

Teil 4 der Blogserie:

Lesen Sie hier die anderen Beiträge der Blogserie:
- Teil 1 „Mit digitalen Assistenten zur gelungenen Customer Experience“
- Teil 2 „How To: einen Chatbot mit Open Source implementieren“
- Teil 3 „Wenn der Chatbot nicht mehr weiter weiß. Wie Sie die Grenzen herkömmlicher virtueller Assistenten überwinden“
- Teil 5 „Smart Answers in, Smart Answers out: Der finale Step zum intelligenten Chatbot“
Im vorherigen Teil der Serie ging es um die Schwächen herkömmlicher Chatbot-Systeme: sei es bei der semantischen Suche, bei Personalisierung oder dabei, Datensilos aufzulösen. Genau für diese Probleme liefert unser Partner Lucidworks mit Smart Answers eine Lösung.
Wie Smart Answers aufgesetzt und konfiguriert werden kann, zeigen wir in diesem Beitrag. Im nächsten und letzten Teil der Reihe befassen wir uns dann mit der Anbindung von Smart Answers an eine Chatbot-Plattform – in unserem Fall Rasa.
Was ist Smart Answers?
Smart Answers ist ein Bestandteil der intelligenten Such-Plattform Lucidworks Fusion. Diese kombiniert die Open-Source-Suchmaschine Apache Solr mit dem Open-Source-Cluster-Computing-Framework Apache Spark, das schnell und leistungsfähig große Mengen an Daten verarbeiten kann. Apache Spark bringt auch die nötige KI-Power ins Spiel, denn damit werden Machine-Learning-Modelle trainiert und angebunden. Außerdem ist Milvus in Fusion integriert, eine Vektordatenbank für skalierbare Ähnlichkeitssuche. Genau diese Ähnlichkeitssuche kommt bei Smart Answers zum Einsatz.
Smart Answers funktioniert folgendermaßen: Der User-Input, eine Frage, wird durch ein Machine-Learning-Modell in Vektoren überführt. In Fusion haben wir Inhalte geladen, unsere potenziellen Antworten. Auch diese wurden mithilfe des Machine-Learning-Modells in Vektoren encodiert. Wir können nun den Frage-Vektor mit allen Antwort-Vektoren abgleichen und den „ähnlichsten“ Antwort-Vektor finden. Die zugehörige Antwort wird dann an den User zurückgeben.
Durch den Einsatz des Machine-Learning-Modells werden passende Antworten nicht nur durch simples Keyword-Matching gefunden. Stattdessen wird die Bedeutung der Wörter „verstanden“ und berücksichtigt. Dieses „Verstehen“ ist natürlich Gold wert. Schließlich wird kaum ein Mensch mit seiner Frage exakt die in der Antwort enthaltenen Begriffe treffen.
Übrigens bietet Fusion neben Smart Answers auch weitere Features, die uns für unseren Chatbot nützlich sein können. Etwa kann man damit sogenannte „Signals“ nutzen, um dem User ein personalisiertes Erlebnis zu bieten und so die Customer Experience zu optimieren. In dieser Anleitung werden wir uns aber erst einmal auf Smart Answers beschränken.
Nach diesem Einblick in Smart Answers und Fusion starten wir nun mit dem Set-up von Smart Answers.
Aufsetzen von Smart Anwers
Ich nutze in diesem Blogbeitrag Fusion in der Version 5.5, die folgende Anleitung sollte allerdings ab Fusion 5.3 gültig sein.
Fusion 5 hat eine moderne Cloud-native Microservices-Architektur, die von Kubernetes orchestriert wird und kann beispielsweise mit Google Kubernetes Engine (GKE), Azure Kubernetes Service (AKS) oder Amazon Elastic Kubernetes Service (EKS) betrieben werden.
Wir gehen hier von einem bereits gestarteten Fusion Cluster aus. Wer diesen Schritt noch vor sich hat, dem gelingt das Deployment unkompliziert mit den Set-up Skripten, die Lucidworks mitliefert (zum Beispiel die Lucidworks Dokumentation für AKS ) Das Set-up von Smart Answers gelingt dann unkompliziert über Fusions UI, auf die man über seinen Browser zugreifen kann. Im ersten Schritt müssen wir eine Fusion App erstellen.
Erstellen einer Fusion-App
Auf Fusions Startseite, dem sogenannten „Launcher“, wählen wir unter Add new app den Punkt Create new app. Wir setzen als Namen demo, und bestätigen mit Create App. Durch einen Doppelklick auf die neu erstellte App, öffnen wir diese. Wir werden nun als nächstes eine Milvus-Collection erstellen.
Erstellen einer Milvus-Colletion
DaMilvus ist eine Suchmaschine für Vektorähnlichkeit. Sie wurde in Fusion integriert, um dessen Deep-Learning-Funktionen zu optimieren und semantische Suche zu ermöglichen. Milvus speichert die vom Machine-Learning-Modell erzeugten Vektoren in einer oder mehreren sogenannten Milvus-Collections. Eine solche Collection müssen wir daher zunächst in Fusion bereitstellen. Wir führen dazu die folgenden Schritte aus.
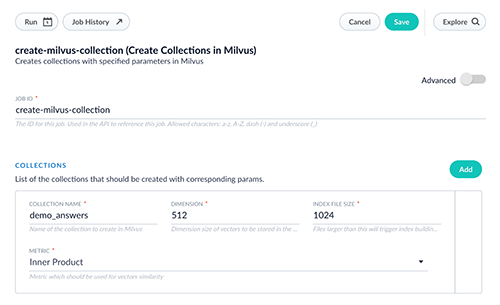
- Wir navigieren zu Collections > Jobs > Add + und wählen Create Collections in Milvus.
- Wir konfigurieren den Job, siehe auch untenstehenden Screenshot:
- Wir vergeben eine ID, etwa create-milvus-collection.
- Unter Collections, klicken wir Add.
- Wir wählen einen Collectionnamen, etwa demo_answers.
- Wir setzen die Dimension. Für das vortrainierte Cold-Start-Modell ist der korrekte Wert 512.
- Die restlichen Parameter können auf dem Standard belassen werden.
- Mit Save speichern wir den Job und starten ihn mit Run > Start.
Sobald ein Sonnensymbol erscheint, wurde der Job erfolgreich durchgeführt und die Milvus-Collection steht bereit.
Bereitstellen des Cold-Start-Modells
Um die Fragen und Antworten in Vektoren zu encodieren und damit die semantische Ähnlichkeit angleichen zu können, kommt ein Machine-Learning-Modell zum Einsatz. Smart Answers bietet hier neben der Möglichkeit, eigens trainierte Modelle zu nutzen auch ein Cold-Start-Modell an. So kann man auch ohne eigene Trainingsdaten und ohne der sonst nötigen KI-Expertise durchstarten.
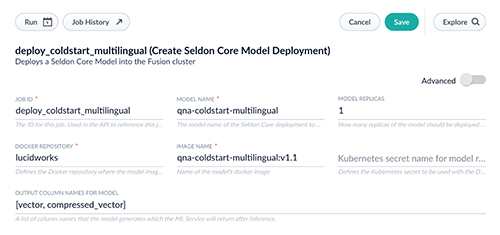
- Wir gehen zu Collections > Jobs > Add + und wählen Create Seldon Core Model Deployment.
- Wir konfigurieren den Job folgendermaßen, siehe auch untenstehenden Screenshot:
- Wir setzen eine Job ID, etwa
deploy-coldstart-multilingual. - Wir geben den Modellnamen an, etwa
qna-coldstart-multilingual. - Als Docker Repository setzen wir
lucidworks. - Im Feld Image Name setzen wir
qna-coldstart-multilingual:v1.1 - Das Feld Kubernetes Secret Name for Model Repo kann leer bleiben.
- Als Output Column Names for Model setzen wir
[vector, compressed_vector].
- Wir setzen eine Job ID, etwa
- Wir speichern mit Save und starten den Job mit Run > Start.
Es kann dann einen kurzen Moment dauern, bis der Job durchgelaufen ist und das Modell bereit ist. Auch hier zeigt ein Sonnensymbol Erfolg an.
Konfigurieren des Parsers und der Index Pipeline
Nun müssen wir die möglichen Antworten in Fusion laden, die Smart Answers dann mit dem eben bereitgestellten Machine-Learning-Modell encodiert. Wir werden hier für Demo-Zwecke einfach ein CSV laden. Dieses enthält zwei Spalten: eine Spalte „answer_t“, welche die Antworttexte enthält und eine Spalte „id“, welche die Antworten durchnummeriert. Für ein produktives Set-up bietet Lucidworks über 800 sogenannte Konnektoren, um Inhalte aus ganz verschiedenen Datenquellen und Systemen in Fusion zu indexieren und so Datensilos aufzulösen.
Daten, die in Fusion geladen werden, werden stets zunächst durch einen Parser und anschließend durch eine Index Pipeline verarbeitet. Der Parser ist für das „Grobe“ zuständig und erkennt etwa in unserem Fall die Struktur des CSV und kann diese verarbeiten. Die Index Pipeline nimmt weitere Transformationen an den Daten vor, in unserem Fall unter anderem die Encodierung in Vektoren, die wir für die semantische Suche benötigen. Konfigurieren wir zunächst den Parser.
Wir führen dazu die folgenden Schritte aus:
- Wir navigieren zu Indexing > Parsers.
- Hier gibt es bereits einen Parser mit dem Namen unserer App, also demo. Diesen werden wir verwenden, passen ihn aber noch geringfügig an.
- Bei den generellen Einstellungen setzen wir als Document ID Source Field id.
- Wir setzen in der CSV Parser Stage den richtigen Delimiter (etwa ein Semikolon) und behalten ansonsten die Standardeinstellungen.
- Alle anderen Stages können so belassen werden wie sie sind, da sie für ein CSV keine Anwendung finden.
- Wir speichern mit Save.
Nun zur Index Pipeline.
- Wir gehen zu Indexing > Index Pipelines
- Hier gibt es bereits eine <appname>-smart-answers Pipeline, auf der wir aufbauen können. Wir klicken auf diese.
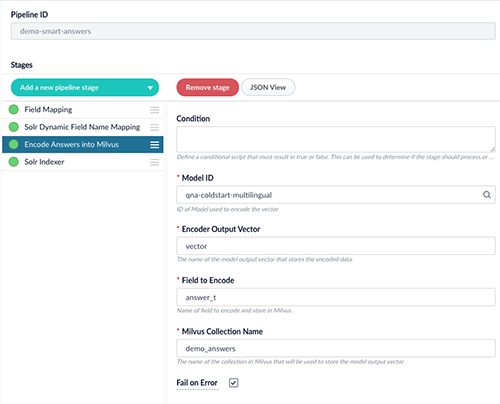
- Hier muss nur die Encode into Milvus Stage konfiguriert werden, siehe auch untenstehenden Screenshot:
- Optional kann ein Label vergeben werden, etwa Encode answers into Milvus.
- Wir setzen die Model ID auf den Wert, der bei Bereitstellen des Cold-Start-Modells gesetzt wurde, hier qna-coldstart-multilingual
- Wir tragen ins Feld Field to Encode dasjenige Feld ein, das in Vektoren encodiert werden soll, hier answer_t.
- Es muss sichergestellt sein, dass der Encoder Output Vector mit dem Output-Vektor des gewählten Modells übereinstimmt, hier vector.
- Der Milvus Collection Name muss mit dem Namen der Collection übereinstimmen, die wir oben bereits erstellt haben: demo_answers
- Fail on Error kann für einfacheres Debuggen aktiviert werden.
- Wir klicken Save, um die Pipeline zu speichern.
Laden von Daten
Der eben konfigurierte Parser und die Index Pipeline können nun genutzt werden, um die Dokumente in Fusion zu “indexieren”, also zu laden. Dazu erstellen wir einen Job zum File-Upload.
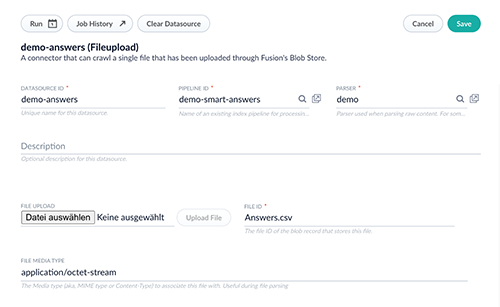
- Wir navigieren zu Indexing > Data Sources > Add +
- Wir wählen File Upload
- Diesen File Upload Job konfigurieren wir nun, siehe auch untenstehenden Screenshot:
- Wir setzen eine Datasource ID, etwa demo-answers.
- Als Pipeline ID setzen wir die eben erstellte Index Pipeline, hier demo-smart-answers.
- Als Parser setzen wir den eben erstellten Parser, hier demo.
- Wir klicken dann Datei auswählen, wählen die zu indexierende Datei und bestätigen mit Upload File. Der Name der Datei sollte nun im Feld File ID erschienen sein.
- Wir speichern mittels Save und starten den Prozess mit Run > Start.
Ist der Job durchgelaufen, stehen die Daten nun in Fusion zur Verfügung und können durchsucht werden. Dazu nutzen wir eine sogenannte Query Pipeline.
Konfiguration der Query Pipeline
Die Query Pipeline legt die Schritte fest, welche die User-Frage durchläuft, wenn sie mit den Daten in Fusion abgeglichen wird. Dies ist in unserem Fall vor allem die Encodierung in einen Vektor und der Abgleich mit den Antwort-Vektoren in Milvus.
- Wir navigieren zu Querying > Query Pipelines.
- Hier gibt es bereits eine <appname>-smart-answers Pipeline, auf der wir aufbauen können. Wir klicken auf diese. Es müssen zwei der Stages angepasst werden.
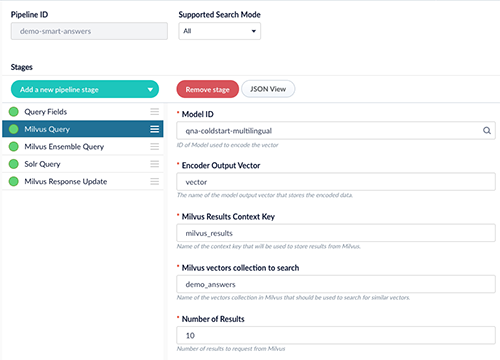
- Wir konfigurieren zunächst die Milvus Query Stage, siehe auch untenstehenden Screenshot:
- Wir setzen Model ID auf den Wert des Modells, das bei der Bereitstellung des Cold-Start-Modells gewählt wurde, hier qna-coldstart-multilingual.
- Der Encoder Output Vector muss mit dem Output-Vektor des gewählten Modells übereinstimmen, hier vector.
- Der Milvus Collection Name muss mit dem Namen der Collection übereinstimmen, die wir oben bereits erstellt haben, hier demo_answers.
- Milvus Results Context Key kann auf den Standardwert belassen werden. Er wird in der Milvus Ensemble Query Stage genutzt, um den Gesamtscore der Query zu berechnen.
- Wir konfigurieren bei Bedarf die Milvus Ensemble Query Stage:
- Wenn gewünscht kann der Ausdruck unter Ensemble math expression geändert werden, um die Berechnung des Gesamtscores anzupassen.
- Ab Fusion 5.4 kann auch ein Schwellenwert hinterlegt werden, sodass die Milvus Ensemble Query Stage nur Elemente mit einer Punktzahl zurückgibt, die größer oder gleich dem konfigurierten Wert ist.
- Speichere die Query-Pipeline mit Save.
Austesten in der Fusion UI
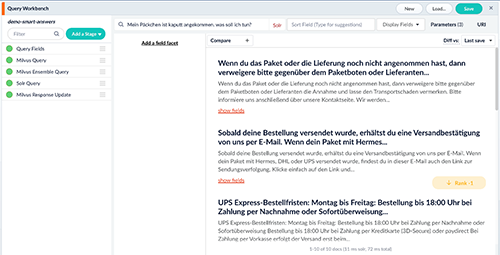
Möchten wir Smart Answers direkt austesten, können wir das mittels der Query Workbench. Diese erreichen wir unter Querying > Query Workbench. Durch Klicken auf Load… laden wir hier die Query Pipeline demo-smart-answers, die wir eben konfiguriert haben.
In den Suchschlitz können wir nun unsere Frage eingeben, beispielsweise „Mein Päckchen ist kaputt angekommen. Was soll ich machen?“ Smart Answers findet hier die richtige Antwort, siehe untenstehenden Screenshot. Bemerkenswert ist hierbei, dass in der Antwort weder „Päckchen“ noch „kaputt“ enthalten ist. Eine normale Keywordsuche hätte die richtige Antwort also nicht gefunden. Smart Answers jedoch konnte durch sein Deep Learning Modell die „Bedeutung“ erfassen und kann trotz der fehlenden Stichwörter die richtige Antwort liefern.
In der Query Workbench unter URI den der Query entsprechenden API-Call erhalten. Solche API-Calls werden wir im nächsten Beitrag nutzen, um mit Rasa Fusion bzw. Smart Answers aufzurufen.
Wie wir nun die Antworten, die Smart Answers liefert, durch einen Chatbot ausgeben lassen können, sehen wir im nächsten Blogbeitrag.


