

In einem früheren Blog habe ich einen kurzen Einblick in Apache Stanbol und Named Entity Recognition (NER) gegeben. Die gezeigte Oberfläche war der Stanbol Enhancer. Er ist dafür zuständig, Entitäten im Fließtext zu erkennen.
In diesem Beitrag will ich etwas näher auf den sogenannten Contenthub eingehen, der ebenfalls Teil von Apache Stanbol ist. Der Contenthub besteht aus zwei Komponenten: Store und Search. Wie die Namen bereits verraten, ist Store für die persistente Datenspeicherung zuständig und Search für die Suche. Führt man den full launcher aus (nicht den stable launcher!), wird im Hintergrund ein Solr Server gestartet. Dieser dient gleichermaßen zur Speicherung angereicherter Daten als auch zur Suche in diesen Daten.
Wird ein Dokument über den Stanbol Contenthub erstellt, wird dessen Inhalt an den Stanbol Enhancer übergeben. Dieser ist dafür zuständig, diesen Inhalt mit Metadaten anzureichern. Dieser Prozess wird auch Enhancement genannt. Optional besteht die Möglichkeit, externe Daten hinzuzufügen. Schließlich wird das Dokument zusammen mit den Metadaten in einem Solr Core indexiert.
Diesen Prozess kann man auch über die grafische Oberfläche, die beim full launcher mitgeliefert wird, nachvollziehen. Diese Schritte werden im folgenden Abschnitt dargelegt:
Apache Stanbol herunterladen
Laden Sie sich hierfür zunächst den full launcher von Apache Stanbol herunter.
Ausführen des full launchers
java -Xmx1g -XX:MaxPermSize=256m -jar org.apache.stanbol.launchers.full-{snapshot-version}-SNAPSHOT.jar
Es ist von äußerst wichtiger Bedeutung, dass Sie nicht vergessen, diesen Launcher mit einer PermSize von mindestens 256MB zu starten. Bei weniger zugewiesenem Speicher, werden Sie abgesehen von OutOfMemoryExceptions nicht viel in Ihrer Konsole bzw. Eingabeaufforderung sehen.
Anschließend können Sie über einen Browser Ihrer Wahl https://localhost:8080/contenthub aufrufen. Das Fenster sollte ähnlich Abbildung 1 aussehen.
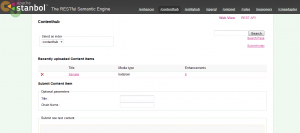
Anlegen eines Datensatzes
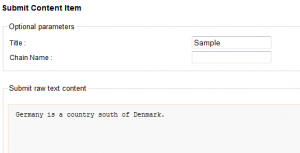
Nun können Sie unter Submit Content Item einen Datensatz anlegen. Ein Datensatz wird in der Apache Stanbol Terminologie auch Content Item genannt. Vergeben Sie einfach einen Titel und schreiben einen kurzen Beispieltext. Dieser sollte nach Möglichkeit auch über eine oder mehrere Entitäten verfügen, damit die volle Stärke von Apache Stanbol zur Geltung kommt. Als einfaches Beispiel wähle ich den Titel Sample und einen einfachen Inhalt: Germany is a country south of Denmark. Vergleichen Sie hierzu Abbildung 2.
Nachdem Sie den Text mit Submit Text abgeschickt haben, erscheint nach kurzer Wartezeit bereits eine Weltkarte, auf der die beiden Länder Dänemark und Deutschland markiert sind. Ebenso sind die beiden gefundenen Entitäten separat aufgeführt. Nun befindet sich bereits ein Datensatz im Contenthub bzw. im Solr Index. Vergleichen Sie hierzu Abbildung 3.
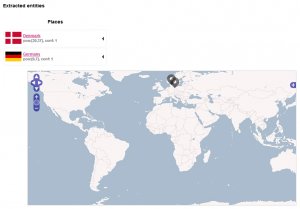
Suche
Navigieren Sie wieder zum Contenthub (https://localhost:8080/contenthub), um die Suchfunktion zu testen. Auf der rechten Seite befindet sich ein Suchschlitz. Geben Sie nun beispielsweise denmark oder germany ein und suchen danach. Nun sollte genau der von Ihnen hinzugefügte Datensatz in der „Trefferliste“ auftauchen, ebenso wie alle Entitäten im Index – aufgereiht in der linken Spalte. Klicken Sie auf den Treffer, sehen Sie wieder die Weltkarte von vorhin.
Fazit
In wenigen Schritten kann also auch Open Source Spaß machen und Ergebnisse liefern. Apache Stanbol ist ein Paradebeispiel dafür, dass Open Source nicht gezwungenermaßen stundenlange Konfiguration bedeutet, bis sich auf dem Bildschirm etwas tut. Natürlich zeigt der beschriebene Weg nicht alle Möglichkeiten von Apache Stanbol auf, denn die Software kann natürlich viel mehr als hier gezeigt wurde. Aber er zeigt einen Ausschnitt, der einfach zu bedienen ist, kein technisches Wissen voraussetzt und für einfache prototypische Testzwecke verwendet werden kann.


