

Elastic Enterprise Search
Elastic Enterprise Search ist eine neue Ergänzung des Elastic Stacks und ermöglicht Entwickler:innen und Teams die Erstellung suchgestützter Anwendungen mithilfe der Elasticsearch-Suchplattform. Mit einer abgestimmten Sammlung von Tools können Entwickler:innen spezialisierte Suchanwendungen für E-Commerce, Kundensupport, Workspace-Content, Websites oder andere Anwendungsfälle erstellen. Mit Elastic Enterprise Search können Unternehmen Daten und Informationen aus unterschiedlichsten Quellen konsolidiert recherchierbar machen.
Konnektoren
Entscheidend für Enterprise Search Anwendungen ist es, Informationen aus einer Vielzahl unterschiedlichster Datenquellen extrahieren zu können. Und genau dafür gibt es Konnektoren. Konnektoren ermöglichen die Einrichtung der automatisierten Synchronisierung von Daten zwischen Elasticsearch und dem Filesystem, Datenbanken oder Diensten wie Azure, Confluence, Dropbox, Jira und vielen mehr.
Elasticsearch bietet zwei Arten von Konnektoren an:
- Native Konnektoren: Konnektoren, die von Elasticsearch verwaltet werden und sofort für die Verwendung in der Unternehmenssuche verfügbar sind.
- Managed Konnektoren: Konnektoren, die individuell entwickelt werden können, einen Service ausführen und dann von der Enterprise Search genutzt werden können.
Die von Elastic Enterprise Search bereitgestellten benutzerdefinierten Konnektoren bieten endlose Möglichkeiten, die Indexierung von Daten aus beliebigen Quellen mit der Leistung von z.B. Python oder Ruby zu automatisieren. Es ermöglicht die freie Manipulation von Daten, bevor sie zur Erstellung leistungsstarker Analysen an Elasticsearch gesendet werden.
Erstellen des benutzerdefinierten Konnektors
In diesem Blog beschreiben wir alle Schritte, die zum Erstellen und Bereitstellen Ihres eigenen Managed Konnektors und zum Synchronisieren von Daten zwischen Ihrer Datenquelle und Elasticsearch erforderlich sind. Für dieses Tutorial erstellen wir einen Konnektor, der eine JDBC-Jar-Datei für eine Datenbank zusammen mit den Verbindungsdetails für die JDBC-Verbindung aufnehmen und Daten synchronisieren kann. Obwohl es einen direkten nativen MYSQL-Konnektor gibt, verwenden wir MYSQL als Datenbank für unsere JDBC-Verbindung.
Damit dies funktioniert, müssen drei Hauptkomponenten eingerichtet werden.
Elasticsearch mit Enterprise Search
Elastic Enterprise Search wird nicht mit Elasticsearch geliefert. Es muss separat installiert werden. Zur Vereinfachung verwenden wir Docker, um Elasticsearch, Kibana und Elasticsearch einzurichten. Eine Beispiel-Docker-Compose-Datei finden Sie hier: https://www.elastic.co/guide/en/enterprise-search/current/docker.html#docker-compose-example
Durch Ausführen eines Docker-Compose-Ups wird eine einfache Enterprise Search Deployment erstellt, mit der wir arbeiten können.
Navigieren Sie nach der Anmeldung bei Solr zu den Indizes in der Enterprise Search: http://0.0.0.0:5601/app/enterprise_search/content/search_indices
Klicken Sie auf „Create new index“. Wählen Sie dann „Konnektor“ als Aufnahmemethode. Hier sehen Sie neben den nativen Konnektoren auch die Option „Custom Konnektor“. Wenn Sie darauf klicken, wird die Schaltfläche „Continuer“ aktiviert. Wählen Sie auf der nächsten Seite einen Namen für Ihren Index, der die von MYSQL stammenden Daten speichert, und klicken Sie auf „Create Index“. Dadurch gelangen Sie direkt zur Seite „Configuration“ des Index. Der letzte Schritt besteht vorerst darin, auf „Generate API key“ zu klicken, um einen Schlüssel zu generieren, den unser Managed Konnektor-Client für die Verbindung mit Elasticsearch verwendet. Eine weitere Information, die für uns hier bereits sichtbar ist, ist „Konnektor_id“. Speichern Sie diese ID zusammen mit dem API-Key an einem sicheren Ort, da wir sie später verwenden werden. Elasticsearch wartet nun darauf, dass der Konnektor eine Verbindung herstellt.
Das Letzte, was wir vorerst von Elasticsearch benötigen, ist das Zertifikat, das erforderlich ist, um eine sichere Verbindung zwischen unserem Konnektor-Client und Elasticsearch herzustellen. Wenn Sie sich die Docker-Compose-Datei ansehen, die wir zuvor verwendet haben, finden Sie „Volumes“ im Service „es01“.
Eines der Volumes (certs:/usr/share/kibana/config/certs) definiert, wo das Zertifikat gespeichert wird. Kopieren Sie dieses Zertifikat mit dem Docker-Volume-Befehl vom Docker in den “config” ordner des Konnektor-Clients.
MYSQL Datenbank
Für unseren JDBC-basierten Datenabruf benötigen wir eine Datenbank. Wir richten eine MYSQL-Instanz ebenfalls mit Docker ein. Bitte beachten Sie, dass MYSQL nur dann zugänglich ist, wenn es sich im selben Netzwerk wie der Managed Client/Elasticsearch befindet und ein separater User in MYSQL erstellt werden muss. Auf MYSQL im Docker kann mit dem User „Root“ nicht zugegriffen werden. In unserem Fall haben wir einen Benutzernamen „elastic“ erstellt, den wir für die Verbindung zu MYSQL verwenden werden.
Wir haben eine Datenbank namens „Filme“ und eine Tabelle namens „Rezensionen“ erstellt. Die Tabelle „Bewertungen“ enthält Zeilen mit Attributen wie ID, Bewertung, Nachricht, Bild, Zeit usw. Die Bildspalte ist vom Typ BLOB.
Managed Konnektor Client
Das von Elasticsearch bereitgestellte Konnektor-Client-Framework ist ein guter Ausgangspunkt und ist unter https://github.com/elastic/Konnektors-python/ zugänglich.
Nach dem Klonen oder Herunterladen des Repositorys müssen wir die Konfiguration des Konnektors aktualisieren, um eine Verbindung zur Elasticsearch-Instanz herstellen zu können. Im “config” ordner finden Sie die Datei config.yml. Hier werden wir die folgenden Parameter aktualisieren:
host: https://es01:9200
username: elastic
password: yourpasswordhere
ssl: true
ca_certs: /app/config
verify_certs: false
Konnektor_id: Die Konnektor_ID, die beim Erstellen eines benutzerdefinierten Konnektors in der Unternehmenssuche bereitgestellt wird
service_type: jdbc (später erklärt)
api_key: Der API-Key, der beim Erstellen eines benutzerdefinierten Konnektors in der Unternehmenssuche bereitgestellt wird
Nachdem dies konfiguriert wurde, kann der Konnektor bereitgestellt werden. Von hier aus können Sie nun die vorhandenen von Elasticsearch bereitgestellten Konnektoren bereitstellen und verwenden oder Ihre eigenen Konnektoren erstellen. Für dieses Tutorial erstellen wir einen JDBC-Konnektor, der es uns ermöglicht, Elasticsearch mithilfe eines JDBC-Treibers mit jeder JDBC-fähigen Datenbank zu verbinden.
Im folgenden Pfad „Konnektors/sources/“ erstellen wir eine neue Datei namens jdbc.py und fügen den folgenden Eintrag zum Abschnitt „sources“ der config.yml hinzu
jdbc: Konnektors.sources.jdbc:JDBCDataSourceWir können jetzt unseren JDBC-Konnektor verwenden, indem wir ihn im Attribut „service_type“ in config.yml angeben, um Elasticsearch mitzuteilen, welchen Konnektor er verwenden soll.
In der Datei jdbc.py muss die Logik zum Abrufen von Daten aus der Datenbank und Konfigurations Parametern hinzugefügt werden. Sie können sich von vorhandenen Konnektoren wie der Datei mysql.py inspirieren lassen.
Bestimmte Funktionen wie „validate_config“, „get_docs“, „__init__“, „get_default_configuration“ müssen für Elasticsearch implementiert werden, um die Konnektor-Konfiguration zu validieren und Dokumente abzurufen.
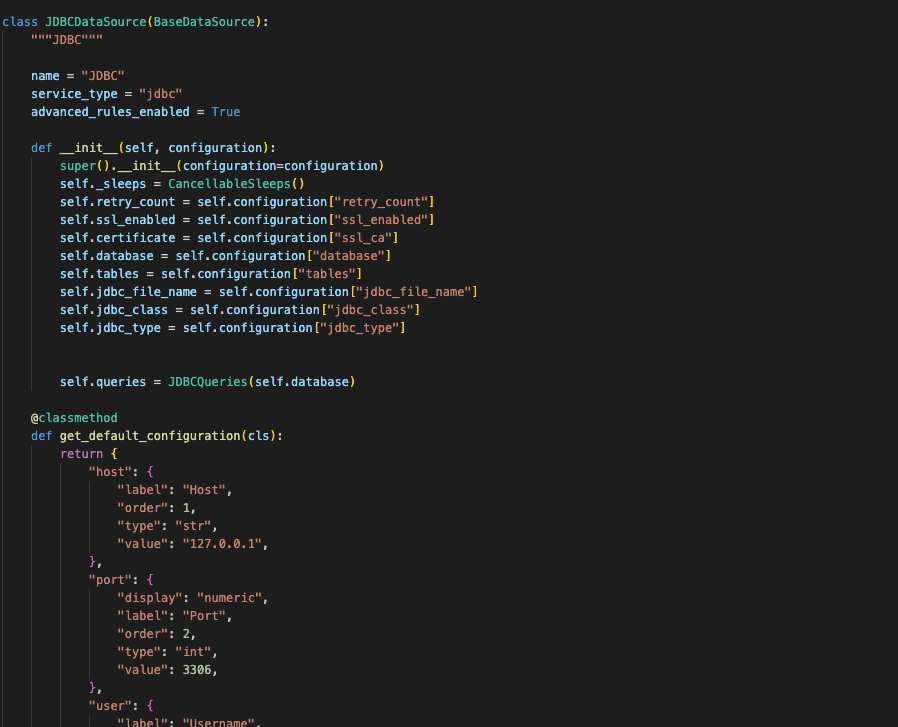
Damit wir Parameter an den Konnektor übergeben können, können wir Parameter wie folgt zur get_default_configuration hinzufügen:
Das Framework muss dann entweder über ein Makefile oder Docker bereitgestellt werden. Für dieses Tutorial verwenden wir Docker. Eine ausführlichere Erklärung zur Bereitstellung des Konnektors mithilfe von Docker finden Sie hier:
https://github.com/elastic/Konnektors-python/blob/main/docs/DOCKER.md
In diesem Fall müssen zwei Hauptbefehle ausgeführt werden:
docker build -t Konnektor/custom-jdbc:1.0 .
docker run \
-v ~/Users/arsaljalib/Documents/bwi/Konnektors-python/config:/config \
--network "enterprisesearch_default" \
--tty \
--rm \
Konnektor/custom-jdbc:1.0 \
/app/bin/elastic-ingest
Sobald das Framework erfolgreich bereitgestellt wurde, versucht es, eine Verbindung zu Enterprise Search herzustellen. Bei Erfolg akzeptiert Enterprise Search die Verbindung und fragt nach den Konfigurationsparametern.
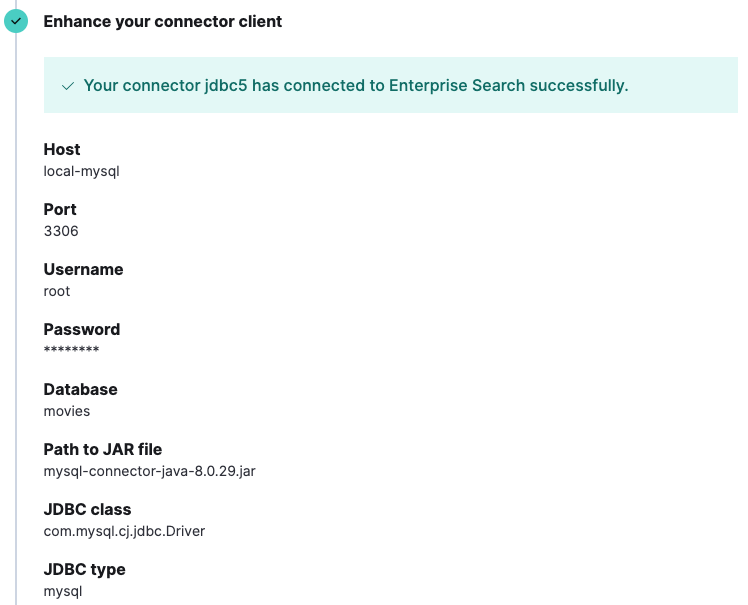
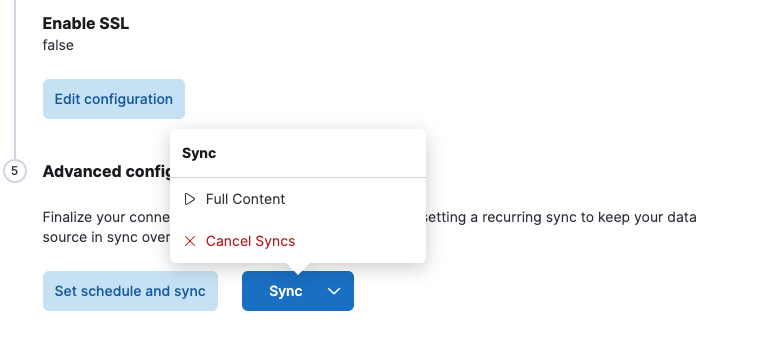
Durch das Speichern der Konfiguration wird die Schaltfläche “Sync“ aktiviert. Anschließend können Sie auf „Full Content“ klicken, um Daten aus Ihrer Datenbank abzurufen und in Elasticsearch indexieren zu lassen. Die Dokumente können direkt im Dokumentenbereich des Index eingesehen werden.
Nächste Schritte
Konnten Sie der Anleitung folgen und hat alles funktioniert? Wir freuen uns über Ihr Feedback und sprechen gerne mit Ihnen darüber, wie sie weitere Datenquellen in Elasticsearch anbinden können. Buchen Sie einfach direkt einen Termin für einen ersten, unverbindlichen Austausch.


