

Ingest Pipelines sind eine der gängigen Methoden zur Verarbeitung Ihrer Daten vor der Indizierung in Elasticsearch. Sie ermöglichen es, mehrere Prozessoren zu verketten, die Änderungen an den eingehenden Daten vornehmen. Obwohl es eine lange Liste gebrauchsfertiger Prozessoren gibt, die von Elasticsearch bereitgestellt werden (https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest-processors.html), kann es vorkommen, dass keiner der eingebauten Prozessoren die Anforderungen erfüllt, die Sie haben.
Der Weg ohne eigenen Prozessor
Sie können entweder (außerhalb des Elastic Stacks) Code schreiben, der die eingehenden Daten abfängt, aktualisiert und dann an Elasticsearch sendet. Oder Sie verwenden Logstash, wo Sie mit Ruby-Code einige Datenmanipulationen durchzuführen können, bevor Sie die Daten an Elasticsearch übertragen werden. Allerdings müssten Sie in beiden Fällen einen weiteren Service einrichten, um die gewünschten Ergebnisse zu erzielen.
Der Weg mit eigenem Prozessor
Der einfachere und sauberere Weg besteht darin, einen eigenen Java-basierten, benutzerdefinierten Prozessor zu schreiben, den Sie als einfaches Plugin zu Ihrer Elasticsearch-Instanz hinzufügen. Er kann dann wie jeder andere Prozessor in Ihrer Ingest Pipeline verwendet werden. Ein zusätzlicher Service ist in dem Fall folglich nicht notwendig.
Schritt-für-Schritt-Anleitung zum eigenen Prozessor für die Ingest Pipeline
In diesem Artikel beschreiben wir Schritt für Schritt, wie Sie Ihren benutzerdefinierten Prozessor in Elasticsearch erstellen, einbinden und ausführen. Für dieses Tutorial erstellen wir ein Plugin mit dem Zweck, einen bestimmten Text zu ersetzen und an seiner Stelle ein bestimmtes Wort einzufügen. Die von uns verwendete Version des Elastic Stack ist 8.12.2.
- Wir beginnen mit dem Herunterladen des Quellcodes von Elasticsearch hier:
https://github.com/elastic/elasticsearch/tree/v8.12.2
Sie können entweder das gesamte Repository als ZIP-Datei herunterladen und extrahieren oder es mit GIT klonen. - Gehen Sie nach dem Herunterladen zu „Plugins/Beispiele“ und erstellen Sie ein Ordner mit einem Namen Ihrer Wahl. Wir nennen ihn hier „FilterProcessor“.
- Im „FilterProcessor“ erstellen wir eine Datei namens „build.gradle“ und einen Ordner namens „src“. Der Ordner „src“ sollte eine solche Ordnerstruktur enthalten:

build.gradle sollte folgenden Inhalt enthalten:
apply plugin: 'elasticsearch.esplugin'
esplugin {
name 'filter-script'
description 'An example script engine to use low level Lucene internals for expert scoring'
classname 'org.elasticsearch.example.filterScript.FilterIngestPlugin'
licenseFile rootProject.file('SSPL-1.0+ELASTIC-LICENSE-2.0.txt')
noticeFile rootProject.file('NOTICE.txt')
}
dependencies {
implementation "org.apache.commons:commons-lang3:3.12.0"
yamlRestTestRuntimeOnly "org.apache.logging.log4j:log4j-core:${log4jVersion}"
}
- Wir werden nun die folgenden zwei Java-Dateien erstellen: FilterIngestPlugin.java und FilterWordProcessor.java. Die beiden Quelldateien haben wir Ihnen hier zum Download bereitgestellt.
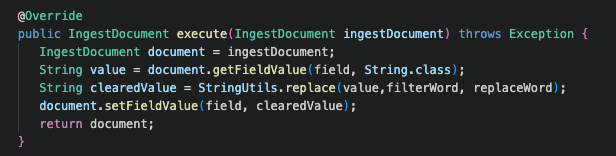
Die Magie geschieht in der „execute“-Methode, mit der Sie die Werte des eingehenden Dokuments abrufen, die Daten manipulieren und die Werte des Dokuments nach Ihren Wünschen festlegen können.
Die resultierende Ordnerstruktur sollte nun etwa so aussehen:

- Führen Sie den folgenden Befehl auf dem Terminal im Ordner „FilterProcessor“ aus:
gradle assemble
Dadurch wird ein neuer Ordner mit dem Namen „build“ erstellt und die Ordnerstruktur sieht folgendermaßen aus:

- Extrahieren Sie die ZIP-Datei filter-script-1.0.0-SNAPSHOT.zip und kopieren Sie den extrahierten Ordner in den Plugins-Ordner in Elasticsearch. Alternativ können Sie auch das von Elasticsearch bereitgestellte Befehlszeilentool namens „Elasticsearch-Plugin“ verwenden, um das Plugin zu installieren. Achten Sie darauf, dass „Elasticsearch.version“ in der Datei „plugin-descriptor.properties“ genau mit der Version des installierten Elasticsearch übereinstimmen sollte, andernfalls startet Elasticsearch nicht mit dem Plugin.
Der Plugins-Ordner sollte nun so aussehen:

- Der letzte Schritt, bevor wir dieses Plugin verwenden können, ist der Neustart von Elasticsearch.
Den eigenen Prozessor verwenden
Sobald Elasticsearch wieder läuft, können wir unseren neuen Ingest-Prozessor testen, indem wir zu DEV Tools in Kibana navigieren und die folgende Anfrage ausführen:
PUT /_ingest/pipeline/filter_crap
{
"processors": [
{
"filter_word" :
{ "field" : "description", "filterWord" : "crap","replaceWord":"oops" }
}
]
}
Dadurch wird eine Ingest Pipeline namens „filter_crap“ mit unserem soeben erstellten Prozessor erstellt.
Wir können jetzt ein Dokument mit dieser Ingest Pipeline wie folgt indizieren:
PUT /myindex/_doc/1?pipeline=filter_crap
{
"description": "crap ! Don't buy this."
}
Wenn wir uns dieses Dokument zurückgeben lassen, werden wir feststellen, dass der Prozessor „crap“ durch „oops“ ersetzt hat.
GET /myindex/_doc/1
Noch ein Gedanke zur Sicherheit
Benutzerdefinierte Prozessoren für Ingest Pipelines in Elasticsearch bieten Benutzer:innen eine einfache Möglichkeit, Daten zu manipulieren oder anzureichern, bevor sie in Elasticsearch aufgenommen werden, ohne dass ein externer Dienst erforderlich ist. Mit großer Macht geht jedoch auch große Verantwortung einher. Der Java Security Manager ist in Elasticsearch immer aktiviert. Das bedeutet, dass Sie nicht einfach beliebige Dateien lesen oder Netzwerk-Sockets öffnen können. Wenn Sie dies möchten, müssen Sie Ausnahmen in den Sicherheitsregeln hinzufügen. Für maximale Sicherheit Ihres Systems verfolgen Sie aber stets das „Principle of least Privilege“ und vergeben nur die notwendigen Rechte.


