

Eine der großen Herausforderung bei der Umsetzung einer Enterprise-Search ist die Anbindung der unterschiedlichsten Datenquellen. Jede Quelle hat ihre eigenen Schnittstellen, internen Strukturen und Daten bzw. Meta-Daten. Des Weiteren besitzen die Datenquellen eigene Sicherheitsmechanismen um den Zugriff auf die einzelnen Dokumente zu regeln.
Möchte man nun eine Enterprise-Search Applikation mit Solr umsetzen steht man vor eben dieser Herausforderung. Apache Solr kann „out-of-the-box“ nur SolrXML, JSON, CSV, Rich Content, Datenbanken und wenige Formate mehr. Dokumentbasierte Sicherheit, wie man sie bei einer Enterprise-Search erwartet, ist dabei noch nicht gegeben.
Der Herausforderung kann man nun auf unterschiedliche Weisen begegnen. Beispielsweise eigene Indexer Programme entwickeln oder auf bestehende zurückgreifen. Ersteres ist ein teurer und manchmal auch langwieriger Prozess. Crawling-Frameworks gibt es einige; eines jedoch sticht heraus. Nicht nur wegen der Fülle bestehender Konnektoren sondern auch weil es leicht mit Apache Solr integriert werden kann.
Fusion von Lucidworks ist zwar weit mehr als nur ein Connector-Framework, bietet jedoch unter anderem genau die Funktionalitäten die benötigt werden. Lucidworks Fusion hat neben den klassischen Datenquellen, wie „SharePoint“, „Dateisystem“, „Webseiten“ oder „Datenbank“, viele weitere, wie beispielsweise „JIVE“, „Twitter“, „Salesforge“, „Subversion“ oder „MongoDB“ und mit jedem Release kommen weitere hinzu. Die einzelnen Konnektoren bieten die Möglichkeit, die Dokumentberechtigung als Metainformation mit zu indexieren. Diese Funktionalität heißt bei Fusion „Security Trimming“ und kann sowohl während der Indexierung, als auch der Suche genutzt werden.
Fusion bringt zwar einen eigenen Apache Solr mit, der genutzt werden kann, jedoch lässt sich auch ein externer Solr oder sogar eine SolrCloud in Fusion integrieren. Hierzu müssen lediglich zwei kleine Schritte ausgeführt werden:
- Registrierung eines Solr/SolrCloud als „SearchCluster“ in Fusion
- Erstellung einer Collection mit dem neuen SearchCluster
Der erste Schritt ist momentan ein kleiner cURL Aufruf, der wie folgt aussieht:
curl -u user:passwort -X POST -H 'Content-type: application/json' -d '{"id":"mySolr", "connectString":"https://localhost:8984/solr", "cloud":false}' https://localhost:8764/api/apollo/searchCluster
Das obige Beispiel registriert einen einzelnen Solr unter dem Namen „mySolr“ in Fusion. Möchte man eine SolrCloud registrieren, müssen nur die Parameter „connectString“ und „cloud“ angepasst werden. Bei „connectString“ trägt man die URL zum ZooKeeper (Ensemble) ein und „cloud“ setzt man auf true.
Anschließend lässt sich der eben angelegte SearchCluster beim Anlegen einer neuen Collection auswählen. Hierzu muss der „Advanced“ Modus über den Schalter auf der rechten Seite aktiviert werden. Nun lässt sich, wie im folgenden Screenshot zu sehen ist, der externe Solr („mySolr“) über das Dropdown „Solr Cluster“ auswählen.
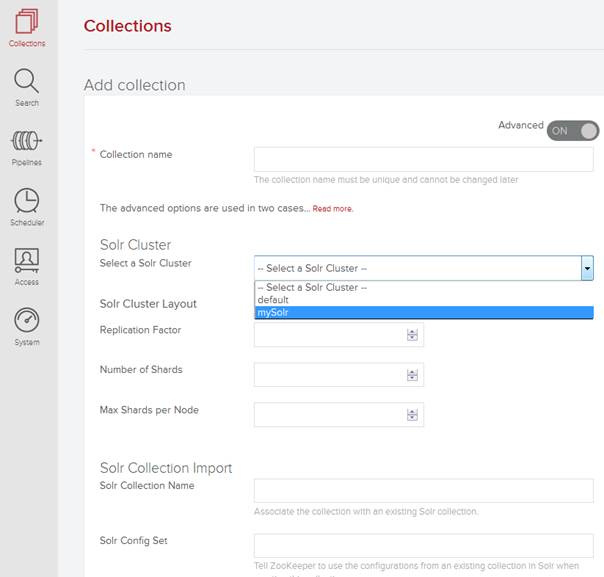
Wenn Sie außer dem „Collection Name“ und dem „Solr Cluster“ nichts weiter konfigurieren, dann wird ein neuer Index bzw. Collection angelegt. Sie können aber auch einen bereits bestehenden Index importieren. Hierzu müssen Sie unter dem Punkt „Solr Collection Import“ den Namen („Solr Collection Name“) angeben. In diesem Fall starten Sie nicht mit einem leeren Index, sondern können bereits indexierte Inhalte weiter verwenden.
Nach diesen beiden einfachen Schritten, haben Sie Ihre Solr Installation mit Ihrer Fusion Installation verbunden und können die volle Funktionalität von Fusion nutzen; u.a. auch das Connector Framework.
Fazit:
Das Produkt Fusion von Lucidworks bringt eine Fülle von Konnektoren mit, um die unterschiedlichsten Datenquellen für eine Enterprise-Search zu erschließen. Diese Konnektoren können auch die Berechtigungen der einzelnen Systeme mit in den Index aufnehmen und bei der Suche auswerten.
Die Integration einer bestehenden Solr Installation, sei es eine einzelne Instanz oder eine große SolrCloud, mit Fusion ist denkbar einfach und macht somit Fusion zum Produkt der Wahl, wenn man ein flexibles und erweiterbares Connector-Framework benötigt.


