

Teil 4 der BLOGSERIE:
„Data-Driven Marketing: Wie die kundenzentrierte Ansprache in Zukunft gelingt.“
Erscheinungsintervall: alle 6 Wochen
Lesedauer: 7 Min.
Lesen Sie hier die anderen Beiträge dieser Blogserie:
- Teil 1 „Herausforderung Customer Centricity: Wie etabliert ist Datenanalyse im E-Commerce?“
- Teil 2 „Mit Open Source Tools individuelle Reports erstellen“
- Teil 3 „Langfristige Kundenbindung mit Hilfe von „Advanced Analytics“
- Teil 5 „Gezielte Kundenansprache dank KI“
- Teil 6 „Auf Interessen der Kunden reagieren: Intelligente Recommendations“
- Teil 7 „Data-Driven Marketing: Wie kundenzentrierte Ansprache in Zukunft gelingt in 3 Schritten“
In den vorangehenden Beiträgen zum Thema Data Driven Marketing haben wir Daten zur Kundeninteraktion genutzt, um Reports und gezielte Analysen durchzuführen. Das erlaubt unserem Marketing-Team, sinnvolle Maßnahmen zu definieren – bspw. zur Förderung von Zweitkäufen.
Dabei haben wir bisher nur die Datenhistorie betrachtet und uns auf die Frage konzentriert, was bisher geschah bzw. was der aktuelle Zustand ist. Prädiktive Analysen zielen hingegen darauf, die Historie zu nutzen, um Voraussagen darüber zu machen, was passieren wird. Das verschafft uns zusätzliche Erkenntnisse und Handlungsmöglichkeiten.
Für Prädiktive Analysen werden Methoden des Maschinellen Lernens (ML) oder – in der fortgeschrittenen Variante – der Künstlichen Intelligenz eingesetzt. In diesem Beitrag wollen wir den Einstieg in die Prädiktive Analyse machen, um mit Hilfe von einem einfachen, alt bekannten ML-Algorithmus die Frage zu beleuchten: Wann bleiben die Kunden vor der Tür stehen?
Bounces in unserem Online-Shop voraussagen
Übersetzt für unseren E-Commerce-Shop bleibt ein Kunde vor der Tür stehen, wenn er zwar zu unserem Online-Shop kommt, jedoch ohne „einzutreten“ die Seite sofort wieder verlässt – im Web-Kontext spricht man hierbei von einem „Bounce“.
Unsere Google Analytics Daten, die die Besuche der Nutzer im Shop beschreiben, wollen wir nutzen, um Bounces vorauszusagen. Hierfür setzen wir unsere einfache Open Source Infrastruktur ein und wählen eines der vielen ML-Algorithmen, die in Apache Spark zur Verfügung stehen: Decision Trees („Entscheidungsbäume“).
Entscheidungsbäume
Entscheidungsbäume sind eine Methode zur automatischen Klassifikation von Datenobjekten.
Um eine Klassifikation eines einzelnen Datenobjektes abzulesen, geht man vom Wurzelknoten entlang des Baumes abwärts. Bei jedem Knoten wird eine Bedingung auf einem Merkmal abgefragt und eine Entscheidung über die Auswahl des folgenden Knoten getroffen. Diese Prozedur wird so lange fortgesetzt, bis man ein Blatt erreicht. Das Blatt entspricht der Klassifikation.
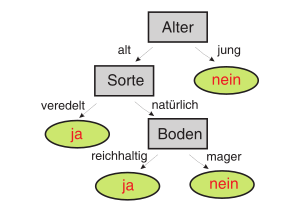
Decision Trees als ML-Algorithmus versuchen, für eine bestimmte Aufgabe den Entscheidungsbaum zu generieren, der die Datenobjekte möglichst genau klassifiziert. Da sie hierfür bereits klassifizierte Beispieldatensätze verwenden, um zu „lernen“, gehören sie zu der Klasse der überwachten ML-Algorithmen.
Ein großer Vorteil von Entscheidungsbäumen ist, dass sich das daraus resultierende Modell leicht interpretieren lässt – man kann als Mensch nachvollziehen, wie die Entscheidung für einen bestimmten Datensatz getroffen wird. Ein Beispiel ist in Abbildung 1 zu sehen.
Maschinelles Lernen anwenden
Die wesentlichen Schritte bei der Anwendung von überwachten ML-Verfahren sind in Abbildung 2 dargestellt.
Beim Training wird ein Teil der vorhandenen Daten genutzt, um mit Hilfe eines bestimmten Algorithmus ein Modell zu erzeugen – in unserem Fall einen Entscheidungsbaum. Bevor das eigentliche Training durchgeführt werden kann, müssen zunächst aus den Daten die Merkmale extrahiert werden, die die zu klassifizierenden Objekte beschreiben und beim Lernen genutzt werden. Die durch Lern-Merkmale repräsentierten Objekte werden anschließend in das Input-Format transformiert, das der spezifische ML-Algorithmus erwartet. Dann kann beim Modell-Training gelernt und ein Modell erstellt werden. Die Qualität des Modells wird am Ende mit einem anderen Teil der verfügbaren, vorklassifizierten Daten evaluiert.
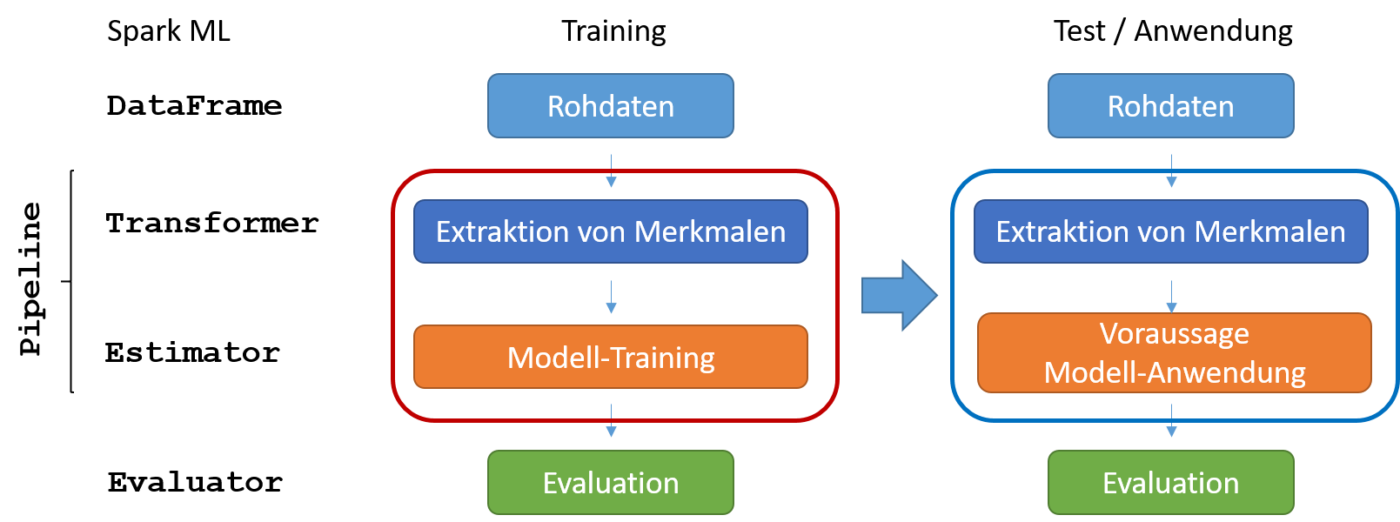
Bei einem Test bzw. bei der produktiven Anwendung des Modells sehen die Verarbeitungsschritte im Prinzip genauso aus. Der Unterschied ist nur, dass statt des Trainings das bereits berechnete Modell angewendet wird, um neue Datensätze zu klassifizieren.
Die Schritte mit ML Spark umsetzen
Um aus den Google Analytics Daten einen Entscheidungsbaum automatisch zu gewinnen, müssen wir die beschriebenen Schritte für das Training umsetzen.
Dies erfolgt in unserer Open Source Analytics Infrastruktur, indem wir den Spark ML Package verwenden, die neuere Apache Spark Bibliothek für Maschinelles Lernen. Diese baut nicht mehr nur auf RRDs auf, sondern kann mit DataFrames umgehen. Für die Durchführung der verschiedenen Anwendungsschritte stehen in Spark einzelne Klassen zur Verfügung, wie in Abbildung 2 dargestellt.
Wie üblich schreiben wir unser Programm in einem Jupyter Notebook, das hier heruntergeladen werden kann.
1. Einlesen der Daten und Auswahl der Features
Die Google Analytics-Daten lesen wir wie üblich von der Festplatte als DataFrame ein, wir holen uns für unser Experiment zunächst nur Visits für einen Monat (s. Notebook).
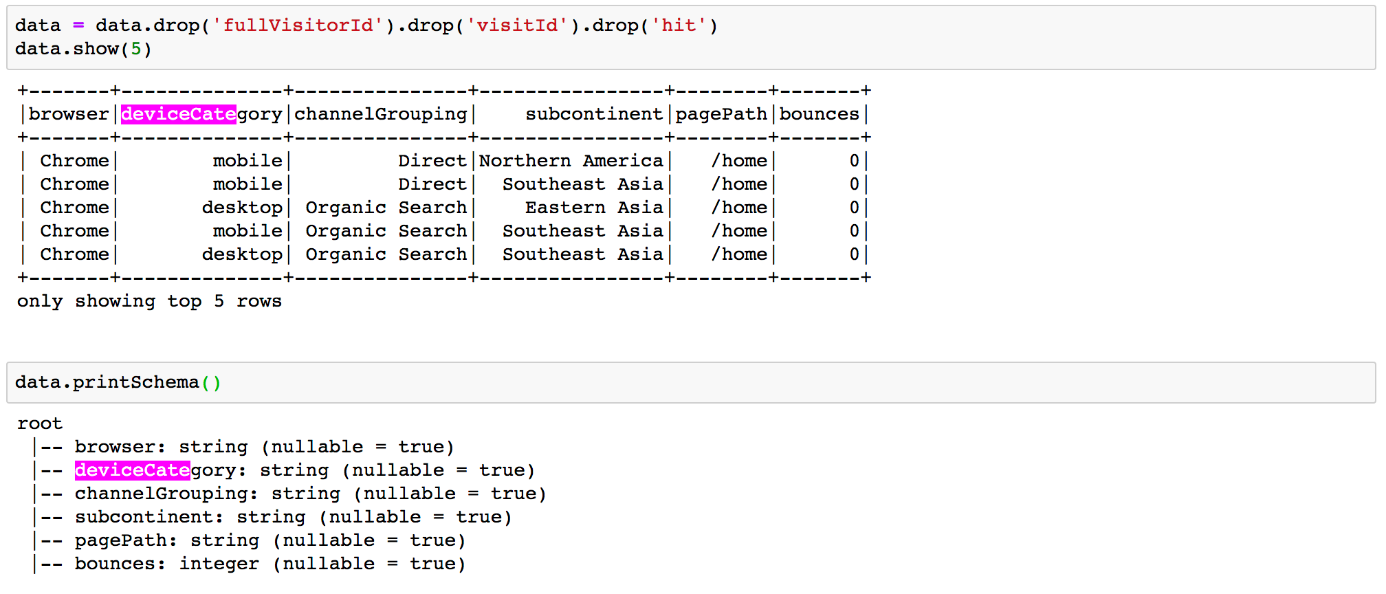
Die Information, ob es sich bei dem Visit um einen Bounce handelt, ist in der Spalte ‚totals‘ kodiert. Wir behalten die entsprechende Unterspalte ‚bounces‘ und zusätzlich die Spalten, die uns als Merkmal („Feature“) dienen werden:
- Zur Herkunft des Besuchs: Kanal (channelGrouping‘) und geographische Region (‚geoNetwork.subcontinent‘)
- Merkmale des Besuchers: Eingesetzter Browser und Gerät (‚device.browser‘, ‚device.deviceCategory‘)
- Landingpage des Besuchs: Diese muss aus dem ersten Hit (‚hit.page.pagePath‘) des Besuchs extrahiert werden, weswegen die Hits mit Hilfe von explode auseinander gefaltet werden und wir nur das erste behalten (‚hit.time‘ ==0)
Damit decken wir unterschiedliche Aspekte eines Besuchs ab. Eine erste Datenexploration war der Auswahl der Features schon vorausgegangen. Wir wissen daher, dass die Features unabhängig voneinander sind, was wichtig beim Trainieren des Modells ist. Nach einem entsprechenden „select“ sehen die Rohdaten in unserem Input-DataFrame „data“ etwa so aus:
Im ausgewählten Datenset sind Bounces (‚bounces‘ = 1) sowie „echte“ Besuche (‚bounces‘ = 0) vergleichbar oft repräsentiert:

Das stimmt damit überein, was in der ersten Datenexploration beobachtet wurde. Eine weitere Aufbereitung der Daten ist daher nicht notwendig, um für das Training ein ausgewogenes Datenset bzgl. der Ausprägungen der Zielklasse zu bekommen.
2. Feature Engineering
Die ausgewählten Merkmale stellen im Prinzip Kategorien dar. Die Anzahl der verschiedenen Ausprägungen in so einem kategorischen Merkmal sollte im Vergleich zur Anzahl der Datensätze klein sein, Ausprägungen sollten nicht dünnbesetzt sein. Wir schauen uns daher die einzelnen Merkmale genauer an.
Die Implementierung vom Entscheidungsbaum-Algorithmus im ML Package steuert mit dem Parameter „maxBins“, wie groß ein kategorisches Feature maximal sein darf. Der Default-Wert ist 32, der bei der Betrachtung unserer Kategorien als Ziel dient.
Browser
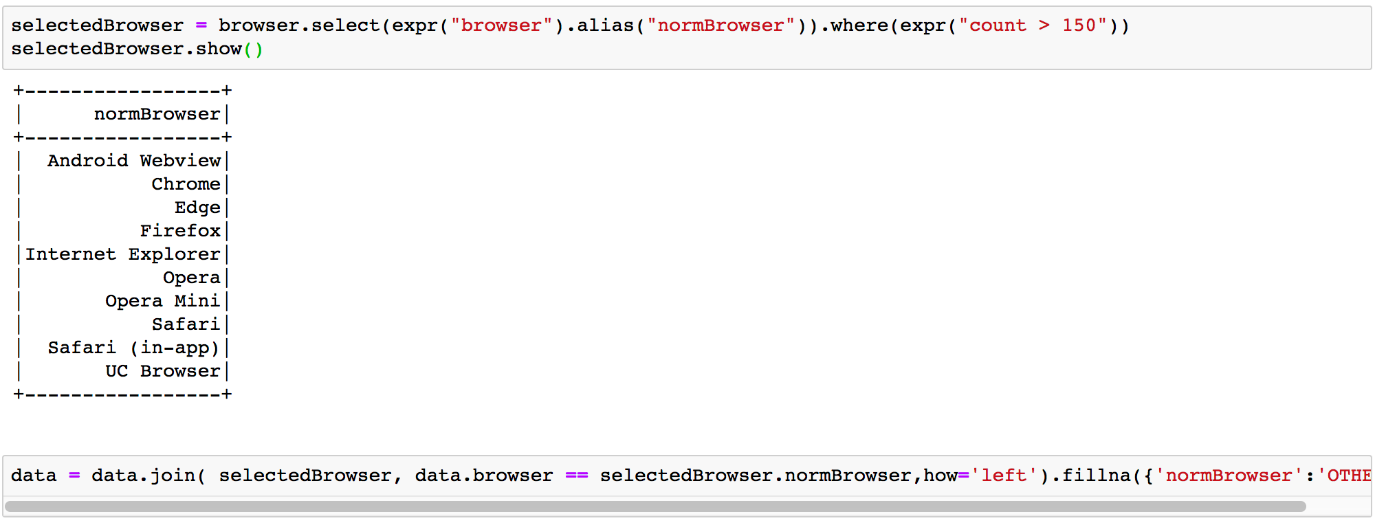
Bei ‚browser‘ haben wir 29 verschiedene Ausprägungen, die zum Teil sehr dünn besiedelt sind.
Wir behalten daher die Browser, die eine gewisse Häufigkeit überschreiten, und fügen sie mittels „join“ in den Daten ein. Alle anderen seltenen Browser werden als OTHER kodiert.
Device Category, Kanal
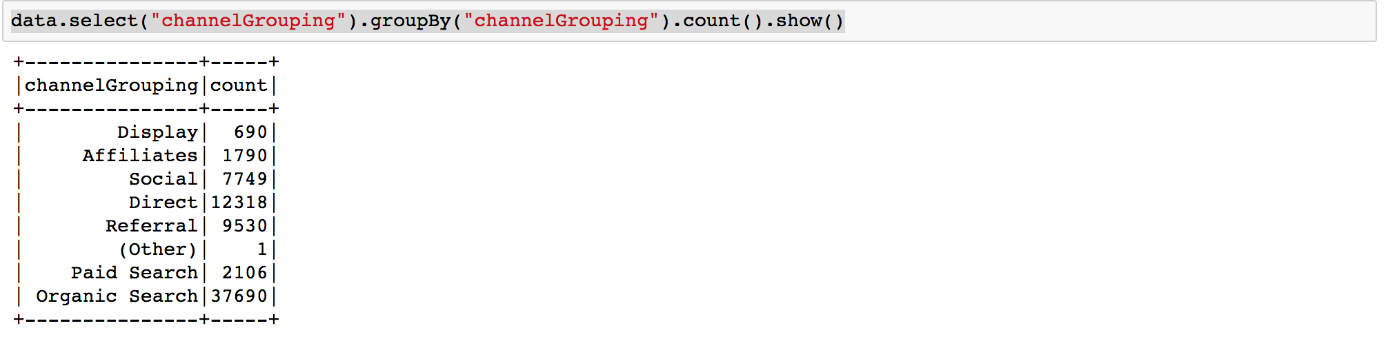
Das Feature ‚deviceCategory‘ eignet sich bereits gut als Kategorie, ‚channelGrouping‘ ebenso:
Geographische Information
Indem wir die geographische Herkunft mittels ’subcontinent‘ kodieren, erhalten wir ein Kategorienfeature einer verwendbaren Größe:

Landingpage
Die Pfade, die die Landingpage abbilden, sind dagegen sehr variabel:
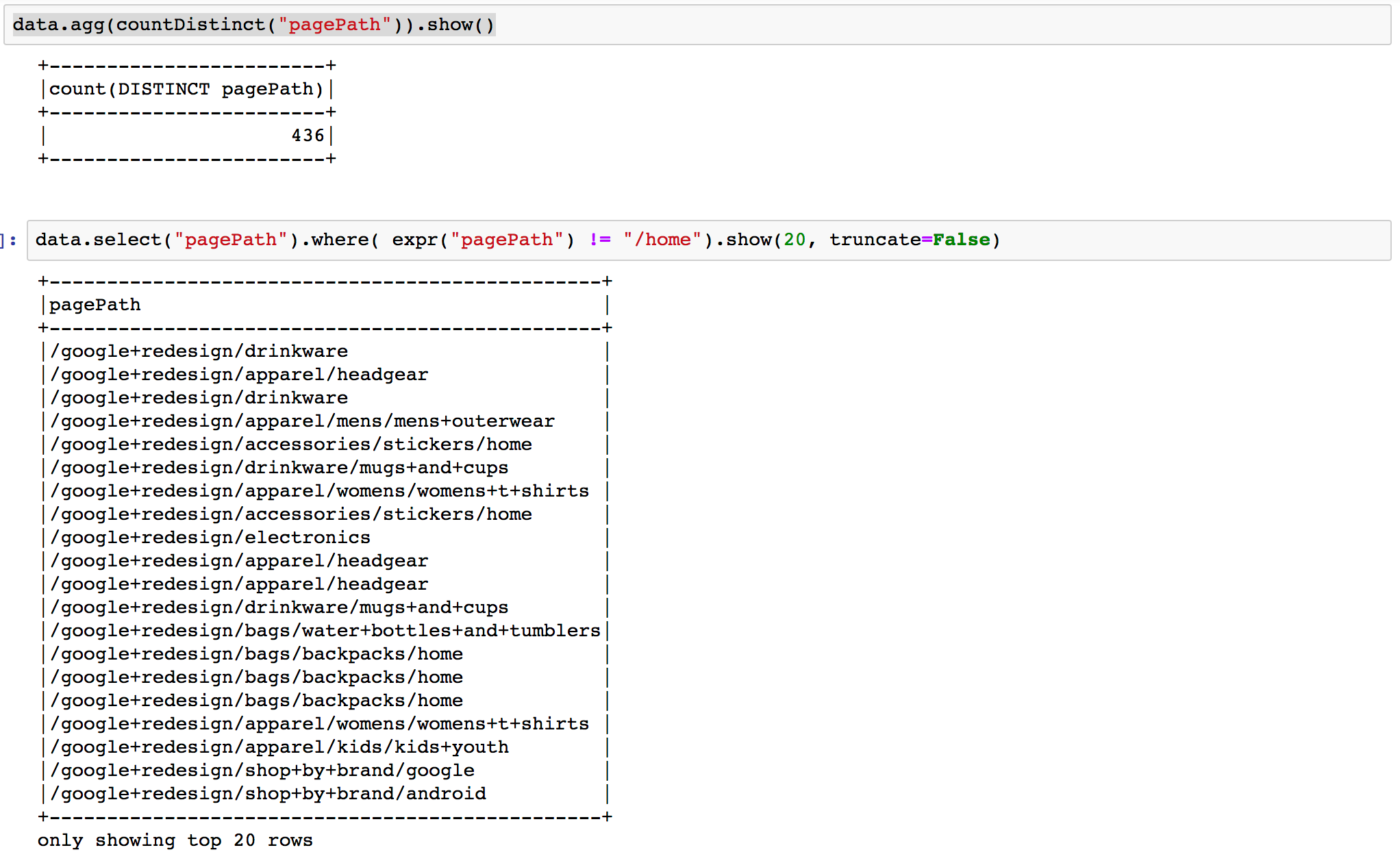
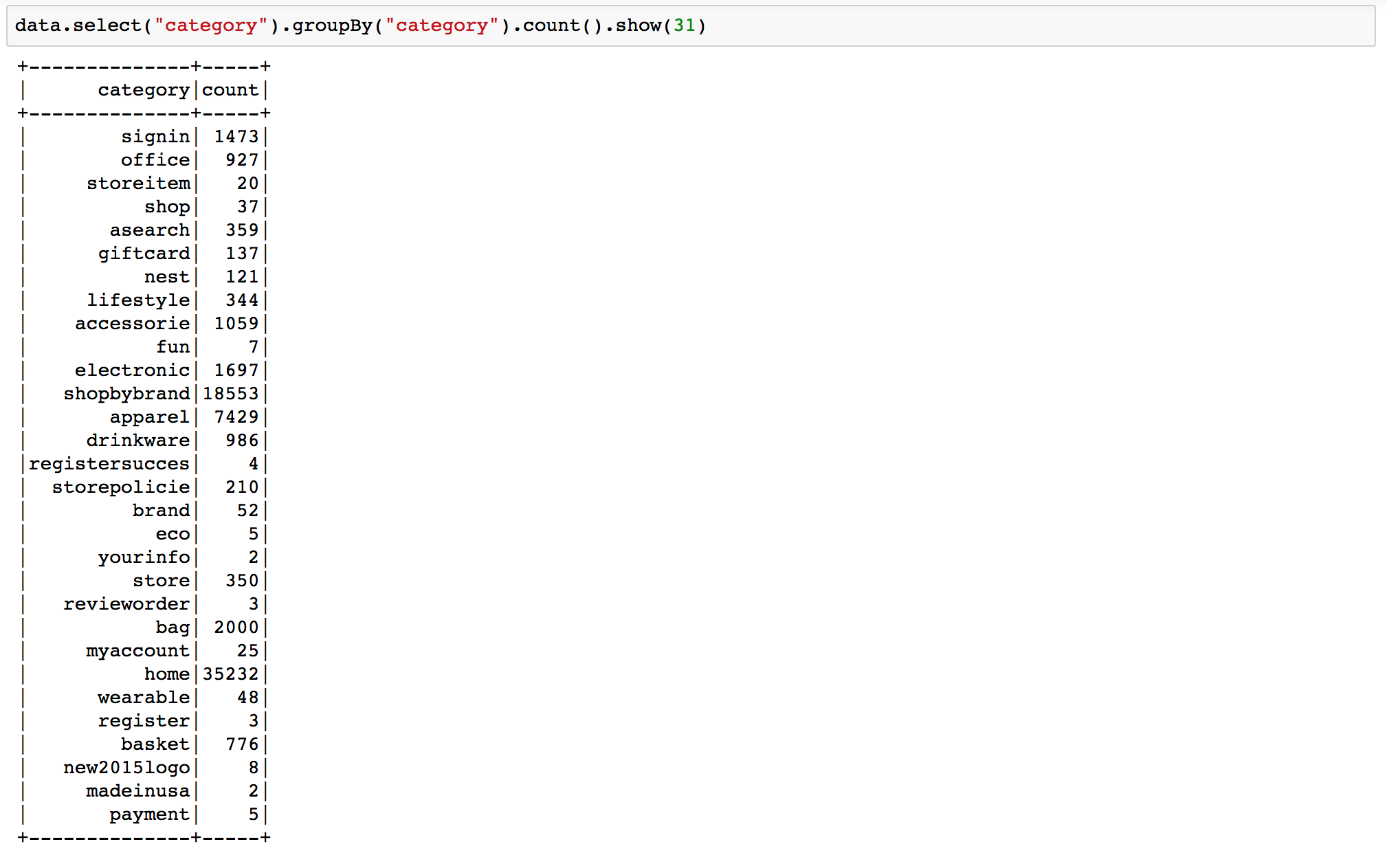
Um diese Vielfalt zu verringern, extrahieren wird die Produktkategorie, die nach dem zweiten Schrägstrich im Pfad vorkommt und beschreiben die Landingpage dadurch. Hierfür wenden wir die Funktionen ’substring_index‘ und ‚regexp_replace‘ auf die Spalte ‚pagePath‘ hintereinander an, das Ergebnis ist die zusätzliche Spalte ‚category‘. Weitere reguläre Ausdrücke normalisieren Sonderzeichen und Endungen (s. Notebook):
3. Aufbau einer Trainings-Pipeline mit der Spark ML Bibliothek
Um aus den vorbereiteten Merkmalen im DataFrame „data“ einen Entscheidungsbaum lernen zu können, müssen sie noch in das Input-Format des ausgewählten ML-Algorithmus gebracht werden, des DecisionTreeClassifier in unserem Fall. Dieser erwartet ein DataFrame mit zwei Spalten als Input: eine mit einem Vektor von numerisch kodierten Merkmale sowie eine weitere, in der die richtige Klassifikation steht.
Mit einer entsprechenden ML Pipeline gelingt die Transformation vom Eingang-DataFrame in das richtige Format leicht (Abbildung 3).
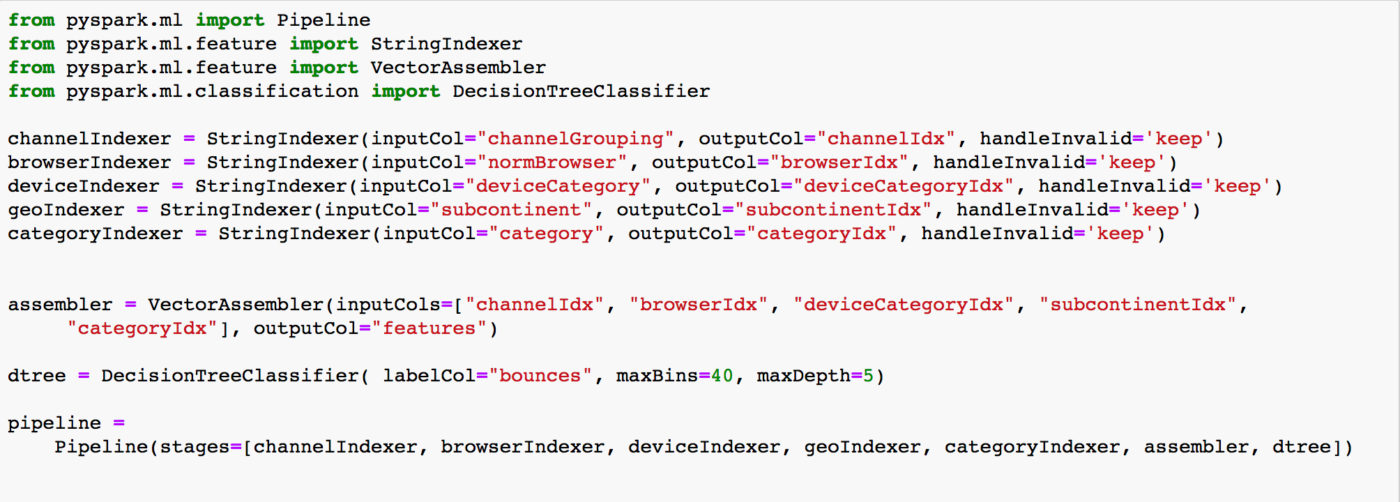
Für die numerische Kodierung der kategorialen Merkmale verwenden wir StringIndexer, die jede Ausprägung einer Kategorie durch eine Zahl ersetzen, wobei die häufigste Ausprägung als 0.0 kodiert wird, die zweithäufigste als 1.0, usw., wie am Beispiel ‚deviceCategory‘ zu sehen:

Als Nächstes müssen die numerisch kodierten Merkmale in einem Vektor zusammengefasst werden, was ein VectorAssembler leistet. In der Pipeline definieren wir dann die Reihenfolge aller notwendigen Transformationsschritte: Zuerst die verschiedenen StringIndexer, danach den VectorAssembler und am Ende den DecisionTreeClassifier.
Bevor wir das Modell trainieren, teilen wir unseren Datensatz in ein Trainingsset (80% der Gesamtmenge) und ein Validierungsset (20%) auf:

Das eigentliche Training erfolgt dann, indem man das Trainingsset an die Pipeline „fittet“:
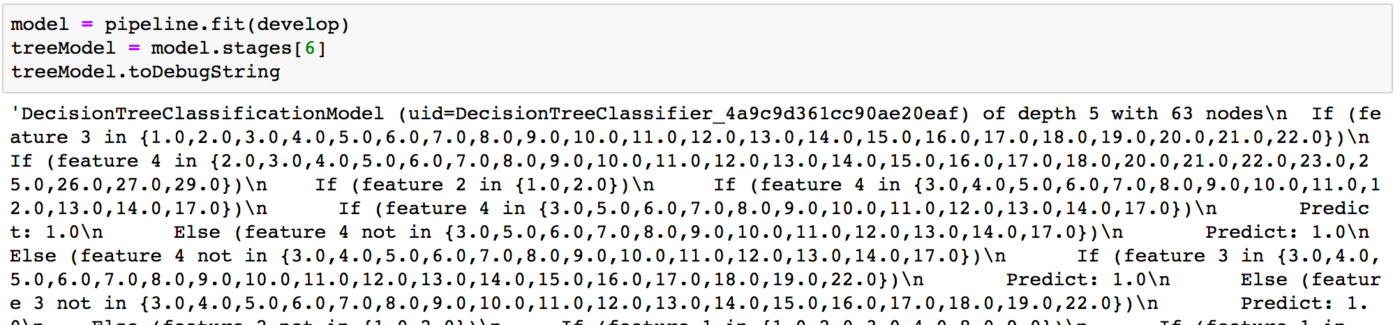
Nach dem Training holen wir uns das Entscheidungsbaum-Modell aus dem entsprechenden Schritt der Pipeline heraus und lassen uns entsprechende Debug-Informationen ausgeben. Es wurde ein Baum der Tiefe 5 mit 63 Knoten erzeugt! Einen Ausschnitt aller Verzweigungen sieht man als If-Then-Else Statemens im Bild. Ein recht großer Entscheidungsbaum angesichts dessen, dass wir nur fünf Merkmale haben. Aber wie gut ist unser Modell?
4. Evaluation des Modells
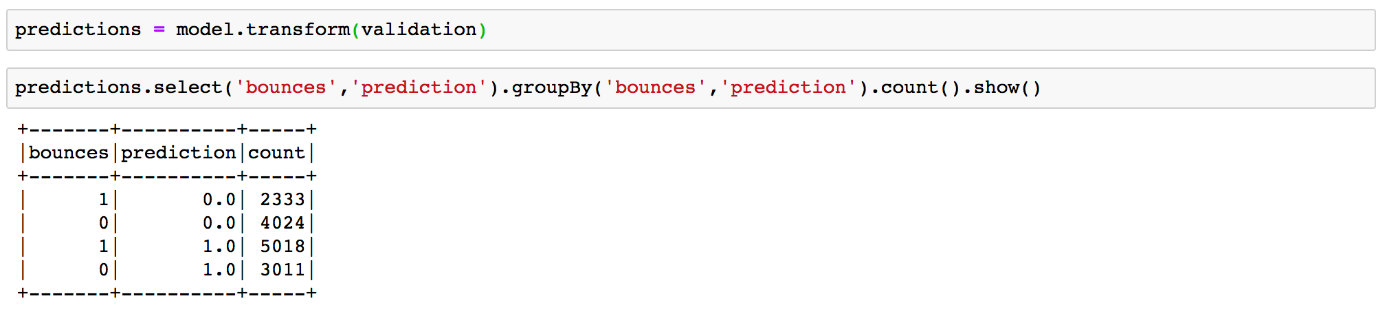
Wie gut unser Modell funktioniert, testen wir anhand des reservierten, für das Training nicht verwendeten Validierungsset. Dafür wenden wir die Modell-Pipeline darauf an und vergleichen die vorausgesagte Klasse ‚predictions‘ mit der annotierten Klassifikation ‚bounces‘:
Das Modell macht also an einigen Stellen Fehler, bspw. sagt es bei 2333 Bounces fälschlicherweise voraus, dass der Besuch nicht sofort abgebrochen wird. Um die Güte eines Modells zu bewerten, gibt es verschiedene standardisierte Maße, die auf der Anzahl und Art der begangenen Fehler basieren. Eine davon ist die Accuracy ( zu Deutsch: „Genauigkeit“), die den Anteil von richtigen Voraussagen unter allen Voraussagen wiedergibt. Die Genauigkeit lässt sich mit Hilfe von einem speziellen Evaluator aus der Spark ML Bibliothek leicht berechnen:


5. Praxistaugliche Modelle
In unserem ersten Experiment wird in etwas mehr als der Hälfte der Fälle eine richtige Voraussage von unserem Modell gemacht. Lässt sich das verbessern?
Wir könnten es einfach mit mehr Trainingsdaten versuchen. Diese sind aber in der Regel begrenzt, in der Praxis fokussiert man sich daher darauf, die Parameter des Modells optimal einzustellen. Hierfür fährt man Reihen von Experimenten (Training/Test Zyklen) mit unterschiedlichen Parameterbelegungen. Bei einem Decision Tree würde das z.B. bedeuten, dass man unterschiedliche Tiefen des Baums zulässt.
Um zu vermeiden, dass das Modell für einen bestimmten Datensatz optimiert wird und nicht mit ungesehenen Datenpunkten umgehen kann („überangepasstes Modell“), wird bei den Experimentreihen eine weitere Technik verwendet: Mit Cross-Validierung wird ein Experiment mit einer bestimmten Parameterbelegung eine bestimmte Anzahl von Malen („N“) wiederholt, wobei bei jeder Wiederholung ein Teil der Daten vom Training ausgenommen wird und für einen Test verwendet wird. Dadurch bekommt man eine Messreihe für die Qualitätsmaße und unterschiedliche Versionen eines Modells, aus denen das beste Modell ausgewählt wird.
Im Notebook haben wir im Abschnitt „Parameteroptimierung und Cross-Validierung“ Reihen für unterschiedliche Werte des Parameters „maxDepth“ durchgeführt und Cross-Validierung durchgeführt. Es stellt sich raus, dass die Genauigkeit bei einem Baum der Tiefe 3 am höchsten ist. Der beste Entscheidungsbaum lässt sich so darstellen:
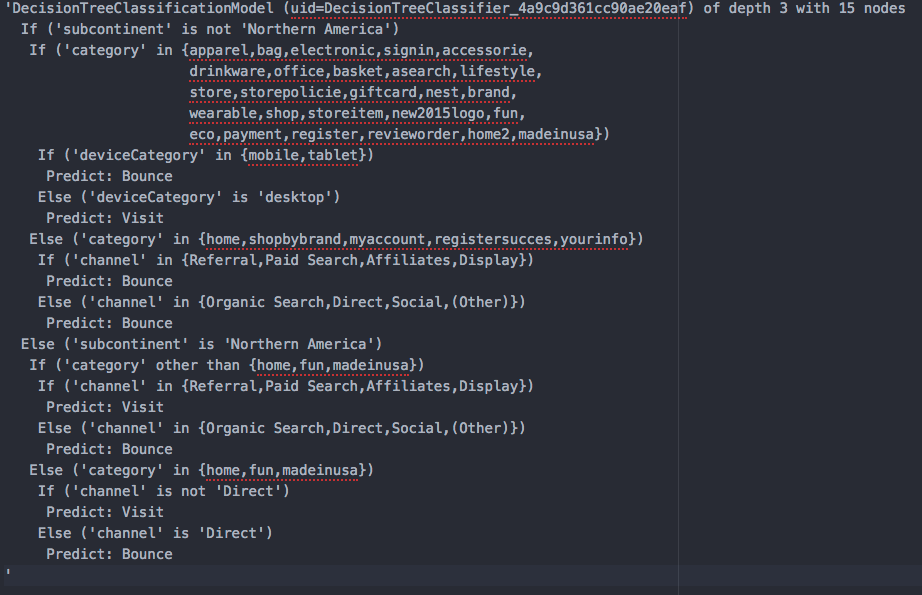
Die gewonnenen Erkenntnisse in der Praxis einsetzen
Der gewonnene Baum lässt sich leicht interpretieren. Der geographische Ursprung in Nordamerika teilt die Besuche in zwei großen Gruppen auf:
- Kommt der Besuch aus Nordamerika und landet der Besucher auf einer Produktseite, bleibt er tendenziell im Shop, wenn er an einem Desktop PC sitzt. Kommt er über ein mobiles Gerät, verlässt er tendenziell sofort die Seite (Bounce).
- Kommt der Besuch aus dem Rest der Welt, führen bezahlte Kanäle wie Paid Search, Anzeigen, usw. oder direkte Verweise für die meisten Landingpages außer „home“, „madeinusa“ oder „fun“ zu einem längeren Besuch. Direkte Suchen oder Verweise in Sozialen Medien führen hingegen tendenziell zu einem Bounce.
Was bedeutet das für unseren Shop? Muss das mobile Layout für das Nordamerikanische Publikum verbessert werden? Ist der Shop für den Rest der Welt nicht auffindbar oder schlecht lokalisiert? Da scheinen nur bezahlte Anzeigen die Kunden zu bewegen, in den Shop einzutreten.
Was letzten Endes die richtigen Maßnahmen zur Vermeidung von Bounces sind, muss das Marketing-Team mit seinem Fachwissen selbst prüfen. Das fällt nun aber dank der gewonnenen Erkenntnisse sehr viel leichter.
Ausblick
Wir haben maschinelles Lernen eingesetzt, um vorauszusagen, wann ein Kunde vor der Tür stehen bleibt. Der Nutzen davon ist nicht, dass wir in dem Fall unser Modell einsetzen, um vor der Tür ein Schild mit der Aufschrift „Komm bitte rein“ aufzuhängen, sondern dass wir verstehen, wann es dazu kommt. Das geht, weil wir das ausgewählte ML-Modell interpretieren können, was uns ermöglicht, entsprechende Maßnahmen zu definieren.
Nach dem Einstieg in das Maschinelle Lernen wollen wir uns in den nächsten Blog-Beiträgen damit beschäftigen, wie sich Kundengruppen entdecken lassen. Das ist eine Voraussetzung für eine differenzierte Ansprache, die zu mehr Umsatz führt.


