

Jump into the Zeppelin
Sie sehen sich vor einem Berg kryptisch formulierter Log-Daten stehen, aus denen Informationen nur schwer zu extrahieren sind? Sie haben eine Idee zur Optimierung Ihrer Systeme, aber wissen nicht, wie Sie diese verifizieren und präsentieren können? Oder wollen Sie einfach mal herausfinden, welche Features Sie in Ihren Online-Shop einbauen könnten? Dann schnappen Sie sich eine Banana, springen Sie in den Zeppelin, browsen Sie durch Graphen und sehen Sie Garbage aus einer anderen View! Wie das geht, was das bringt und wem das hilft, erfahren Sie hier.
Im zweiten Teil der Blogreihe werden wir uns mit einem heutzutage eher ungewöhnlichen Fortbewegungsmittel befassen, das in der Data Analytics Welt 2015 ein brausendes Comeback gefeiert hat: Zeppelin ab!
Apache Zeppelin ist ein Top-Level-Projekt der Apache Software Foundation und ist als ein weiteres mächtiges Open Source Tool frei und kostenlos einsetzbar. Zeppelin selbst stellt sich vor als web-basiertes Notebook zur interaktiven, daten-getriebenen Analyse mit SQL, Scala und vielen mehr (https://zeppelin.apache.org/). Mit diesen „vielen mehr“ sind im Kontext von Apache Zeppelin verschiedene Interpreter gemeint, die dem Nutzer die Eingabe von Befehlen in mehreren Formaten erlauben, darunter: Spark, JDBC, Pig, Python, HBase, Angular und PostgreSQL. Zeppelin interpretiert die Nutzereingabe je nach definiertem Interpreter, erfasst die angesprochenen Daten und bietet diverse Visualisierungsmöglichkeiten an.
Um Apache Zeppelin mit Solr zu nutzen, muss Ihre Solr-Installation die folgenden Kriterien erfüllen:
• Verwendung des SolrCloud-Modus
• Verwendung von Solr in Version 6.0.0 oder höher
• Daten, welche abgefragt werden sollen, müssen inklusive docValues abgelegt sein
In Solr 6.0.0 wurde eine SQL-Schnittstelle eingeführt, welche die Basis zur Kommunikation mit Zeppelin bildet. Diese ermöglicht das Abfragen der in Solr gespeicherten Daten über SQL-Syntax, sodass Solr über einen JDBC-Treiber in gleicher Form wie eine relationale Datenbank angesprochen werden kann.
Let Zeppelin fly!
Zeppelin kann über die offizielle Projekt-Seite heruntergeladen werden. Es sei an dieser Stelle angemerkt, dass Zeppelin nicht für die Benutzung auf Windows-Systemen ausgelegt ist, weshalb die Installation und Inbetriebnahme sich in Linux-basierten Systemen sehr viel einfacher gestaltet. Die Bereitstellung eines Scripts zum Starten von Zeppelin (bin/zeppelin.sh start) erspart Ihnen langjährige Besuche einer Flugschule und lässt Sie ohne umfangreiche Sicherheitseinweisung, Sehtest oder Rangabzeichen die Datenseen von oben betrachten.
Aber genug der Metaphern, denn Sie wollen schließlich Ihre Daten nicht nur ansprechen, sondern vor Allem analysieren und visualisieren. Der Solr Reference Guide stellt hierzu eine schrittweise Anleitung für das Erstellen eines Solr-Interpreters bereit, der für spätere Zeppelin-Notebooks als Schnittstelle zu Ihrer SolrCloud genutzt werden kann. Die wesentlichen Schritte sind dabei:
1. Einen neuen Interpreter auf Basis des JDBC-Interpreters anlegen
2. Die Solr- bzw. ZooKeeper-URL und den Namen der Collection hinterlegen (default.url=jdbc:solr://localhost:9983?collection=ZeppelinCollection)
3. Den passenden Treiber definieren (default.driver=org.apache.solr.client.solrj.io.sql.DriverImpl)
4. Die SolrJ-Library (org.apache.solr:solr-solrj:6.x.x) als Dependency einbinden
Sobald Sie der Anleitung gefolgt sind, können Sie Solr über %Ihr_Interpreter_Name über Zeppelin ansprechen.
Paragraphenzeichner
Zeppelin ist, wie bereits angedeutet, über sogenannte Notebooks organisiert. In jedem Notebook können beliebig viele Paragraphen platziert werden. Durch Angabe des jeweiligen Interpreters und dazu passender Code-Zeilen werden auf Knopfdruck die Daten geladen und können daraufhin dynamisch für die Anzeige aufbereitet werden.
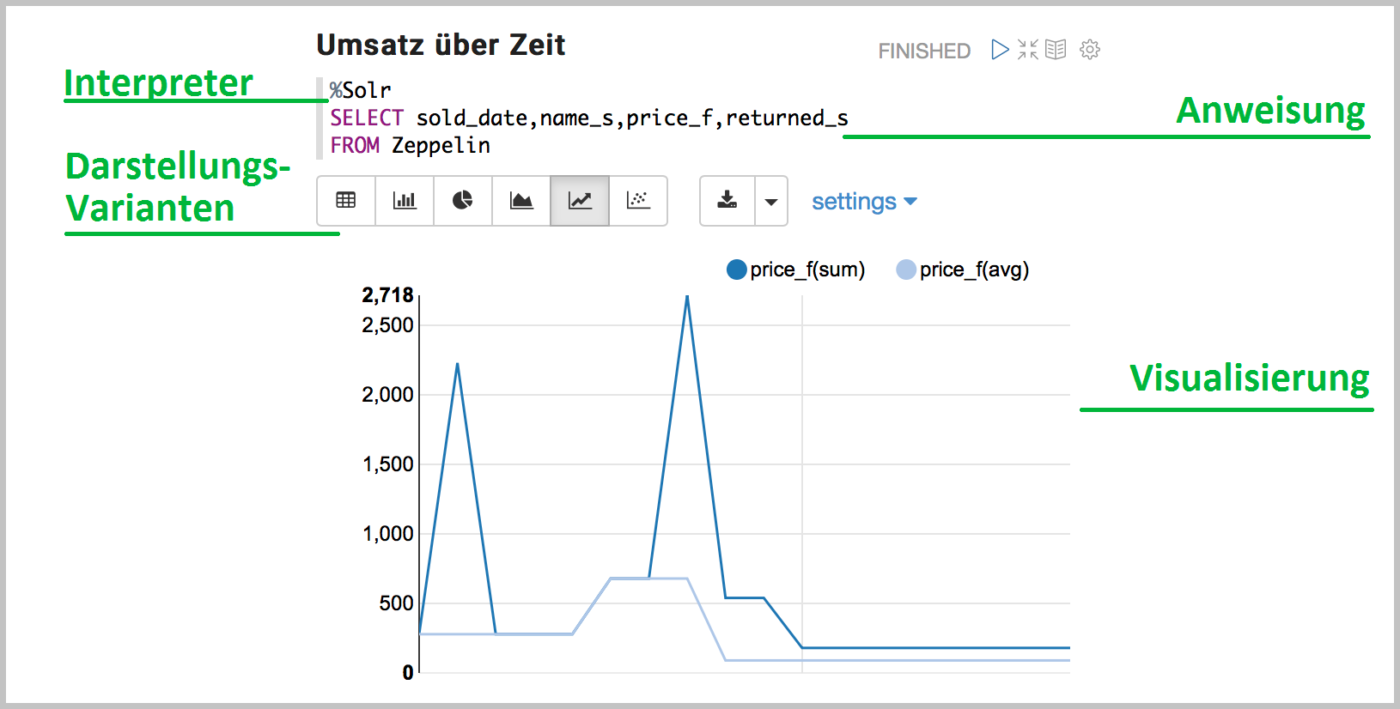
Nicht nur die reinen Daten, sondern auch diverse Aggregationsfunktionen wie Summe, Durchschnitt, Minimum oder Maximum können auf (numerischen) Werten gebildet und in einem oder mehreren (Para)Graphen angezeigt werden. Dadurch lassen sich mit Zeppelin schnell Relationen zwischen Daten aus verschiedenen Quellen abbilden. Die zusätzliche Reporting-Funktion ermöglicht außerdem das Teilen von Paragraphen mit anderen Nutzern über die Bereitstellung von Links. Dadurch können Erkenntnisse nicht nur schnell gewonnen, sondern auch umgehend an zuständige Abteilungen weitergeleitet werden.
Ob in Kuchenform, als Tabelle, als Linien- oder Balkendiagramm oder schlicht als einzelne Aggregationswerte, Zeppelin visualisiert schnell und Use Case bezogen Ihre Datensätze. Die Tatsache, dass die Erstellung der Grafiken in Zeppelin nicht gänzlich ohne programmatisches Wissen auskommt, ist dabei Vor- und Nachteil zugleich. Wo ein Datenbank-Programmierer das Erstellen der SQL-Abfragen für wenig herausfordern halten wird, müsste sich ein nicht-technischer Mitarbeiter erst die komplexen Syntaxregeln aneignen, um diejenigen Daten auszulesen, welche für ihn von Interesse sind. Dafür bietet diese Art der Datenabfrage wiederum sehr viel mehr Möglichkeiten als diejenigen Tools, bei denen jede Grafik durch wenige Klicks auf vorgefertigte Schaltflächen generiert wird. So steht dem Zeppelin-Nutzer die gesamte Bandbreite, aber auch die gesamte Komplexität der angebotenen Programmiersprachen zur Verfügung.
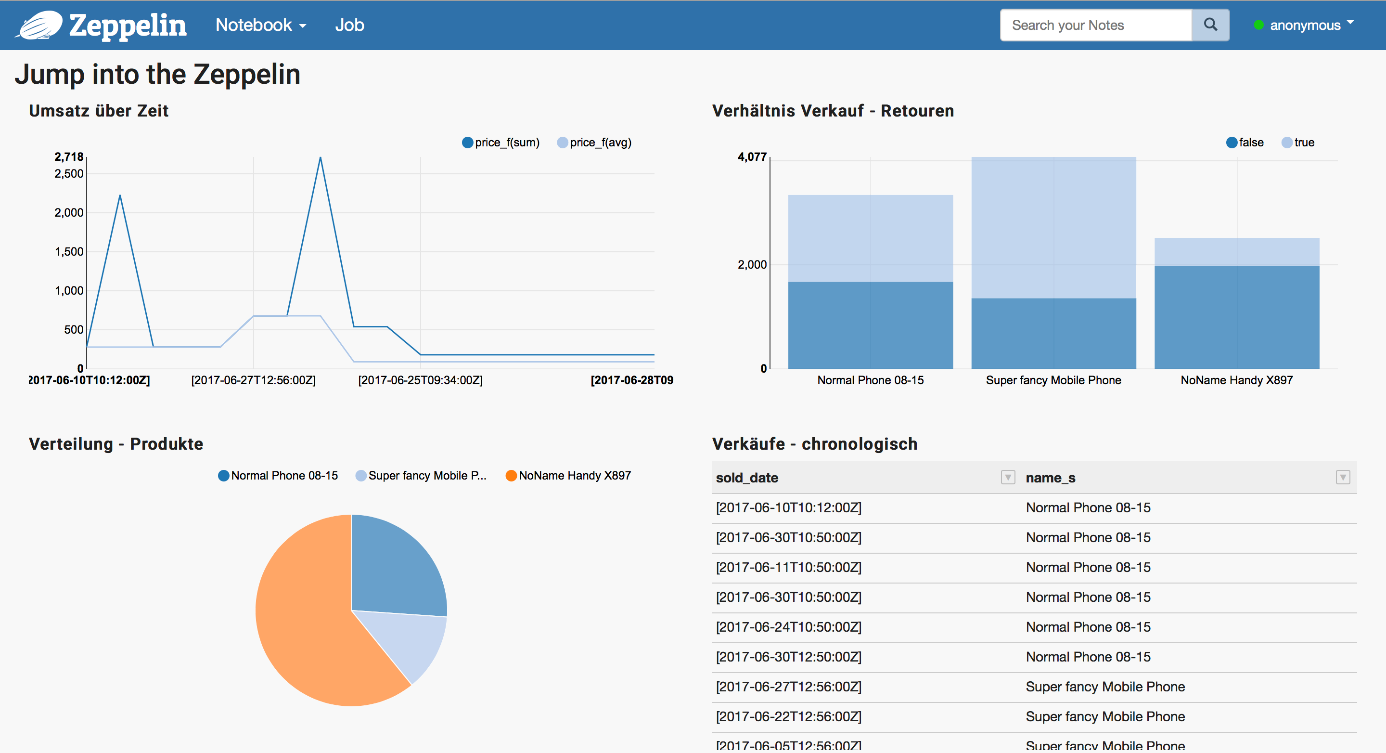
Das folgende Notebook zeigt eine beispielhafte Zusammenstellung von umsatzbezogenen Auswertungen von drei verschiedenen Produkten. Die hier gezeigten Paragraphen veranschaulichen das Visualisierungstool Zeppelin, um Ihnen einen kleinen Einblick in das Werkzeug zu geben.
Wenn Sie beispielsweise erfahren möchten, ob sie für eine bestimmte Region eher in den Winter- oder Sommersport investieren sollten oder wenn Sie einfach neugierig geworden sind, wie Apache Zeppelin eingesetzt werden kann, dann sehen Sie doch mal bei diesem Vortrag vorbei: SQL meets NoSQL.
Ein Wort vor der Landung
Visualisierung ist nicht nur das Aufhübschen von Daten, sondern grundlegendes Werkzeug für die Analyse großer Datentöpfe. Ist Ihnen zum Beispiel aufgefallen, dass die Umsätze der drei Produkte in dem oben abgebildeten Notebook ohne optische Aufteilung nach „wurde zurückgegeben“ (true) und „wurde nicht zurückgegeben“ (false) durchaus irreführend hätten sein können? Nein? Dann sehen Sie sich den Paragraphen nochmal genau an. Denn auch mit dem besten Visualisierungswerkzeug sind all die Linien, Balken und Torten nur etwas wert, wenn Sie auch gesehen werden.
Jump into the Zeppelin – and visualize your Solr!
Weiterführende Links
Visualize your Solr Part 1 – Grab a banana!
Visualize your Solr Part 3 – Browse around!
Visualize your Solr Part 4 – Recycle your Garbage
Visualize your Solr Part 5 – Graph your Stream
Zeppelin im Einsatz für Cross-Analytics


