

How NiFi fits into your needs; Part 2
In Part 2 we will look at the extension points NiFi is providing, especially the most important one the ‘Processor Extension Point’.
NiFi comes with ~ 225 default processors, but even with this high number there are always situations where a custom solution might not only work better but is absolutely necessary.
But before we are starting the deep dive in processor customization, we will have a look at NiFi’s architecture first.
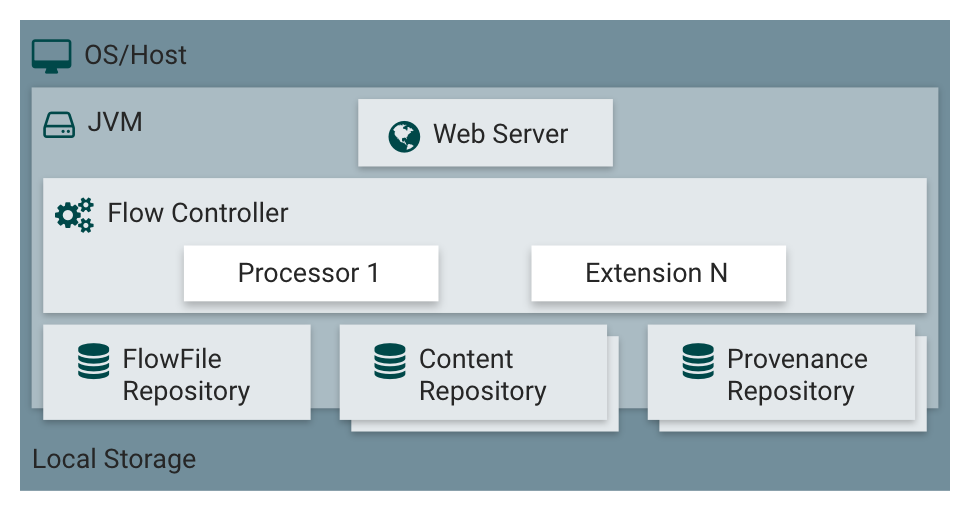
Figure 1 Basic NiFi Architecture
The NiFi application executes within a JVM on several operating system (preferably this is a Linux derivate). The NiFi documentation describes each tier in more detail:
Web Server
The purpose of the web server is to host NiFi’s HTTP-based command and control API.
Flow Controller
The flow controller is the brain of the operation. It provides threads for extensions to run on, and manages the schedule of when extensions receive resources to execute.
Extensions
There are various types of NiFi extensions which are described in NiFi’s developer guide. The key point is that extensions operate and execute within the JVM.
FlowFile Repository
The FlowFile Repository is where NiFi keeps track of the state of what it knows about any given FlowFile. The implementation of the repository is pluggable. The default approach is a persistent write-ahead log located on a specified disk partition.
Content Repository
The Content Repository is where the actual content of a given FlowFile lives (the bits and bytes).
The implementation of the repository is pluggable. The default approach is a fairly simple mechanism which stores blocks of data in the file system. More than one file system storage location can be specified to distribute the physical content while working with one logical volume.
Provenance Repository
The Provenance Repository is where all provenance event data is stored. The repository construct is pluggable with the default implementation being to use one or more physical disk volumes. You can search the provenance repo for all occurring events a workflow is creating while running.
Implementing a custom processor
In Figure 1 you have seen the central extension point for NiFi processors. There is no limitation in the number/amount of custom processors!
Let’s start to get a better understanding on custom processors by implementing our own LogCustomMessage processor. This processor will use the underlying Logger-Framework NiFi is using to write configured messages within the configured Log-Level. NiFi comes with a default LogAttributes processor, but as the name obviously reveal, this processor logs the attributes of an incoming FlowFile thus producing a lot of noise around the relevant log message itself.
So let’s get started implementing our own LogCustomMessage processor!
First, we have to extend NiFi’s AbstractProcessor. An AbstractProcessor is the base class for almost all Processor implementations. The AbstractProcessor class provides a significant amount of functionality which makes the task of developing a Processor much easier and more convenient:
@EventDriven@SideEffectFree@SupportsBatching@Tags({ "messages", "logging" }) @InputRequirement(Requirement.INPUT_REQUIRED) public class LogCustomMessage extends AbstractProcessor { ... }
Listing 1: Extending the AbstractProcessor class
As you can see, a custom processor can be configured with annotations to behave in a certain way.
For example, the @InputRequirement annotation is responsible to determine whether an ingoing connection is required or even restricted. For the above listing an input connection is required otherwise the processor won’t start!
The next step deals with the configuration items that can be set by the user via the web UI when the custom processor is used in a DataFlow.
Here we have to implement the relationships (the types of outgoing connections) and the property descriptors (the configuration properties of a processor).
You can define as many relationships as you want, but normally three kinds of relations a sufficient:
– REL_SUCCESS: A success relationship where FlowFiles are rooted when everything was processed went correctly.
– REL_FAILURE: A failure relationship where FlowFiles are rooted when something went wrong.
– REL_ORIGINAL: A relationships where you can provide the original/unmodified FlowFile regardless of any success or failure.
For the properties, in case of the LogCustomMessage processor, we define:
– LOG_LEVEL: At what level we want to log the message.
– LOG_MSG: The message to log.
– LOG_NAME: The name of the logger, default is “com.shi.nifi.processors.LogCustomMessage”.
In listing 2 below you can see both implementations for relationships and property descriptors.
We only need one success relationship because the LogCustomMessage processor just acts like an event trigger and therefore no modification on the incoming FlowFile is performed.
...public static final String LOGGER_NAME = "com.shi.nifi.processors.LogCustomMessage";private Set<Relationship> relationships;private List<PropertyDescriptor> supportedDescriptors; public static final Relationship REL_SUCCESS = new Relationship.Builder() .name("success") .description("All FlowFiles are routed to this relationship") .build();
public static final PropertyDescriptor LOG_LEVEL = new PropertyDescriptor.Builder() .name("Log Level") .required(true) .description("The Log Level to use when logging the message") .allowableValues(DebugLevels.values()) .defaultValue("info") .build();
public static final PropertyDescriptor LOG_MSG = new PropertyDescriptor.Builder() .name("Log message") .required(false) .description("The message to log.") .addValidator(StandardValidators.NON_EMPTY_VALIDATOR) .expressionLanguageSupported(true) .build();
public static final PropertyDescriptor LOG_NAME = new PropertyDescriptor.Builder() .name("Logger name") .required(true) .description("The Logger that will be created by the underlying logger impl.Normaly this is 'LoggerFactory.getLogger(SomeClass.getClass())', but we are using a unique string instead. This offers the ability to log into different log files, if you adjust the logback.xml in the nifi conf dir and define a logger with the same name provided with this property.") .defaultValue(LogCustomMessage.LOGGER_NAME) .addValidator(StandardValidators.NON_BLANK_VALIDATOR) .expressionLanguageSupported(true) .build();...
Listing 2: The configuration items of a processor
For all configuration items there are a lot of common properties you can set to control the behaviour of each item. Mostly all properties will adjust the look and feel of the web UI directly, for example the property allowableValues(…) will provide a drop-down menu from which a user can select values from.
A different kind of property is the addValidator(…) method. This property will not change the UI directly, instead it adds the support for input validation and prints out failures if certain input criteria are not met by the user.
So far, we prepared a custom processor with the most important configuration items. Now it’s time for the main task: writing the custom code itself.
NiFi exposes an abstract method called onTrigger(ProcessContext context, ProcessSession session) for this step. This method is called each time an event triggers the processor. Possible events could be:
• A FlowFile enters the processor,
• Scheduling settings of the processor itself,
• A manual start of the processor.
The above method provides two important objects as arguments we should have a look on.
The NiFi development guide describes the two objects in more detail:
ProcessSession
The ProcessSession, often referred to as simply a „session,“ provides a mechanism by which FlowFiles can be created, destroyed, examined, cloned, and transferred to other Processors. Additionally, a ProcessSession provides mechanism for creating modified versions of FlowFiles, by adding or removing attributes, or by modifying the FlowFile’s content. The ProcessSession also exposes a mechanism for emitting Provenance Events that provide for the ability to track the lineage and history of a FlowFile. After operations are performed on one or more FlowFiles, a ProcessSession can be either committed or rolled back.
(Source: https://nifi.apache.org/docs/nifi-docs/html/developer-guide.html#process_session)
ProcessContext
The ProcessContext provides a bridge between a Processor and the framework. It provides information about how the Processor is currently configured and allows the Processor to perform Framework-specific tasks, such as yielding its resources so that the framework will schedule other Processors to run without consuming resources unnecessarily.
(Source: https://nifi.apache.org/docs/nifi-docs/html/developer-guide.html#process_context)
The next listing (listing 3) shows the complete onTrigger(…) method inside the LogCustomMessage processor.
First, we use the ProcessSession object to get the associated FlowFile that triggered the processor. If there is no FlowFile present, we just return because we only want to log events based on FlowFiles.
The next step is to retrieve the configured properties via the ProcessContext object.
First we access main the logger object over the configured LOG_NAME attribute.
After that we looking for the LOG_LEVEL and check whether the returned logger object supports the configured LOG_LEVEL or not.
– If there is no supported LOG_LEVEL active, we just transfer the original FlowFile to the success relationship without logging any event.
– If the configured LOG_LEVEL is enabled, we will log the log message with the supported LOG_LEVEL and transfer the FlowFile to the success relationship after.
This is a simple custom processor, but is shows all the fundamental concepts we need so far building a customized NiFi processor.
I highly recommend a deeper look into NiFi’s developer guide. There you can find additional information, especially how to setup your developer project and how to configure your pom.xml in Maven to compile your code into a NAR file (the kind of container NiFi is expecting).
If you want the complete source code of the LogCustomMessage processor or need any further help in writing are more complex processor, feel free to contact us via Email or over the contact form on this web page!
What comes next?
In general, it is best practice to test your custom code with JUnit!
NiFi provides a customized test framework which helps a lot setting up unit test very quickly.
In the last part of this series we will have a deeper look into NiFi’s test framework and provide some useful information on how to deal with it in more detail…
@Overridepublic void onTrigger(ProcessContext context, ProcessSession session) throws ProcessException { final FlowFile flowFile = session.get(); if (flowFile == null) { return; } // Set the logger based on the configured logger name:this.atomicLogger.set(LoggerFactory.getLogger(context.getProperty(LOG_NAME).evaluateAttributeExpressions(flowFile).getValue().trim()));
final String logLevelValue = DebugLevels .valueOf(context.getProperty(LOG_LEVEL).getValue().toLowerCase());
boolean isLogLevelEnabled = false; switch (logLevel) { case trace: isLogLevelEnabled = this.atomicLogger.get().isTraceEnabled(); break; case debug: isLogLevelEnabled = this.atomicLogger.get().isDebugEnabled(); break; case info: isLogLevelEnabled = this.atomicLogger.get().isInfoEnabled(); break; case warn: isLogLevelEnabled = this.atomicLogger.get().isWarnEnabled(); break; case error: isLogLevelEnabled = this.atomicLogger.get().isErrorEnabled(); break; }
if (!isLogLevelEnabled) { session.transfer(flowFile, REL_SUCCESS); return; }
String outputMessage = context.getProperty(LOG_MSG).evaluateAttributeExpressions(flowFile).getValue(); // Uses optional property to specify logging level switch (logLevel) { case info: this.atomicLogger.get().info(outputMessage); break; case debug: this.atomicLogger.get().debug(outputMessage); break; case warn: this.atomicLogger.get().warn(outputMessage); break; case trace: this.atomicLogger.get().trace(outputMessage); break; case error: this.atomicLogger.get().error(outputMessage); break; default: this.atomicLogger.get().debug(outputMessage); } session.transfer(flowFile, REL_SUCCESS); }
Listing 3: The implementation of the onTrigger(…) method.


