

Der Data Import Handler (DIH) in Solr ist seit v8.6 veraltet (deprecated) und wird ab v9.0 aus Solr entfernt. Er wird zwar als Community Plugin weitergeführt, für einen professionellen Einsatz von Solr wird er aber zunehmend unzureichend sein. Als Ersatz für den nativen DIH bietet sich NiFi an, das ein weiteres Projekt der Apache Software Foundation ist und als Tool zur Indexierung bereits vielfach in Kombination mit Solr eingesetzt wird.
Der Einsatz von NiFi anstelle des DIH zum Datenimport bringt außerdem wichtige Vorteile mit sich. Vor allem bleiben wichtige Ressourcen im Vorfeld der eigentlichen Indexierung bei Solr frei.
Im Folgenden beschreiben wir einen einfachen Workflow mit Daten einer MySQL Datenbank, um einen Eindruck der Funktionalitäten von NiFi für den Datenimport zu vermitteln, und anschließend weitere Vorteile.
Installation und Start
NiFi ist Open Source (Apache Lizenz, Version 2.0) und kann unter Apache NiFi Downloads in der aktuellsten Version heruntergeladen werden.
Entpacken Sie die Zip-Datei und starten Sie NiFi via ./bin/nifi.sh start aus dem Installationsverzeichnis heraus auf Ihrem Zielsystem. Standardmäßig läuft NiFi auf dem Port 8080. Um die NiFi UI zu erreichen, rufen Sie in Ihrem Browser folgende URL auf: http://localhost:8080/nifi
Data Flow
NiFi DataFlows werden durch sogenannte Prozessoren abgebildet. NiFi bietet eine Vielzahl an vorgefertigten Prozessoren für unterschiedliche Aufgaben an (extrahieren, transformieren, routen, querying u.v.m.); man kann zudem auch eigene Prozessoren implementieren.
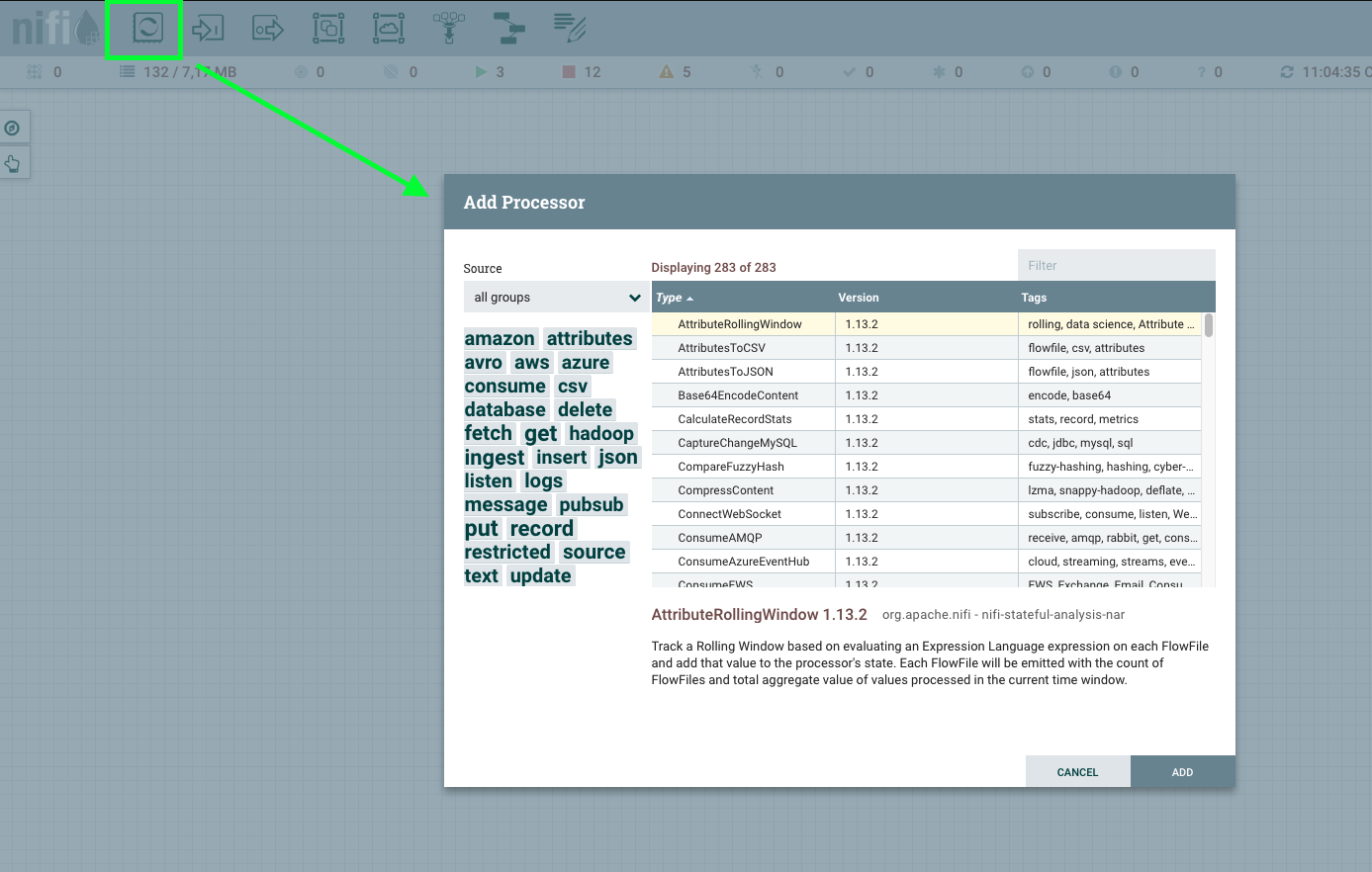
Um zu demonstrieren, wie NiFi zur Indexierung eingesetzt werden kann, erstellen wir einen einfachen DataFlow, der Daten aus einer Datenbank extrahiert und diese Daten anschließend in Solr indexiert. Den einfachen Datenimport von einer MySQL Datenbank nach Solr erstellen Sie in NiFi, indem Sie wie folgt vorgehen:
- Den Prozessor “QueryDatabaseTable” dem Canvas hinzufügen
- Die Properties des Prozessors aufrufen und
- unter “DatabaseConnectionPoolingServices” die Option “DBCPConnectionPool” wählen (Klick auf den ⟶ und danach auf ⚙), um den Controller Service zu konfigurieren:
- Database Connection URL: URL der Datenbank gem. folgender Syntax “jdbc:mysql://host:port/datenbank” also z.B. “jdbc:mysql://localhost:3306/your_db_name”
- Database Driver Class Name: mysql.jdbc.Driver
- Database Driver Location(s): “nifi-1.13.2/lib/mysql-connector-java-8.0.22.jar”
- Database user: Username für die Datenbank
- Password: Passwort für die Datenbank
- DatabaseType: “MySQL” (für dieses Beispiel)
- TableName der Tabelle angeben, die indexiert werden soll
- Columns To Return: Angeben, welche Spalten der angegebenen Tabelle indexiert werden sollen
- unter “DatabaseConnectionPoolingServices” die Option “DBCPConnectionPool” wählen (Klick auf den ⟶ und danach auf ⚙), um den Controller Service zu konfigurieren:
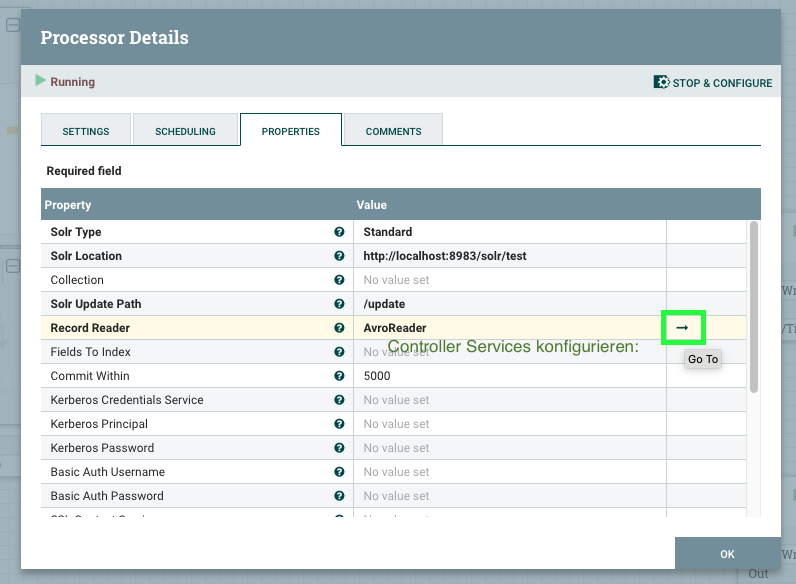
- Einen Prozessor “PutSolrRecord” dem Canvas hinzufügen und wie folgt konfigurieren:
- → Solr Type: Standard
- → Solr Location: http://8983/solr/corename
- → Solr Update Path: /update
- → Record Reader: AvroReader
- Zu den Controller Service Details des AvroReaders wechseln:
- Schema Access Strategy: “Use Embedded Avro Schema”
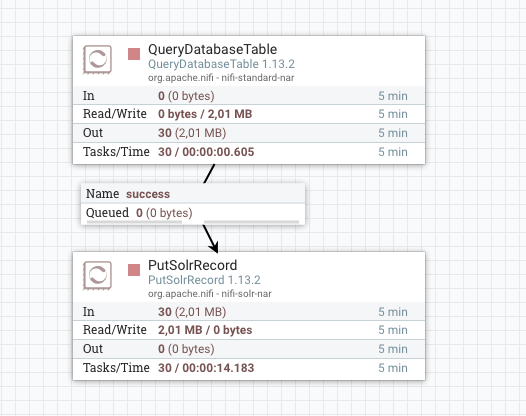
Um die Prozessoren im nächsten Schritt miteinander zu verbinden (create a connection), legen Sie einfach den Pfeil aus der Mitte des QueryDatabaseTable Prozessors auf den PutSolrRecord Prozessor ab.
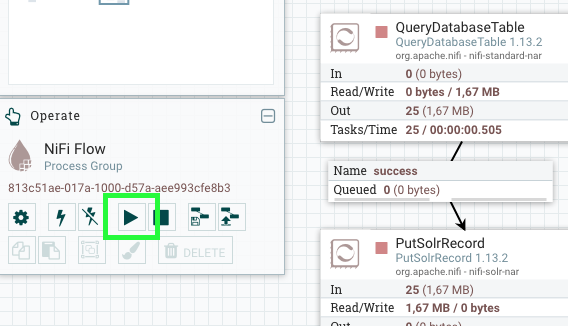
In den Einstellungen des QueryDatabaseTable Prozessors sollten Sie noch via “Scheduling” → ”Run Schedule” ein Intervall für die Aktualisierung festlegen. Andernfalls läuft der Prozess ununterbrochen in Dauerschleife, was weder ressourcenschonend noch sinnvoll ist. Je nach Use Case empfiehlt sich ein Intervall von wenigen Minuten bis hin zu mehreren Stunden.
Nun wählen Sie noch die Prozessoren aus und starten mit dem Play-Button. Die Daten aus der Datenbank werden nun in Solr indexiert.
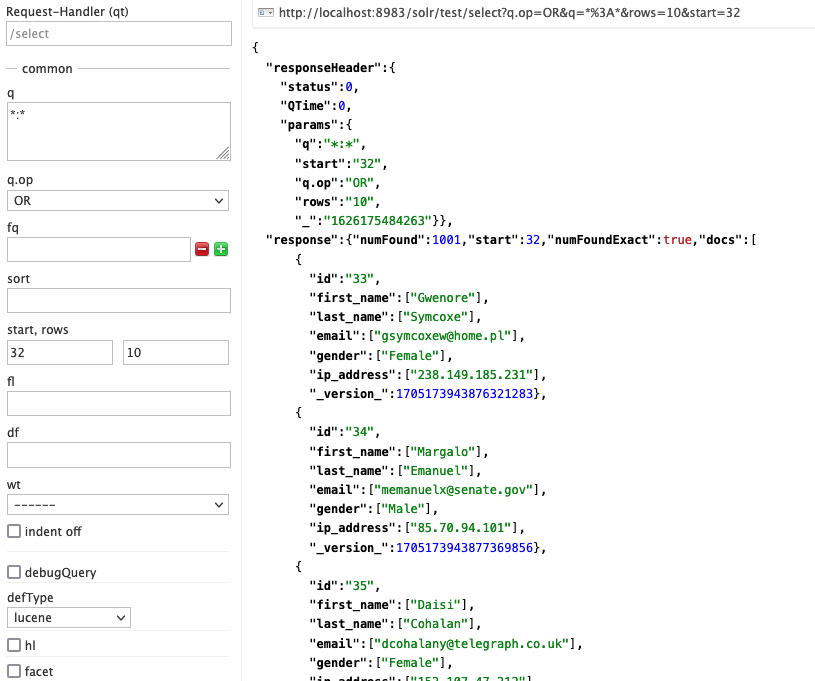
Die Einträge aus der Datenbank finden sich im Anschluss in Solr wieder!
Fazit und weitere Vorteile von NiFi
NiFi bietet eine große Palette an Möglichkeiten, ETL-Pipelines zu erstellen. Dadurch lassen sich auch weitaus komplexere Anwendungsfälle umsetzen als der hier beschriebene. Das gilt nicht nur für die Kombination aus Solr und MySQL, sondern auch für Dienste wie Elasticsearch, Dienste der bekannten Cloud-Anbieter wie AWS / GCP / Azure, andere DBMS, Kafka, Spark, Hive oder Hadoop, um nur einige zu nennen. Darüber hinaus werden alle Dateiformate und auch unstrukturierte Datenformate unterstützt. NiFi ist zudem hochskalierbar (falls die notwendige Hardware zur Verfügung steht), so dass auch Datendurchsatzraten von mehreren Terabytes pro Tag kein Problem sind.
Da wichtige Ressourcen im Vorfeld der eigentlichen Indexierung bei Solr frei bleiben, können gewisse Prozesse parallel ablaufen (DataFlow & Indexierung). Solr bleibt performant und responsiv für Suchanfragen, während im Hintergrund Daten transformiert und verschoben werden. Das ist ein wichtiger Faktor, vor allem in einer Produktivumgebung. Das Trennen von Suche und Indexierung ist ohnehin ein Best Practice Ansatz für den professionellen Einsatz von Solr.
Mit seinem Begleittool zur Versionskontrolle, der NiFi Registry, ermöglicht NiFi auch die Versionsverwaltung unterschiedlicher DataFlows – optional mit Git-Integration. Somit können, im Gegensatz zum integrierten DIH, unterschiedliche Zweige von DataFlows parallel entwickelt und getestet, Rollbacks auf ältere Versionen getätigt und kollaborativ an Features und Pipelines im Team gearbeitet werden.NiFi bietet gegenüber dem integrierten DIH von Solr zudem noch weitere Vorteile:
- Data buffering / Backpressuring
- Priorisierte Warteschlangen
- Flow Templates
- Clustering
- Record-based Processing: Schema-Definition und Verwendung


