

Im ersten Teil dieser Blogserie haben wir zwei grundlegende Strategien zur Verbesserung der Suche in RAG-Systemen betrachtet: die hybride Suche und die asymmetrischen Embedding-Modelle. Beide verfolgen das Ziel, die Relevanz und Präzision der abgerufenen Informationen zu erhöhen.
In diesem zweiten Beitrag stellen wir zwei weitere Ansätze vor, mit denen sich das Retrieval in RAG-Systemen gezielt verbessern lässt. Reranking, das sowohl mit Cross-Encodern als auch mit LLM as Judge umgesetzt werden kann, sowie HyDE – Hypothetical Document Embeddings. Beide Methoden nutzen die Stärken großer Sprachmodelle, um die Relevanz von Treffern genauer einzuschätzen und dadurch präzisere Antworten zu ermöglichen.
Warum Reranking
Wenn man ein RAG-System in der Praxis einsetzt, beginnt alles mit der Erstellung von Embedding-Repräsentationen.
Kurz zur Auffrischung: Embeddings sind Vektoren, die Wörter oder Textabschnitte in einem mehrdimensionalen Raum darstellen. Der Abstand und die Richtung dieser Vektoren zeigen, wie stark sich Inhalte in ihrer Bedeutung ähneln und bilden damit semantische Beziehungen zwischen Texten ab. Das funktioniert grundsätzlich gut, hat aber einige Schwächen:
Erstens: Embeddings können semantische Repräsentationen eines Textes zwar darstellen, übersehen aber oft kleine Bedeutungsunterschiede. Wenn komplexe Inhalte in feste Vektoren gepackt werden, gehen Details verloren. Zwei Sätze können fast gleich klingen, aber etwas Anderes aussagen – im Vektorraum wirken sie trotzdem sehr ähnlich. Das Ergebnis: Abschnitte, die thematisch passen, aber inhaltlich nicht wirklich relevant sind, rutschen in die Trefferliste.
Zweitens: Es gibt Generalisierungsprobleme. Embeddings sind stark, wenn die vektorisierten Daten den Trainingsdaten des Modells ähneln. In neuen oder spezialisierten Domänen fällt die Relevanzbewertung dagegen oft deutlich ab.
Die Folge: Wir erhalten häufig semantisch verwandte, aber nicht wirklich relevante Passagen. Wenn solche Inhalte in die Antwortgenerierung des LLM einfließen, steigt das Risiko für ungenaue oder halluzinierte Antworten. Genau hier setzt Reranking an.
Reranking mit Cross-Encodern / LLM as Judge
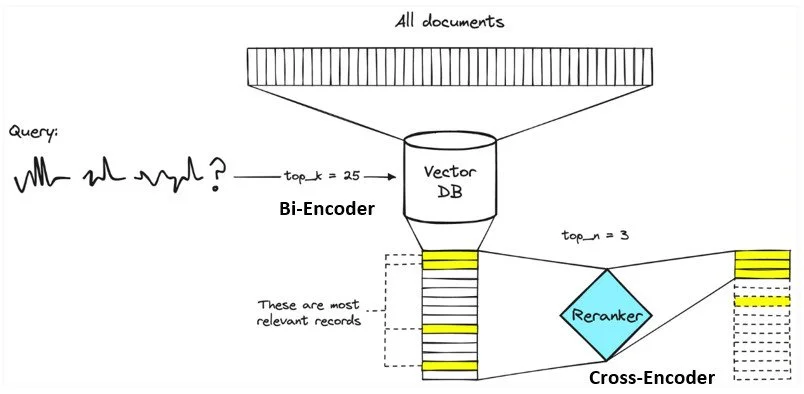
In Abbildung 1 ist dargestellt, wie der Reranking-Prozess abläuft. Links beginnt der Prozess mit der Query. Zuerst wird sie an die Vektordatenbank geschickt. Diese liefert uns schnell eine Kandidatenliste, zum Beispiel die Top-k = 25 Passagen, die semantisch am ähnlichsten sind. Das sorgt für eine gute Abdeckung, enthält aber oft noch einiges an Rauschen.
An dieser Stelle kommt der Reranker ins Spiel. Er prüft jede dieser Kandidaten erneut, diesmal gemeinsam mit der Query und bewertet, wie gut sie tatsächlich passen. Das ist der zweite Durchgang, präziser als der erste, weil Query und Text zusammen betrachtet werden. Im letzten Schritt sehen wir das Ergebnis: Aus den 25 ursprünglichen Kandidaten bleiben die Top-n = 3 besten Passagen übrig, genau jene, die dem LLM als Kontext übergeben werden.
Top-k steuert die Breite der ersten Suche, während Top-n festlegt, wie viel präziser Kontext ins Modell gelangt. So lässt sich Rauschen verringern, das Risiko für Halluzinationen senken und die Antwortqualität deutlich verbessern.
Bi-Encoder vs. Cross-Encoder – der Kernunterschied
Der Bi-Encoder ist unser Finder. Er wandelt die Query in einen Vektor um; die Dokumente wurden bereits zuvor in Vektoren umgewandelt. Die Relevanz ergibt sich anschließend aus der Ähnlichkeit zwischen diesen Vektoren, zum Beispiel durch die Kosinus-Ähnlichkeit.
Das Verfahren ist extrem schnell und skaliert sehr gut, ideal um aus einer großen Menge an Texten eine erste Top-k-Kandidatenliste zu erhalten.
Der Nachteil: Beim Scoring findet keine direkte Wort-zu-Wort-Interaktion zwischen Query und Text statt. Dadurch können viele Bedeutungsdetails leicht verloren gehen.
Der Cross-Encoder (Reranker) ist dagegen unser Prüfer. Er erhält Query und Dokument gemeinsam als Eingabe und berechnet einen gelernten Relevanz-Score für jedes Paar. Dabei berücksichtigt das Modell Token-Interaktionen, es erkennt also Unterschiede in Negationen, Zahlenwerten oder Formulierungen.
Das ist deutlich präziser, aber auch rechenintensiver, da für jeden Kandidaten ein eigener Vorwärtslauf nötig ist. Deshalb setzen wir ihn im Zweitpass des Reranking-Prozesses ein: Zuerst mit dem Bi-Encoder breit suchen, dann mit dem Cross-Encoder fein sortieren und schließlich nur die besten Treffer an das LLM übergeben.
LLM as a Judge – Reranking mit Sprachmodellen
Reranking kann auch auf eine andere Weise erfolgen. Beim Ansatz von LLM as Judge übernimmt ein großes Sprachmodell die Rolle eines Relevanz-Richters. Wir geben die Query und die Kandidatenpassagen vor, das LLM bewertet anschließend ihre Reihenfolge, ganz ohne spezielles Reranking-Finetuning.
Dabei gibt es drei gängige Vorgehensweisen:
Pointwise: Das LLM bewertet jedes Dokument einzeln. Der Ansatz ist einfach und gut zu parallelisieren, berücksichtigt aber keine Vergleiche zwischen den Dokumenten.
Pairwise: Zwei Kandidaten werden direkt gegenübergestellt, das LLM entscheidet, welcher besser passt. Das ist präziser, erfordert aber mehr Modellaufrufe.
Listwise: Das LLM sieht die gesamte Kandidatenliste (z. B. die Top-k) und gibt eine geordnete Liste zurück. Dieser Ansatz ist sehr leistungsfähig, wird jedoch durch das verfügbare Kontextfenster begrenzt. Studien zeigen, dass listwise-LLM-Reranker häufig besonders gute Ergebnisse erzielen. Auf diese Weise lässt sich ein Reranking der Dokumente durchführen, ohne ein spezielles Reranking-Modell, sondern allein mit einem LLM.
HyDE – Hypothetical Document Embeddings
Ein weiterer Ansatz, der das Retrieval im RAG-Prozess deutlich verbessern kann, sind die Hypothetical Document Embeddings (HyDE). Die Idee dahinter: Anstatt die kurze Query direkt zu embedden, lässt man zunächst ein LLM eine hypothetische Passage zur Frage generieren. Diese Passage wird anschließend vektorisiert und als Suchabfrage im Vektorraum verwendet.
Die vom LLM erzeugte Passage enthält in der Regel mehr Kontext, Synonyme und relevante Begriffe als die ursprüngliche, oft sehr knappe Query. Dadurch landet die semantische Suche näher an den tatsächlich relevanten Passagen im Korpus.
Die hypothetischen Passagen dienen jedoch ausschließlich dem Retrieval-Schritt. In den Antwortkontext des LLMs fließen nur die echten, gefundenen Passagen ein, nicht der generierte Text. In Abbildung 2 sieht man links das klassische RAG-Prinzip: Eine Frage wird direkt verwendet, um relevante Dokumente zu suchen. Rechts dagegen der HyDE-Ansatz: Aus der Frage erzeugt das LLM zunächst eine hypothetische Passage, also einen kurzen Text, der die Frage beantworten könnte. Diese Passage wird dann in einen Vektor umgewandelt und als Suchanfrage für die Vektorsuche genutzt.

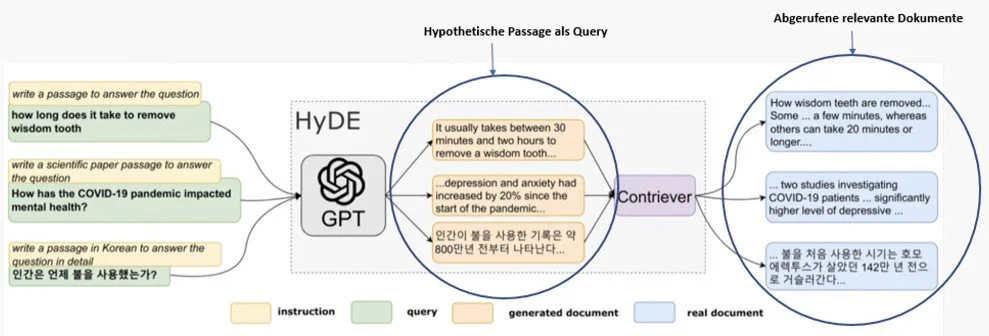
Abbildung 3 zeigt, wie der Ablauf beim Hypothetical Document Embeddings (HyDE) funktioniert.
Links sehen wir die Query zusammen mit einer kurzen Anweisung – etwa: „Schreibe eine Passage, die die Frage beantwortet.“
In der mittleren HyDE-Stufe erzeugt das LLM daraufhin eine hypothetische Passage. Diese Passage wird anschließend mit dem Retriever-Embedding-Modell (z. B. Contriever) vektorisiert und als Suchvektor verwendet.
Rechts sieht man das Ergebnis der knn-Suche im Korpus: reale Dokumentpassagen, die der hypothetischen Passage semantisch am nächsten liegen.
Wichtig ist wieder zu betonen: Nur diese echten Passagen gehen später als Kontext ins LLM, die generierte Passage dient ausschließlich dazu, die Suche zu präzisieren. Das macht den Ansatz besonders nützlich für RAG: Durch die kontextreichere Suchrepräsentation steigt die Relevanz der Treffer, das LLM erhält passenderen Kontext und kann dadurch präzisere und fundiertere Antworten liefern.
Fazit und Ausblick
Reranking und Hypothetical Document Embeddings zeigen, wie sich das Retrieval in RAG-Systemen gezielt verfeinern lässt. Während das Reranking durch eine zweite Bewertungsstufe unpassende Treffer herausfiltert, sorgt HyDE mit einer kontextreicheren Suchrepräsentation dafür, dass relevante Informationen überhaupt erst in den Fokus geraten. Zusammen führen diese Ansätze zu präziseren, fundierteren und verlässlicheren Antworten im gesamten RAG-Prozess.
Im letzten Beitrag dieser Serie stellen wir zwei weitere Strategien zur Verbesserung der Suche vor: Knowledge Graphs und wie sie in Graph RAG eingesetzt werden, sowie Embedding Tuning, also die gezielte Anpassung von Embedding-Modellen an eigene Domänen. Bleiben Sie dran, der letzte Teil der Serie folgt.


