

In einem früheren Blog-Beitrag haben wir unsere Cross-Analytics Strategie vorgestellt, die das Ziel hat, die Möglichkeiten von Advanced Analytics längerfristig im Unternehmen zu nutzen. Dadurch sollen bspw. Anwendungen des Maschinellen Lernens (ML) möglich werden, die zur Ermittlung personalisierter Kaufempfehlungen im eigenen Shop oder zur automatischen Generierung von Voraussagen für die zukünftige Nachfrage genutzt werden können. In diesem ersten Teil des Beitrags sprechen wir darüber, wie man die verschiedenen Komponenten in einer Architektur am besten miteinander kombiniert, sodass die im Unternehmen vorhandenen Datenschätze zusammengebracht und verarbeitet werden können, um die vielfältigen Anwendungen von Advanced Analytics zu realisieren.
Den Grundstein legen
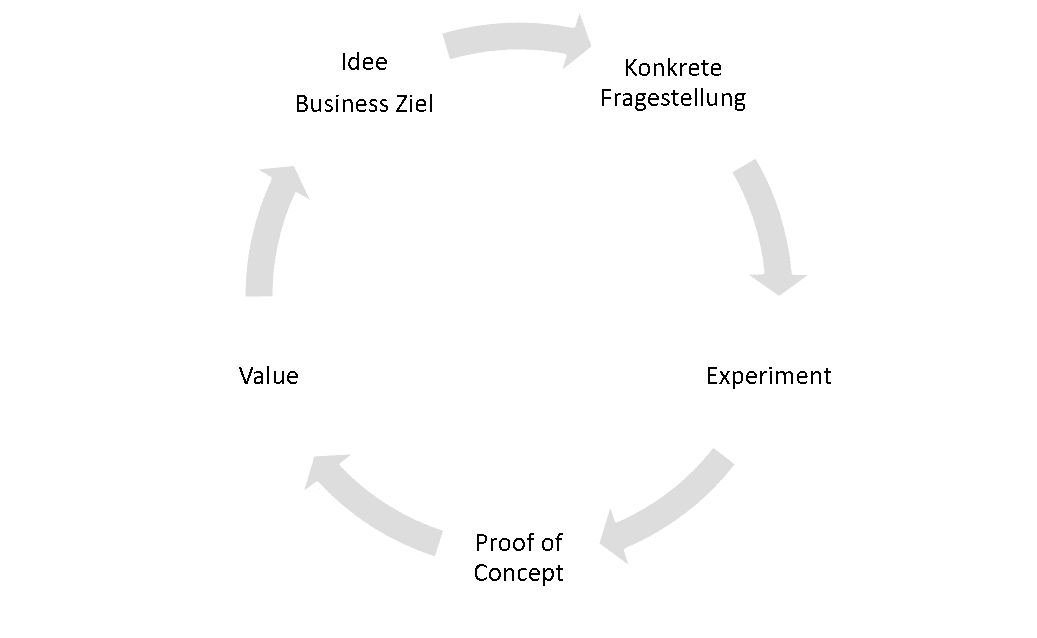
Für einen Start in die Thematik empfiehlt sich nach unserer Cross-Analytics Strategie, ein konkretes Business-Ziel zu identifizieren, das mit Hilfe von Analytics-Methoden beleuchtet werden soll und einen merklichen Nutzen verspricht, den man in einem ersten Experiment mit überschaubaren Aufwand überprüfen kann. Das Erreichen des Ziels unter realen Bedingungen kann dann in einem Proof of Concept validieret werden (s. Abb. 1). So lässt sich das Risiko begrenzen und Lerneffekte werden schnell erzielen. Daher sollte sich die Umsetzung der Architektur auch an dieser Vorgehensweise orientieren.
Am Anfang eines konkreten Experiments geht es darum, die relevanten Daten, welche die Analytics-Anwendung ermöglichen könnten, zu identifizieren, aufzubereiten und miteinander zu kombinieren. Oft stammen diese aus einer kleinen Anzahl unterschiedlicher Datenquellen, sodass die Daten sich im Prinzip in einer traditionellen Datenbank oder im File-System auf dem Laptop kombinieren lassen. Dieser „Laptop-Data-Science“-Ansatz ist auf Dauer nicht attraktiv – was ist, wenn Kopien von sensiblen Daten auf verschiedenen Maschinen existieren? Was passiert, wenn zusätzliche Datenarten wie Texte berücksichtigt werden sollen? Wie organisiert man das Deploy von Analytics-Modellen auf der Infrastruktur, usw.? Der Prozess der Datenaufbereitung und Zusammenführung macht einen großen Teil des Aufwands aus bei Analytics-Projekten, daher sollte er von der Architektur besonders gut unterstützt werden.
So lohnt es sich längerfristig, bezüglich der Infrastruktur gleich den Grundstein für die Zukunft zu legen und von Anfang an auf Best Practices und Architekturmuster zurückzugreifen, die im Kontext von Big Data entstanden sind. Da in diesem Bereich die Software-Standards von Open Source Komponenten gestellt werden, ist hohe Flexibilität garantiert. So kann man beim Aufbau der Infrastruktur Schritt für Schritt vorgehen und sich zunächst an den Anforderungen des konkret geplanten Analytics-Projekts orientieren und nach Bedarf später wachsen.
Grundgerüst auf Open Source Basis
Schon mal vorab: es gibt keine Standard-Lösung für eine Architektur für Advanced Analytics. Wie die Architektur konkret aussieht, hängt sehr stark damit zusammen, welche Datenquellen vorhanden sind und welche Analytics-Anwendungen realisiert werden sollen. Stark vereinfacht lassen sich jedoch meistens drei Schichten ausmachen:
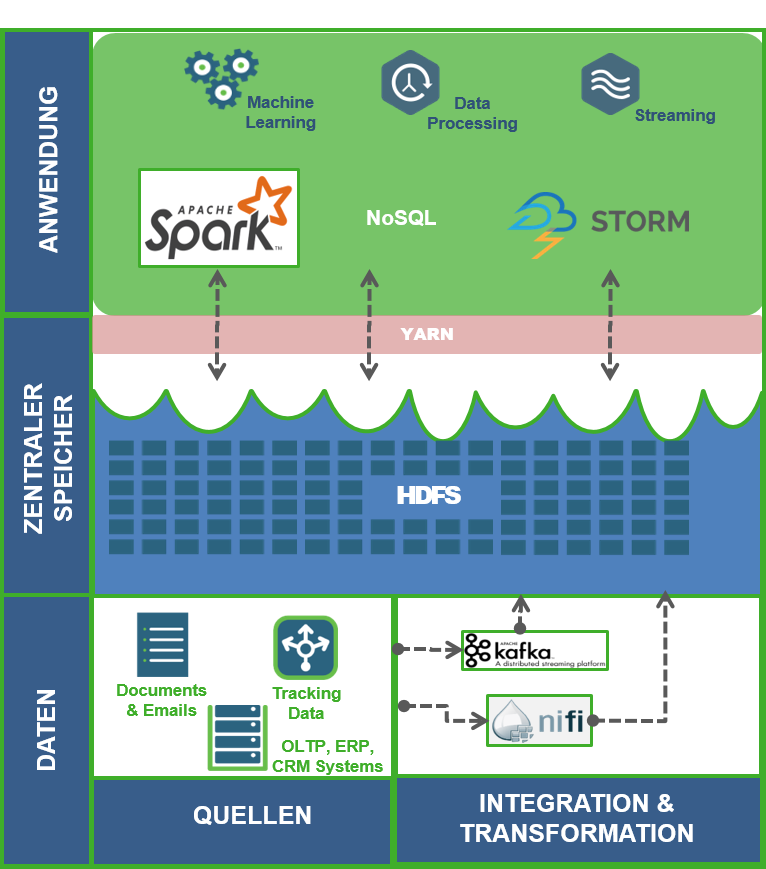
Datenquellen integrieren
Die erste Schicht stellt die verschiedenen Datenquellen, die im Unternehmen entstehen und die es zusammenzuführen gilt. Sie beinhaltet Komponenten für den Datentransport und die Datentransformation. Systeme wie ein Data Warehouse, ein CRM, ERP, POS, Warenwirtschaft etc. halten strukturierte Daten vor und können in der Regel über Schnittstellen und APIs abgegriffen werden. Oft möchte man unstrukturierte Textdaten wie Social Media Posts und Kundenrezension für die Analyse damit kombinieren. Manchmal präsentieren sich relevante Daten als kontinuierlicher Strom von Signalen: Clickstreams, Log-Daten, Beacons und andere Sensordaten aus dem Internet of Things (IoT).
Um diese verschiedenen Datenquellen und -arten überhaupt abgreifen und zusammenzuführen zu können, stellen Komponenten wie Apache NiFi zum einen Konnektoren für verschiedene Datenrepositories (z.B. Datenbanken oder File-Systeme) bereit. Zum anderen lassen sich mit NiFi Workflows definieren, welche die Daten nach Bedarf transformieren, bevor sie im zentralen Datenspeicher abgelegt werden. Bei Streaming-Szenarien ermöglicht Apache Kafka dagegen einen hochskalierbaren und fehlertoleranten Datentransport, um bspw. Click-Events auf der Homepage weiterzuleiten.
Der zentrale Datenspeicher
Hier erfolgt ein einheitlicher Zugriff auf die verschiedenen Datenarten. Apache Hadoop ist oft die erste Wahl als zentrale Datenhaltungsschicht, da es ein verteiltes, hochskalierbares File System (HDFS) bereitstellt, in dem sich beliebig viele Daten jeglicher Art speichern lassen – das berühmte Data Lake. Diese Schicht ist das Pendant zum Datawarehouse im BI-Umfeld, mit dem großen Unterschied, dass die Daten nicht an ein übergreifendes Schema angepasst werden müssen.
Die Anwendungsschicht
Hier greifen verschiedene Komponenten auf den zentralen Speicher zu, um Anwendungen zu ermöglichen und die eigentliche Analyse der Daten durchzuführen. Dafür eignet sich Apache Spark besonders gut, da es sowohl quasi-statische Daten aus relationalen Datenbanken als auch Signalströme für Near-Real-Time-Anwendungen verarbeiten kann. Dank der in Spark enthaltenen Bibliotheken von Machine Learning- und Graph-Algorithmen können vielfältige Verfahren angewendet werden. Darüber hinaus sind in dieser Schicht oft NoSQL-Datenbanken angesiedelt, um spezielle Sichten auf die Daten besonders schnell für Anwendungen bereitzustellen. Die Verarbeitung von Signalströmen in dieser Schicht wird mit Hilfe von Tools wie Apache Storm durchgeführt.
Der Zugriff der verschiedenen Bearbeitungsansätze und Anwendungen auf die Ressourcen des Hadoop-Clusters regelt ein Manager wie Apache YARN, der für das Ressourcenmanagement und das Job-Scheduling zuständig ist.
Die konkrete Auswahl der Komponenten hängt stark von dem Anwendungsszenario ab – die Vielfalt an Open Source Komponenten im Big Data Bereich ist groß. Dies lässt sich an den unterschiedlichen Distributionen verschiedener Anbieter erkennen, die rund um HDFS verschiedene Komponenten zusammenstellen, wie z.B. HDP von unserem Partner Cloudera.
Das Bild vervollständigen
In diesem ersten Teil des Blogbeitrags zum Thema Architektur haben wir ein Grundgerüst aufgebaut, in dem die verschiedenen Quellen von Daten im Unternehmen abgegriffen werden, um sie in einem zentralen Speicher zusammenzuführen. Dadurch können unterschiedliche Datenarten miteinander kombiniert werden, was die Analyse von komplexen Zusammenhängen ermöglicht.
Bei der Umsetzung dieser Architektur sollte man in der Praxis so vorgehen, dass man sich an einem konkreten Business-Ziel orientiert, um zunächst nur die Datenquellen zu integrieren, welche für die Erreichung des Ziels relevant sind. Diese Vorgehensweise wird durch die Lizenzkostenfreiheit von Open Source Komponenten begünstigt, die gerade einen Einstieg mit einem (nahezu) kostenlosen Prototypen ermöglicht. Die Komponenten im Bereich Big Data sind auf Skalierbarkeit ausgerichtet, sodass sich das erste Grundgerüst bei zunehmenden Datenmengen oder Abbildung weiterer Anwendungsfälle problemlos erweitern lässt. Dabei besteht zudem die freie Wahl, die Infrastruktur in der Cloud oder in einem (eigenen) Rechenzentrum zu betreiben, was zur Flexibilität in Umsetzung und Betrieb beiträgt.
In diesem ersten Beitragsteil haben wir Aspekte ausgeblendet, die in der Praxis eine wichtige Rolle spielen, wie z.B. Sicherheit und Datenschutz oder die Wiederholbarkeit verschiedener Advanced Analytics Projekte. Wie das funktioniert und wie sich diese Herausforderungen durch die geeignete Architektur meistern lassen, erfahren Sie im zweiten Teil dieses Beitrags.


