

RAG-Systeme gehören derzeit zu den leistungsfähigsten Ansätzen, um Large Language Models den Zugriff auf externe Daten zu ermöglichen und dadurch aktuelle sowie domänenspezifische Antworten zu liefern. Doch wie bei jeder Technologie gilt: Auch starke Systeme lassen sich noch intelligenter gestalten.
Gerade im Zusammenspiel zwischen Suche und Generierung liegen enorme Potenziale. Besonders die Suche spielt dabei eine entscheidende Rolle, denn die Qualität der Antworten eines RAG-Systems steht und fällt mit der Qualität der Informationen, die es findet.
Die Suche ist also weit mehr als nur ein technischer Zwischenschritt, sie bildet das Kernstück jedes leistungsfähigen RAG-Systems.
In dieser Blogserie geht es um Strategien, die das Retrieval in RAG-Systemen effizienter und präziser machen. Dabei werden verschiedene Ansätze vorgestellt, von hybriden Suchverfahren über Reranking bis hin zu GraphRAG und Embedding-Tuning. Im ersten Teil der Serie liegt der Fokus auf zwei zentralen Ansätzen zur Verbesserung der Suche in RAG-Systemen: der hybriden Suche und dem Einsatz asymmetrischer Embedding-Modelle.
Inhaltsverzeichnis
Suche als Herzstück für RAG
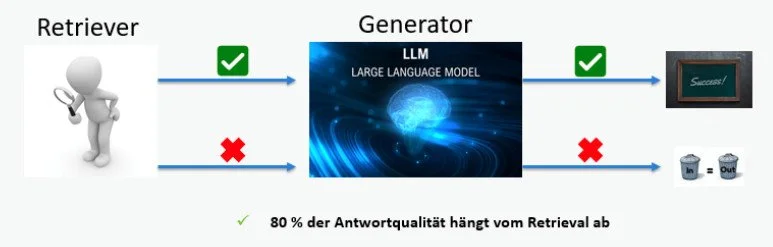
Im Zentrum eines jeden RAG-Systems steht das Zusammenspiel von zwei Komponenten: dem Retriever und dem Generator. Der Retriever ist dafür verantwortlich, die passenden Informationen aus einer Wissensquelle zu finden, typischerweise aus Dokumenten, die zuvor vektorisiert und in einer Datenbank gespeichert wurden. Der Generator nutzt anschließend diese gefundenen Inhalte, um daraus eine kohärente und fundierte Antwort zu formulieren.
Wenn der Retriever relevante und vollständige Dokumente liefert, kann das Sprachmodell auf fundierte Informationen zurückgreifen und dadurch präzise, nachvollziehbare Antworten erzeugen. Liefert er dagegen unpassende oder unvollständige Informationen, entsteht der klassische Effekt: Garbage in, garbage out. Das bedeutet, selbst das beste Sprachmodell kann innerhalb eines RAG-Systems nur so gut antworten, wie die Qualität der Daten, die es erhält. Mehr als die Hälfte der Gesamtleistung eines RAG-Systems hängt, wie Studien und Praxiserfahrungen zeigen, von der Qualität und Effizienz der Suche ab.
Hybride Suche
Hybride Suche im Detail
Der Begriff hybride Suche ist nicht eindeutig definiert. Im Grunde lässt sich jede Suche, bei der mehr als ein Verfahren kombiniert wird, als eine Form von Hybrid bezeichnen. In der Praxis lassen sich dabei einige typische Varianten unterscheiden:
1. Vektorsuche mit Attribut-Filtern
Dabei werden semantische Suchergebnisse mithilfe von Metadaten wie Zeitraum, Dokumenttyp usw. eingeschränkt. Diese gefilterte Vektorsuche ist eine einfache, aber äußerst nützliche Grundform hybrider Ansätze.
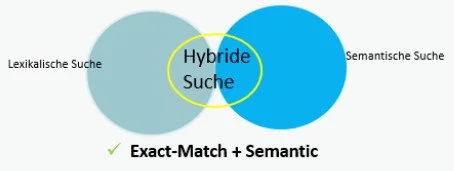
2. Kombination von semantischer und lexikalischer Suche
Diese Form der hybriden Suche findet in der Praxis breite Anwendung. Die semantische Suche erkennt Bedeutungsähnlichkeiten und Synonyme, während die Keyword-Suche exakte Fachbegriffe oder Formulierungen trifft. Durch das Zusammenführen beider Ergebnisse und ein anschließendes Re-Ranking lässt sich die Relevanz der Treffer deutlich steigern. Auf genau diesen Ansatz, werden wir in diesem Blogbeitrag näher eingehen und seine Rolle im RAG-Kontext analysieren.
Lexikalische vs. semantische Suche
Die lexikalische Suche ist der klassische Ansatz. Sie findet exakte Übereinstimmungen von Wörtern oder Phrasen ideal, wenn nach konkreten Begriffen wie Zitaten, Aktenzeichen usw. gesucht wird. Ihre Grenzen zeigen sich jedoch bei der natürlichen Sprache: Mehrdeutigkeit, fehlendes Verständnis für Synonyme oder Paraphrasen, wenn keine speziellen Regeln definiert sind und die Abwesenheit von Kontext führen oft dazu, dass relevante Inhalte übersehen werden.
Die semantische Suche geht einen Schritt weiter. Sie versucht, Bedeutung und Intention einer Anfrage zu verstehen, mithilfe von Natural Language Processing (NLP) und Embeddings. Wörter oder Sätze werden dabei als Vektoren in einem hochdimensionalen Raum dargestellt. Nähe im Vektorraum entspricht Bedeutungsähnlichkeit. So erkennt das System inhaltliche Zusammenhänge, selbst wenn eine Anfrage anders formuliert ist.
Natürlich hat auch dieser Ansatz seine Grenzen: Exakte Übereinstimmungen können übersehen werden, und aufgrund der komplexeren Verarbeitung steigt die Latenzzeit, also die Antwortdauer pro Anfrage.
Die hybride Suche kombiniert schließlich beide Welten. In der Praxis bedeutet das:
Zuerst werden durch die lexikalische Suche exakte Treffer identifiziert. Parallel dazu wird der Vektorraum nach inhaltlich ähnlichen Passagen durchsucht. Anschließend werden beide Ergebnislisten zusammengeführt, nach Relevanz neu geordnet und die besten Treffer, die sogenannten Top-k-Dokumente, an das Sprachmodell übergeben.
Das Ergebnis: Wir vereinen die Präzision der exakten Wortsuche mit dem Verständnis der semantischen Suche. So entstehen kontextbezogene, robustere Treffer und damit deutlich bessere Antworten im RAG.
Asymmetrische Embedding-Modelle
Ein weiterer Ansatz zur Verbesserung der Suche in RAG-Systemen ist die Verwendung sogenannter asymmetrischer Embedding-Modelle.
Die Grundidee: Für die Vektorisierung im RAG wird dasselbe Modell verwendet, jedoch werden die Embeddings unterschiedlich erzeugt, abhängig davon, ob es sich um eine Query (Frage) oder um eine Passage (Dokumentinhalt) handelt. Viele dieser Modelle erreichen das über kleine Hinweise im Input, sogenannte Prefix-Tokens wie „query“ und „passage“. Dadurch kann derselbe Text zwei unterschiedliche Repräsentationen annehmen, je nachdem, ob er als Frage oder als Dokument interpretiert wird.
Das Ziel dieses Ansatzes ist es, die Repräsentationen von Frage und Inhalt gezielt voneinander zu unterscheiden. So entsteht eine gezielte Asymmetrie zwischen Frage und Inhalt:
Kurze, präzise Queries lassen sich dadurch zuverlässiger mit den Textstellen abgleichen, die sie tatsächlich beantworten und nicht nur mit oberflächlich ähnlichen Formulierungen.
Vorteile asymmetrischer Embedding-Modelle
- Passend für Kurzfrage – Langtext
In RAG sind Queries kurz, Passagen länger. Asymmetrische Modelle sind genau darauf ausgelegt: Die Anfrage wird als Informationsbedarf (Information Need), repräsentiert, die Passage als Beleg / Kontext. Das erhöht die Chance, dass kurze Fragen verlässlich die passenden Textstellen finden.
- Höhere Relevanz statt bloßer Satzähnlichkeit
Die Query-Seite ist auf Antwortrelevanz optimiert nicht nur auf sprachliche Ähnlichkeit. Dadurch landen Passagen vorne, die die Frage tatsächlich beantworten, nicht nur solche, die ähnlich formuliert sind.
- Robust gegenüber Synonymen und Umformulierungen
Query und Passage erhalten rollenspezifische Repräsentationen. Diese Trennung macht die Suche zuverlässiger gegenüber variierender Wortwahl und Paraphrasen und führt im Vergleich zu rein symmetrischen Modellen zu höherer Trefferqualität. Die Asymmetrie sorgt dafür, dass die Embeddings gezielt auf Relevanz im Suchkontext optimiert sind und das führt in RAG zu einer messbaren Verbesserung von Recall und Präzision.
Fazit und Ausblick
Die Qualität der Suche entscheidet maßgeblich über die Leistungsfähigkeit eines RAG-Systems.
Mit der hybriden Suche und den asymmetrischen Embedding-Modellen stehen zwei wirkungsvolle Ansätze zur Verfügung, um die Relevanz und Präzision im Retrieval deutlich zu steigern.
Während die hybride Suche die Stärken von semantischer und lexikalischer Suche kombiniert, sorgen asymmetrische Embeddings dafür, dass Fragen und Inhalte mit unterschiedlichen Schwerpunkten dargestellt werden – gezielt auf Antwortrelevanz hin optimiert.
Gemeinsam zeigen sie, wie sich durch eine bessere Suche der gesamte RAG-Prozess intelligenter und effizienter gestalten lässt.
In den nächsten zwei Beiträgen dieser Reihe geht es um weitere Strategien zur Verbesserung des Retrievals in RAG-Systemen. Der zweite Blogbeitrag behandelt die spannenden Methoden Reranking mit Cross-Encodern und LLM as Judge sowie Hypothetical Document Embeddings (HyDE).
Bleiben Sie dran!


