

Das Release 6.0 von Apache Solr ist nun seit kurzem veröffentlicht. Mit dieser Version gibt es einige neue Funktionalitäten, aber auch einige teils gravierende Änderungen bestehender Funktionalitäten. Eine dieser Änderungen betrifft das Scoring. In Solr 6.0 ist der Default des Scoring-Mechanismus von der TF-IDF-Berechnung auf BM25 umgestellt worden.
Im Januar hat meine Kollegin Patricia Kaufmann bereits von diesen Änderungen berichtet. In diesem Blog möchte ich tiefer einsteigen und aufzeigen was genau sich ändert und wie man das Scoring bereits heute ändern kann.
Wie funktioniert der BM25
Schaut man sich die Formel für die BM25 Ranking-Funktion an und vergleicht ihn mit der Formel des bisher genutzten Scorings fällt auf, dass sie aus weniger Faktoren besteht. Folgende Grafik ist aus der Wikipedia entnommen und beschreibt die Berechnung.
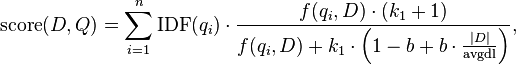
In Worten bedeutet diese Formel, dass für eine Suchanfrage Q der Score für ein Dokument D wie folgt berechnet wird: Pro Suchterm wird dessen inverse Dokumentenfrequenz (IDF) mit einer Variante der Termfrequenz (TF) dieses Suchterms multipliziert. Besteht die Suchanfrage aus mehreren Termen, werden die einzelnen Werte anschließend aufsummiert.
Ähnlich funktioniert die bisher verwendete Scoring-Formel auch. Auch beim klassischen TF-IDF Algorithmus werden Einzelwerte bestehend u.a. aus TF * IDF gebildet und zusammenaddiert.
Aber wie so oft steckt der Teufel im Detail. Schauen wir uns zuerst die Termfrequenz an. Die Berechnungsvorschiften für den TF unterschieden sich stark voneinander. Dies lässt sich gut in folgendem Bild nachvollziehen.
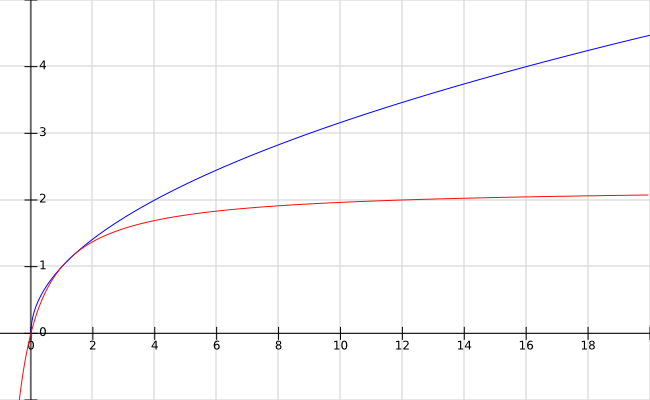
In der obigen Abbildung sind die Werteverläufe der TF für die bisherige (blau) sowie für die BM25-Berechnung (rot) dargestellt. Folgende Formeln wurden hierfür genutzt:
Rot (BM25) f(x)=((1.2 + 1) * x)/(1.2 + x)
Blau (Classic TF-IDF) f(x)=√x
Eines fällt bei der TF besonders ins Auge: Der Maximalwert des BM25 geht nicht gegen Unendlich, sondern nähert sich einer Obergrenze an. Für das Scoring bedeutet dies, dass der Einfluss der Häufigkeit eines Terms bei hochfrequenten Termen weniger stark ins Gewicht fällt. Es ist jedoch weiterhin sehr relevant ob ein Begriff einmal oder fünfmal vorkommt. Ob er aber zehn oder 20 Mal vorkommt, ist ein weniger wichtiger Faktor.
Die Berechnung der TF kann durch Paramater beeinflusst werden. Im obigen Beispiel wurden der Einfachheit halber die Standardwerte genutzt.
Beim zweiten Bestandteil, der IDF, ist der Unterschied nicht so gravierend, wie in der folgenden Abbildung zu sehen ist.
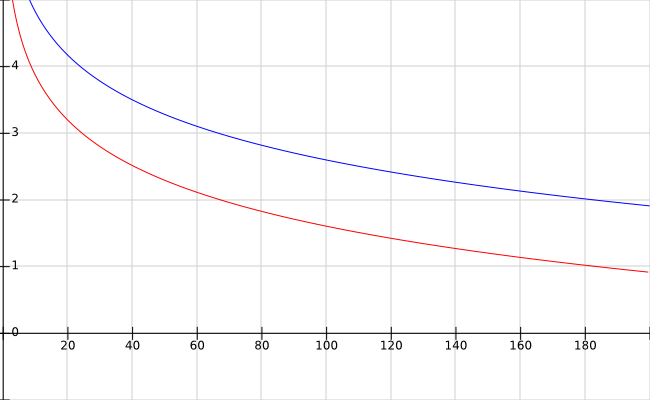
Die Werteverläufe der IDF für die bisherige (blau) sowie für die BM25-Berechnung (rot) sind dargestellt. Folgende Formeln wurden hierfür genutzt.
Rot (BM25) f(x)= log(1+(10 – x + 0,5)/(x + 0,5))
Blau (Classic TF-IDF) f(x)=1+ log(10/(x+1))
Anmerkung: Als Logarithmus wird intern der natürliche Logarithmus (ln(x)) verwendet.
Der Verlauf beider Grafen ist in etwa identisch nur liegt der Wert der klassischen IDF etwa 1 über dem Wert der IDF des BM25.
Klassischer TF-IDF vs. BM25
Schaut man sich die obige Beschreibung des BM25 an, erkennt man Teile (TF, IDF) aus der bisherigen Scoring-Formel wieder. Was sind denn nun aber die Unterschiede zwischen den beiden Varianten?
- TF – Die TermFrequency verliert je öfter ein Wort vorkommt an Gewichtung.
- IDF – Die IDF wird ähnlich berechnet. Da in der bisherigen Berechnung des IDF zum Logarithmus eine 1 addiert wird, unterscheiden sich beide Werte immer um etwa 1.
- Längen-Normalisierung – Bisher konnte man den Einfluss der Länge des Felder entweder aktivieren oder deaktivieren. Mit dem BM25 kann man fein granular einstellen wie stark der Einfluss ist. Des Weiteren ist die Längen-Normalisierung mehr vom jeweiligen Feld abhängig, da in die Berechnung die durchschnittliche Länge des Feldes berücksichtigt wird.
- Koordinationsfaktor (coord) – Der BM25 Algorithmus hat keinen Koordinationsfaktor mehr. Dies bedeutet, dass Dokumente nicht mehr zusätzlich „bestraft“ werden, wenn sie nicht alle Suchbegriffe enthalten.
- Query-Normalisierung (QueryNorm) – In der Berechnung des BM25 findet keine Query-Normalisierung mehr statt. Damit fällt ein Faktor in der Berechnung weg, die bisher immer schwer nachzuvollziehen war.
Scoring in Solr ändern
Das Scoring in Solr zu ändern bedarf nur einer kleinen Konfiguration in der schema.xml. Die Möglichkeit die Scoring-Methode zu ändern gibt es bereits seit Solr 4.0 und auch der BM25 ist bereits seit dieser Versionen implementiert. Daher können wir bereits mit älteren Solr Versionen testen, was mit Apache Solr 6 auf uns zukommt.
Grundlegend gibt es folgende zwei Möglichkeiten, wie man den Scoring-Mechanismus ändern kann.
Variante 1: globale Änderung des Scorings
Um einen anderen Scoring-Mechanismus einzubinden, der auf alle Felder Auswirkung hat, muss ein similarity-Element in der schema.xml eingebunden werden. Folgender Ausschnitt der schema.xml zeigt, wie der BM25 global verwendet werden kann:
<schema>
...
<similarity class="solr.BM25SimilarityFactory"/>
...
</schema>Variante 2: Feldtypen-abhängige Änderung des Scoring-Algorithmus
Es gibt Situationen, da möchte man nur für einzelne Felder das Scoring-Verhalten ändern bzw. anpassen. Solr bietet hierfür die Möglichkeit, den Scoring-Mechanismus einzelner Feldtypen zu ändern. Hierzu muss zum einem ein similarity-Element innerhalb der Feldtypen-Definition integriert werden und als globale Einstellung für das Scoring-Verhalten muss die „SchemaSimilarityFactory“ definiert werden.
Folgendes Beispiel zeigt, wie für den Feldtypen „text_bm25“ der BM25 Scoring Algorithmus konfiguriert wird:
<schema>
...
<fieldType name="text_bm25" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<similarity class="solr.BM25SimilarityFactory"/>
</fieldType>
...
<similarity class="solr.SchemaSimilarityFactory"/>
...
</schema>Fazit
Der BM25 Scoring-Mechanismus ist kein Hexenwerk. Grundlegend basiert er auch auf einer Berechnung von TF und IDF. Aber der BM25 bietet gegenüber dem bisherigen Scoring mehr Konfigurationsmöglichkeiten.
Bei meinen ersten Test hat sich für mich positiv herausgestellt, dass ich nun über die Parameter die Längennormalisierung beeinflussen kann. Des Weiteren ist der „explain“-Output eines Solr-Response leichter zu lesen, wodurch das Relevanz-Tuning erleichtert wird.
Da Apache Solr mit der Version 6.0 das Scoring mittels BM25 als Default einführt, ist zu empfehlen, diesen rechtzeitig zu testen. Vor allem da der BM25 andere Score-Werte berechnen wird und somit möglicherweise alle konfigurierten Boost-Einstellungen nicht mehr gewünscht funktionieren und ggf. nachjustiert werden müssen.


