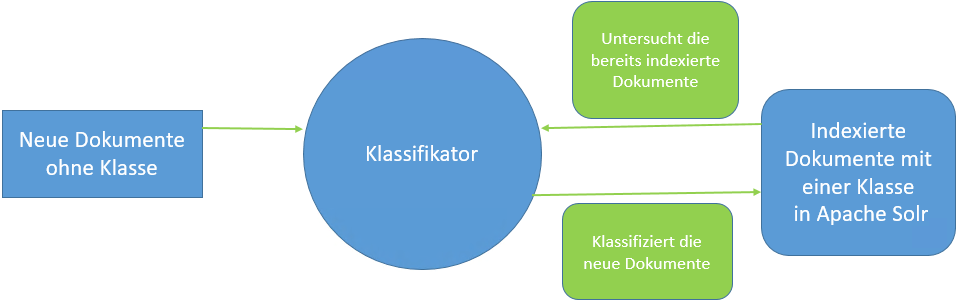
In Abbildung 3 wird veranschaulicht, wie die Klassifikation in Apache Solr funktioniert. Bereits indexierte Dokumente sind bestimmten Klassen zugeordnet. Sie können zum Beispiel Gesetze wie „Politikgesetz“ oder „Verkehrsgesetz“ sein. Nun sollen neue Dokumente indexiert werden, die noch keiner Klasse zugewiesen sind. Hier kommt die Klassifikation ins Spiel: Wenn ein neues Dokument hinzugefügt wird, analysiert der Klassifikator die bereits indexierten Dokumente und weist dem neuen Dokument automatisch die passende Klasse zu.
Apache Solr bietet zwei Algorithmen für die Klassifikation an: den k-Nearest-Neighbor (KNN)-Klassifikator und den Naive-Bayes-Klassifikator (siehe Abbildung 4: Klassifikatoren in Solr). Der KNN-Klassifikator vergleicht neue Dokumente mit den k ähnlichsten bereits klassifizierten Dokumenten im Index. Anschließend zählt er, welche Kategorien in diesen Top-k-Ergebnissen am häufigsten vorkommen, und weist dem neuen Dokument die Kategorie mit der höchsten Häufigkeit zu. Der Naive-Bayes-Klassifikator basiert auf Wahrscheinlichkeitsberechnungen. Er bestimmt, wie wahrscheinlich es ist, dass ein Dokument zu einer bestimmten Klasse gehört, basierend auf den Wörtern, die in seinem Text enthalten sind.

Die Klassifikation in Apache Solr kann direkt in bestehende Such- und Indexierungsarchitekturen integriert werden. Dadurch entfällt die Notwendigkeit, externe Modelle zu trainieren oder zusätzliche Klassifikationsansätze zu implementieren. Neue Dokumente können automatisch und effizient klassifiziert werden, was die Suche strukturierter und relevanter macht. Es spart Zeit und reduziert den manuellen Aufwand für die Organisation und Pflege von Datenbeständen.
3. Clustering
Clustering ist ein Verfahren zur automatischen Gruppierung ähnlicher Dokumente und wurde bereits mit Version 4 in Apache Solr eingeführt. Es wird als Modul bereitgestellt und kann als Suchkomponente in Solr konfiguriert werden. Das Clustering-Modul analysiert die Suchergebnisse und unterteilt sie in dynamisch erstellte Gruppen (Cluster). Dabei erhalten diese Gruppen menschlich lesbare Labels, die das Verständnis der Ergebnisse erleichtern.
Ein entscheidender Vorteil dieses Verfahrens ist das sogenannte „on-line Clustering“: Die Cluster werden bei jeder Abfrage neu gebildet, basierend auf den Treffern der aktuellen Suchanfrage. Dadurch ähnelt Clustering in gewisser Weise der Facettierung, jedoch mit dem Unterschied, dass keine festen Kategorien oder Felder vorab definiert sein müssen. Stattdessen erkennt das Clustering-Plugin automatisch Muster in den Daten und bildet Gruppen, die den Nutzer bei der Analyse der Suchergebnisse unterstützen.
Diese Technik eignet sich besonders für explorative Suchanfragen, bei denen die Struktur der Daten erst während der Suche deutlich wird. Sie kann auch als Ergänzung oder Alternative zu Result Grouping dienen, um weitere relevante Dokumente jenseits der ersten Suchtreffer zu entdecken.
Clustering in Apache Solr erfolgt in drei Schritten: Zunächst analysiert der Algorithmus alle Dokumente und sucht nach Gemeinsamkeiten, etwa anhand von Begriffen, Wortkombinationen oder ihrer Position im Index. Anschließend wird die Ähnlichkeit zwischen den Dokumenten berechnet. Schließlich werden ähnliche Dokumente in Gruppen zusammengefasst. Die Art der Gruppierung hängt vom verwendeten Algorithmus ab, beispielsweise K-Means, hierarchisches Clustering oder DBSCAN.
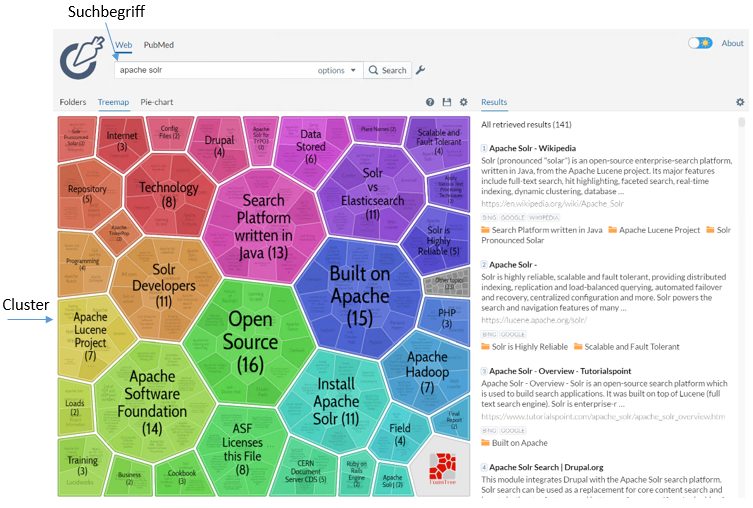
In Abbildung 5 sehen wir ein Beispiel für Clustering, basierend auf einer Suche nach „Apache Solr“. Die Visualisierung zeigt, wie Suchergebnisse automatisch in sinnvolle Gruppen unterteilt werden. Der Algorithmus hat viele Gruppen – wie „Open Source“, „Search Platform written in Java“, „Apache Hadoop“ usw. eigenständig erstellt, ohne auf externe Informationen oder vorab definierte Kategorien zurückzugreifen.
Das Ziel von Clustering in Solr ist es, Nutzern zu helfen, die Suchergebnisse besser zu analysieren und die Suche gezielt zu verfeinern. Im Gegensatz zu Facetten, die auf festen Feldwerten basieren, erkennt das Clustering automatisch Muster in den Ergebnissen und erstellt Gruppen, die den Inhalt der Dokumente widerspiegeln. Da Clustering die Gruppen dynamisch und ohne vorher festgelegte Kategorien generiert, eignet es sich besonders für explorative Suchanfragen, bei denen nicht von vornherein klar ist, welche Facetten sinnvoll sind.
Fazit
Apache Solr bietet mit Learning to Rank, Klassifikation und Clustering leistungsstarke Machine Learning-gestützte Funktionen. Sie tragen dazu bei die Relevanz der Suchergebnisse weiter zu optimieren. Während Learning to Rank das Ranking mithilfe trainierter Modelle verbessert, ermöglicht die Klassifikation eine automatisierte Kategorisierung von Dokumenten. Das Clustering-Modul gruppiert Suchergebnisse dynamisch, sodass Nutzer die Inhalte gezielter durchsuchen können. Diese Machine Learning Features machen Solr zu einer intelligenten und flexiblen Suchlösung, die sich sowohl für klassische Informationssuche als auch für explorative und personalisierte Suchanwendungen eignet.
Ausblick
Die Entwicklungen im Bereich künstlicher Intelligenz eröffnen neue Möglichkeiten für die Suchtechnologie. Machine Learning-Rankingmodelle können leistungsfähigere Suchmethoden ermöglichen und eine noch präzisere Anpassung der Suchergebnisse an die Nutzerbedürfnisse gewährleisten.
In diesem Blogbeitrag haben wir drei Machine Learning-Komponenten in Apache Solr analysiert (LTR, Klassifikation und Clustering). Die semantische Suche, die wir bereits am Anfang erwähnt haben, zählt ebenfalls zu den wichtigsten Deep- und Machine Learning Features von Apache Solr. Ein weiterer spannender Bereich ist die hybride Suche, bei der klassische lexikalische Suchverfahren mit semantischer Vektorsuche kombiniert werden, um die Stärken beider Methoden zu vereinen. In Zukunft ist zu erwarten, dass Solr weitere Machine Learning-gestützte Lösungen integriert, um noch mehr Möglichkeiten für leistungsfähige Suchtechnologien bereitzustellen.


