

Dass Suche mittlerweile mehr ist, als nur das Auffinden von Dokumenten, die ein Suchwort beinhalten, ist längst kein Geheimnis mehr. Ebenso ist hinlänglich bekannt, dass es hierfür Lösungen gibt, die sehr weit ausgereift sind. Dies sind nicht nur Lösungen kommerzieller Natur, sondern auch kostenlose Open Source Varianten, wie Apache Solr, die unübertroffene Skalierbarkeit zeigen.
Daher liegt der Fokus heutzutage in einem anderen Bereich: Der Anreicherung der Inhalte zur besseren Auffindbarkeit. So ist es bereits in der Nachrichtenbranche nicht ungewöhnlich, dass Methoden aus der Semantik dazu eingesetzt werden, Personen, Orte oder Organisationen (sogenannte Named Entities) in unstrukturierten Inhalten zu finden. Diese Entities können zusätzlich noch mit Informationen versehen werden, wie dem Geburtsort der erkannten Person, den Koordinaten des erkannten Ortes oder einem Beschreibungstext einer Organisation. Dies geschieht durch Abfragen von Wissensdatenbanken, wie DBpedia sie ist.
Und auch in diesem Bereich kann auf Open Source Lösungen zugegriffen werden. SHI hat hier kürzlich in einem Proof-of-Concept bereits gute Erfolge im Erkennen von Named Entities mit Hilfe von Apache Stanbol erzielen können. Es handelte sich um relativ kurze und unstrukturierte Texte, die in keiner Weise formatiert waren und hauptsächlich in französischer und niederländischer Sprache vorlagen. Für den Prozess der Named Entity Recognition sowie das Abfragen der zusätzlichen Informationen aus Wissensdatenbanken, waren hier keine großen Anpassungen an die Software nötig, es beschränkte sich auf Konfigurationsanpassungen. Diese Tatsache führte nun dazu, zusammen mit unserem Kunden den nächsten Schritt zu gehen und eine höhere Anzahl an Dokumenten mittels dieser Methode zu evaluieren. Das spätere Ziel dieses Projektes wird ein automatisches Verknüpfen von Inhalten aus unterschiedlichen Sprachen sein, sodass der Redaktionsaufwand erheblich verringert und Publikationsprozesse optimiert und beschleunigt werden können. Grundlage für diese Verknüpfung werden die erkannten Entitäten sein, für die Verknüpfung werden Methoden aus dem Bereich des maschinellen Lernens angewandt werden.
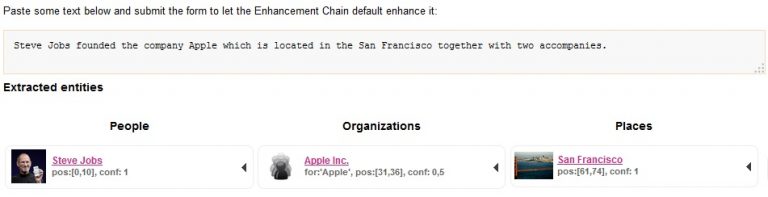
Somit werden bei dieser Anreicherung gezielt Informationen an die bestehenden Inhalte geheftet, die ein besseres Auffinden ermöglichen.


