

In der modernen digitalen Landschaft spielen Daten eine zentrale Rolle, doch um ihre volle Nutzbarkeit zu entfalten, bedarf es einer sorgfältigen Datenaufbereitung. Ein entscheidender Schritt im Prozess der Retrieval-Augmented Generation (RAG) ist die Aufteilung großer Dokumente in kleinere, handhabbare Abschnitte, sogenannte Chunks. Diese Methode verbessert die Effizienz, Relevanz und Skalierbarkeit des Systems erheblich. Kleinere Einheiten lassen sich schneller durchsuchen und verarbeiten, was zu präziseren und aktuelleren Ergebnissen führt. In diesem Beitrag beleuchten wir die Bedeutung der Datenaufbereitung im RAG-Prozess und zeigen, wie diese Methode die Leistung und Genauigkeit unserer Systeme optimiert.
Inhaltsverzeichnis
Die Bedeutung der Datenaufbereitung im RAG-Prozess
In der modernen digitalen Landschaft spielen Daten eine zentrale Rolle. Doch bevor diese Daten nützlich gemacht werden können, müssen sie aufbereitet werden. Ein essenzieller Schritt im Prozess der Retrieval-Augmented Generation (RAG) ist die Datenaufbereitung. Dabei werden große Dokumente in kleinere, handhabbare Abschnitte, sogenannte Chunks, aufgeteilt. Diese Chunks sind kleine Textabschnitte, die aus einem größeren Dokument extrahiert werden. Warum ist das notwendig?
- Effizienz: Kleinere Einheiten lassen sich schneller durchsuchen und verarbeiten, wodurch das System effizienter wird.
- Relevanz: Das System kann spezifischere und relevantere Informationen aus den Chunks extrahieren.
- Skalierbarkeit: Diese Methode ist skalierbar und kann problemlos auch bei sehr großen Datensätzen angewendet werden.
Durch die Aufteilung in Chunks sorgt die Datenaufbereitung dafür, dass unser System effizienter, genauer und skalierbarer arbeitet.
Chunking und Vektorspeicherung
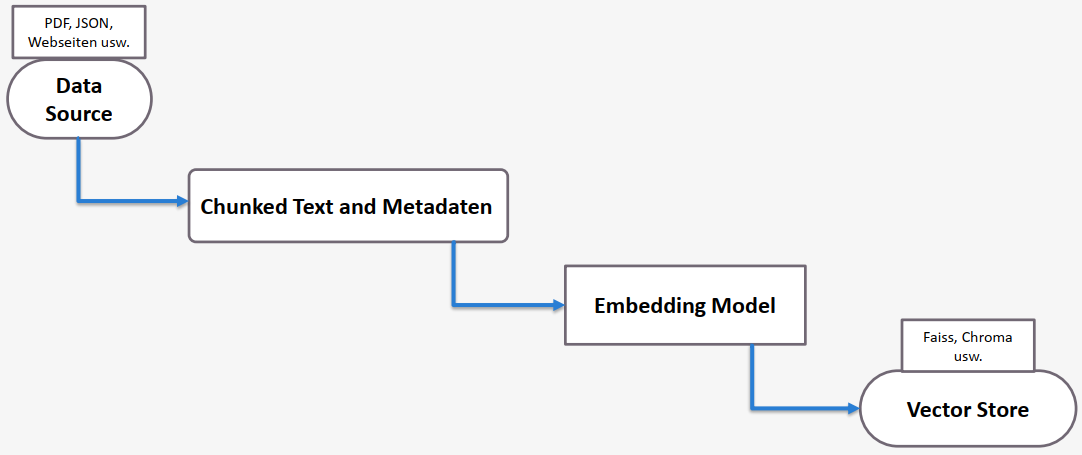
Wie funktioniert das im Detail? Der Prozess beginnt mit einer Datenquelle, wobei die Dokumente in verschiedenen Formaten vorliegen können. Mithilfe einer Chunk-Strategie wird der Text in kleinere Teile aufgesplittet. Diese Chunks werden zusammen mit ihren Metadaten in ein Embedding-Modell eingespeist. Ein Embedding ist eine numerische Darstellung des Textes, die es dem Modell ermöglicht, semantische Ähnlichkeiten zwischen verschiedenen Texten zu erkennen. Das Embedding-Modell transformiert dann alle Daten in Embeddings-Vektoren und speichert diese in einer Vektor-Datenbank wie Apache Solr, Chroma, Faiss oder ähnliche. Solr bietet hierbei eine leistungsfähige und flexible Lösung zur Speicherung und schnellen Abfrage von Vektor-Daten.
RAG-Architektur: Einblicke und Funktionsweise
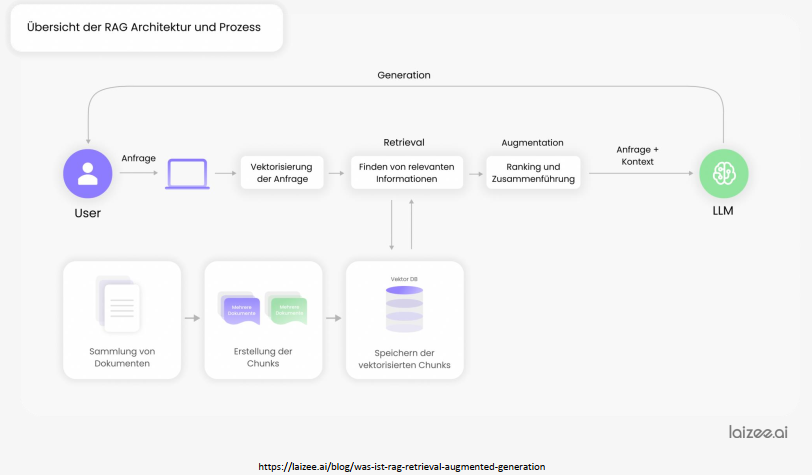
Die Architektur der Retrieval-Augmented Generation (RAG) ist ein faszinierendes Zusammenspiel verschiedener Komponenten.
- Abfrage und Transformation: Der Benutzer sendet eine Anfrage an das System, die mithilfe eines Embeddings-Modells in einen Vektor umgewandelt wird, um die semantische Bedeutung der Anfrage zu erfassen.
- Vektorbasiertes Retrieval: Basierend auf dem Vektor der Anfrage wird in der Vektordatenbank nach relevanten Informationen gesucht. Die relevanten Daten werden dann abgerufen, bewertet, neu geordnet und die relevantesten Ergebnisse werden konsolidiert.
- Anreicherung und Antwortgenerierung: Die ursprüngliche Anfrage und der ermittelte Kontext werden an ein Large Language Model (LLM) weitergegeben. Das LLM generiert mithilfe der zusätzlichen Informationen eine präzise und kontextbezogene Antwort, die an den Benutzer zurückgegeben wird.
Retrieval und Augmentation erklärt
Retrieval-Methoden im RAG-Prozess:
- Keyword-basierte Suche: Dokumente werden auf Grundlage spezifischer Schlüsselwörter durchsucht. Diese Methode findet exakte Übereinstimmungen der Schlüsselwörter in den Dokumenten.
- Vektorbasierte Suche: Embeddings werden verwendet, um den semantischen Inhalt der Suchanfrage und der Dokumente zu repräsentieren. Diese Methode ermöglicht es, inhaltlich ähnliche, aber nicht unbedingt exakt übereinstimmende Dokumente zu finden.
- Ähnlichkeitssuche (Similarity Search): Verfahren wie Cosine Similarity oder BM25 berechnen die Ähnlichkeit zwischen der Suchanfrage und den Dokumenten, um die relevantesten Dokumente basierend auf ihrer semantischen Nähe zur Anfrage zu ermitteln.
Augmentation:
- Ranking: Die abgerufenen Dokumente werden sortiert und bewertet, um die relevantesten Informationen zu identifizieren. Fortgeschrittene Modelle wie BERT-basierte Reranker können hierbei zum Einsatz kommen.
- Zusammenführung (Merging): Die wichtigsten Informationen aus den top-bewerteten Dokumenten werden extrahiert und zusammengeführt, um eine präzise und umfassende Antwort zu erstellen. Je nach Komplexität des Systems können dabei zusätzliche Schritte wie Re-Ranking, Kontext-Kompression oder spezielle Optimierungen zum Einsatz kommen, um die Qualität der Antwort weiter zu verbessern.
Die Basiskomponenten von RAG
Die wichtigsten Basiskomponenten des RAG-Systems:
- External Data: RAG nutzt externe Datenquellen, um aktuelle und relevante Informationen in Echtzeit abzurufen, die über das hinausgehen, was im ursprünglichen Trainingsdatensatz des LLM enthalten ist.
- Prompt: Die Eingabe oder Frage des Benutzers, die den Ausgangspunkt des gesamten Prozesses darstellt.
- System Prompt: Definiert, wie das Modell die Benutzeranfragen verarbeiten soll.
- Retriever: Eine der Kernkomponenten von RAG. Er durchsucht große Datenbanken, um relevante Dokumente basierend auf der Suchanfrage abzurufen.
- Generator (LLM): Der Generator ist das Sprachmodell (LLM), das auf Basis der abgerufenen und verarbeiteten Informationen eine kohärente Antwort erzeugt.
RAG vereinfacht: Der Detektiv und der Geschichtenerzähler
Stellen Sie sich RAG als ein Duo aus Detektiv und Geschichtenerzähler vor. Der Detektiv (Retriever) durchforstet Datenbanken nach relevanten Informationen und Beweisen. Sobald der Detektiv seine Arbeit erledigt hat, übernimmt der Geschichtenerzähler (Generator). Dieser verwandelt die gesammelten Informationen in eine kohärente und ansprechende Erzählung. Diese Synergie ermöglicht esgenaue Antworten auf Benutzeranfragen zu generieren.
Anwendungsbereiche von RAG
RAG zeigt seine Flexibilität und Leistungsfähigkeit in verschiedenen Anwendungsbereichen:
- Wissensbasierte Chatbots: RAG ermöglicht es, präzise und aktuelle Antworten auf Benutzeranfragen zu liefern, indem es auf externe Wissensquellen zugreift.
- Fragenbeantwortungssysteme: Diese Systeme nutzen RAG, um detaillierte und spezialisierte Antworten zu generieren, die auf fundierten externen Datenquellen basieren.
- Erstellung von Inhalten: RAG unterstützt die Erstellung von informativen und relevanten Texten, die stets auf den neuesten Informationen und spezifischen Daten beruhen.
- Erweiterte Suchfunktionen: Durch den Einsatz von RAG werden relevante Informationen schnell und effizient aus großen Datensätzen extrahiert.
RAG vs. Fine-Tuning
Der Unterschied zwischen Retrieval-Augmented Generation (RAG) und Fine-Tuning ist entscheidend:
- RAG: Verbessert die Qualität und Relevanz der generierten Texte, indem es das bestehende Wissen vortrainierter Large Language Models (LLMs) mit externen Wissensdatenbanken erweitert.
- Fine-Tuning: Passt ein vortrainiertes Large Language Model (LLM) speziell an eine bestimmte Aufgabe oder Domäne an, indem es mit annotierten, also gekennzeichneten, Daten weiter trainiert wird. Dies führt zu Modellen, die für spezifische Aufgaben sehr präzise sind, jedoch auf Kosten der breiteren Anwendbarkeit, da das Modell stärker auf die spezifischen Daten fokussiert ist und möglicherweise weniger flexibel in anderen Kontexten ist.
Zusammengefasst: RAG liefert aktuelle und spezialisierte Antworten, indem es externe Wissensquellen einbezieht, während Fine-Tuning das LLM für spezifische Anwendungen optimiert.
Für alle, die die Digitalisierung in ihrem Unternehmen vorantreiben möchten, bietet RAG eine leistungsstarke Möglichkeit, präzise und relevante Informationen schnell und effizient zu nutzen. Durch die Kombination von Datenretrieval und Texterstellung ermöglicht RAG eine nahtlose Integration, die den Anforderungen der modernen Geschäftswelt gerecht wird.
Im dritten Beitrag zu RAG untersuchen wir verschiedene etablierte Chunking-Strategien zur Datenaufbereitung im RAG-Prozess und zeigen anhand von Beispielen, wie jede Methode die Strukturierung der Daten für präzise und effiziente Antworten unterstützt.


