

In jedem Projekt, bei dem es um die Durchsuchbarkeit von Daten geht, ist die Anbindung der Datenquelle(n) eine der Herausforderungen. Dabei ist es unerheblich ob es sich um die klassische Enterprise Search handelt, oder um suchgetriebene Analytics Projekte. In diesem Blog werden wir aufzeigen wie man dieser Herausforderung bei Apache Solr begegnet.
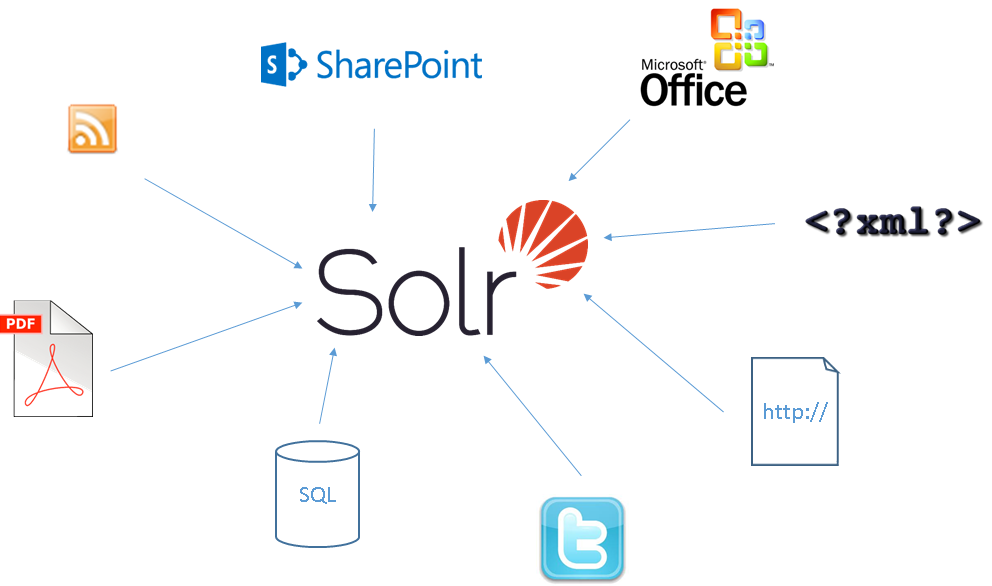
Eine Typische Erwartungshaltung bei Apache Solr ist, dass Solr direkt jegliche Datenquelle anbinden kann. Apache Solr ist jedoch eine Suchmaschine und kein Ingestion-Framework. Viele der gängigen Formate kann Apache Solr zwar out of the box verarbeiten, jedoch nicht alle.
Da Apache Solr nicht alle Datenquellen direkt unterstützt bleibt nur auf Hilfsmittel zurückzugreifen. Ein Hilfsmittel ist die Programmierung einer eigenen Komponente, die Daten von einem System ausliest und an Solr schickt. Hierbei hat man dann zwar die größtmögliche Flexibilität, jedoch muss man auch die komplette Funktionalität implementieren und vor allem pflegen. Eine Alternative zu Custom Code ist Nutzung eines der vielen Ingestion-Frameworks. Hier gibt es eine große Auswahl an Produkten mit den unterschiedlichsten Möglichkeiten.
Betrachten wir doch mal ein paar konkrete Beispiele bzw. Datenquellen und schauen wie diese in Apache Solr indexiert werden können.
Dateisystem
Im Dateisystem liegen in der Regel binäre Dateien, wie beispielsweise Word, PDF, Excel, Bilder, Zips und vieles mehr. Dank der Integration von Apache Tika kann Solr die unterschiedlichsten Formate erkennen und verarbeiten. Entweder man sendet diese Dateien direkt an Solr oder konfiguriert den DataImportHandler (DIH), der dann selbstständig das Dateisystem durchsucht und das „Schicken“ übernimmt. Apache Solr unterstützt hierbei jedoch nur das lokale Dateisystem. Andere Dateisysteme, wie beispielsweise FTP, S3, HDFS oder DropBox werden nicht unterstützt. Das Connector Framework von Lucidworks Fusion oder Apache Nifi können die Aufgabe des Dateisystems Crawlen übernehmen.
Datenbank
Ähnlich sieht es bei Datenbanken aus. Apache Solr bietet mittels des DIH die Möglichkeit Datenbanken via JDBC abzufragen und so die Daten zu indexieren. Datenbanken wie MongoDb oder Couchbase kann Solr nicht direkt indexieren. Auch hier muss auf Hilfsmittel wie Apache Nifi oder Lucidworks Fusion zurückgegriffen werden.
Repositories
Repositories, wie beispielsweise JIRA, Subversion, Sharepoint, Alfresco oder Salesforce, kann Apache Solr gar nicht direkt indexieren. ConnectorFrameworks, wie das von Lucidworks Fusion, können diese Repositories samt der Berechtigungen indexieren. Berechtigungen sind vor allem im Umfeld der Enterprise Search sehr wichtig. Gleiches gilt für Social Media Daten, wie beispielsweise Twitter Feeds oder Facebook Posts. Auch hier ist Apache Solr darauf angewiesen, dass diese Dokumente von außen gepusht werden.
Web Content
Eine weitere wichtige Datenquelle ist das Internet. Apache Solr kann auch hier wieder nur rudimentär mittels des DIH Daten indexieren. Apache Solr beinhaltet keine Web Crawling Komponente und kann nur strukturierte Informationen, wie beispielsweise Feeds indexieren. Für den unstrukturierten Web Content muss auf Crawler, wie beispielsweise Apache Nutch, zurückgegriffen werden.
Fazit
Apache Solr ist eine Suchmaschine. Die Kernaufgabe ist in den bereits indexierten Daten die richtigen Informationen bzw. Dokumente zu finden. Bei der Anbindung der Datenquellen ist Apache Solr oft auf Hilfe von außen angewiesen. Es gibt hier zum Glück genug kommerzielle und auch freie Produkte die eine Solr Schnittstelle haben und somit die Daten anliefern können.
Die oben genannten Hilfsmittel, wie Lucidworks Fusion, Apache Nifi oder Apache Nutch, stellt keine vollständige Liste der Möglichkeiten dar. In unseren Projekten nutzen wir je nach Situation und Datenquelle auch andere Frameworks.
Es gibt auch Projekte, da hilft keines dieser Frameworks bzw. sie sind zu komplex, zu schwerfällig oder die Kosten stehen nicht im Verhältnis zu dem benötigten Nutzen. In solchen Projekten entwickeln wir dann speziellen Code der die Aufgabe übernimmt.
Haben Sie Fragen zu der Anbindung Ihrer Daten an Solr oder benötigen Sie Unterstützung können Sie sich gern unverbindlich mit uns in Verbindung setzen.


