

Lucidworks Fusion: Konnektoren, Parser und Index-Pipelines erklärt!
Lucidworks Fusion ist eine mächtige Plattform im Bereich Data Discovery und unter anderem ideal geeignet für die Suchfunktion in einem Onlineshop oder zur Informationsfindung am Arbeitsplatz. Eine der Stärken von Fusion ist dabei seine Fähigkeit, Daten aus ganz unterschiedlichen Quellen zu erfassen und damit Datensilos aufzulösen. Bei den Daten kann es sich um strukturierte oder unstrukturierte Daten der verschiedensten Formen handeln. Doch wie funktioniert das genau? Im folgenden Blogbeitrag möchte ich Ihnen genau das erklären und hands-on demonstrieren.
Der grobe Ablauf in Lucidworks Fusion
Um zu Beginn direkt einen Überblick über den Indexierungsprozess zu geben, habe ich die folgende Abbildung mitgebracht.
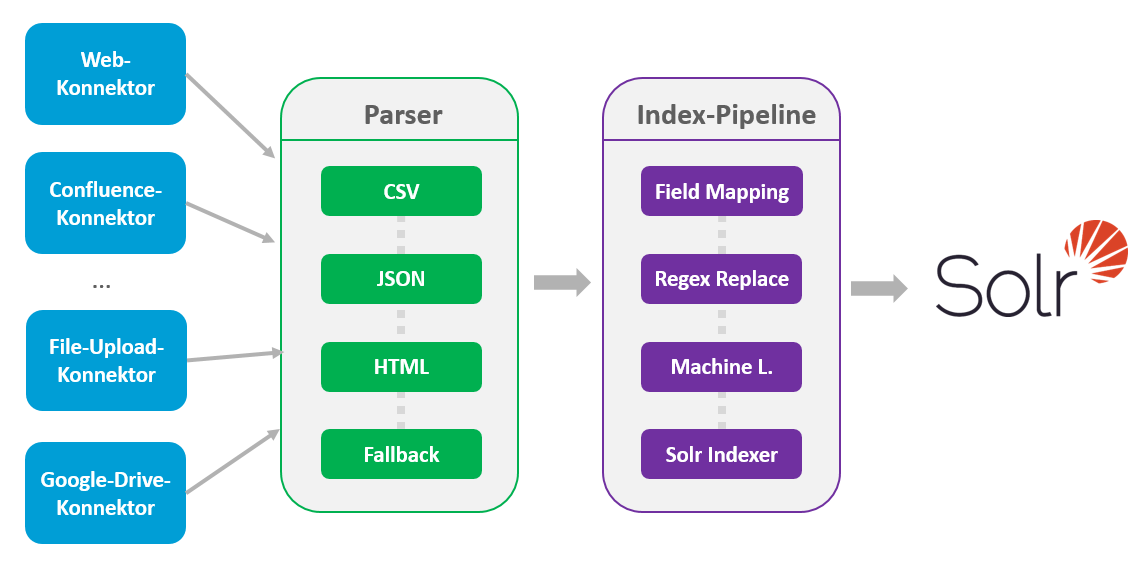
Daten kommen über verschiedene Konnektoren ins System und werden zunächst durch einen Parser entsprechend dem Datentyp verarbeitet und zerlegt. Anschließend fließen die Daten weiter an die Index-Pipeline, wo sie verschiedene Transformationsstufen durchlaufen, bis sie schließlich in Solr indexiert werden. Solr ist die „Suchmaschine“ im Herzen von Fusion. Dort stehen die Daten dann zur Durchsuchung bereit. Nach diesem groben Überblick möchte ich nun die einzelnen Komponenten des Prozesses näher beleuchten.
Die Konnektoren
Am Anfang der Datenerfassung stehen Fusions Konnektoren. Konnektoren holen die eingehenden Daten aus der Quelle. Sie wandeln sie in einen Bytestream um und senden diesen Bytestream zur weiteren Verarbeitung an einen sogenannten Parser. Es existieren diverse Konnektoren, die jeweils auf einen bestimmten Datentyp spezialisiert sind. So kann man an Fusion eine Vielzahl von Datenquellen anbinden, unter anderem:
- Microsoft OneDrive
- Microsoft Exchange Server
- Avaya Spaces
- Miro
- Google Meet
- Slack
- Microsoft Excel
- Azure Data Lake
- Salesforce
- Atlassian
- Und hunderte weitere …
Kurz gesagt sind Konnektoren Fusions eingebaute Mechanismen, um Daten aus den Quellsystemen abzuholen. Sie sind weder an der Weiterverarbeitung noch an der Transformation oder Speicherung der Daten beteiligt. Diese Aufgaben übernehmen in Fusion Parser und Index-Pipelines.
Der Parser
Nachdem der Konnektor im ersten Schritt die Daten abgeholt und daraus einen Bytestream erzeugt hat, sendet er diesen an den konfigurierten Parser. Die Hauptaufgabe des Parsers ist es, diesen Bytestream in einzelne Dokumente zu zerlegen und diese in eine Form zu transformieren, die von der anschließenden Index-Pipeline verarbeitet werden kann. Ein Parser kann potenziell ganz verschiedene Dateiformate verarbeiten. Für jede dieser Dateiformate ist eine eigene Stufe zuständig. Möchten wir beispielsweise Webseiten und CSV- und JSON-Dokumente verarbeiten, könnten wir einen Parser bestehend aus einer „CSV“-Stufe, einer „JSON“-Stufe und einer „HTML“-Stufe nutzen.
Empfängt der Parser Daten, dann prüft nacheinander jede seiner Stufen, ob der eingehende Datenstrom mit den Medientypen bzw. den Dateinamenerweiterungen der Stufe übereinstimmt. Die erste Stufe, die eine Übereinstimmung findet, verarbeitet die Daten und produziert daraus ein Dokument, welches die folgende Index-Pipeline verarbeiten kann. Alle weiteren Stufen, die potenziell ebenfalls auf den Datentyp passen würden, werden ignoriert.
Die Index-Pipeline
Nachdem die Daten von einem Konnektor abgeholt und anschließend vom Parser zerlegt wurden, durchlaufen sie im letzten Schritt eine sogenannte Index-Pipeline. Wie ein Parser besteht auch eine Index-Pipeline aus einer Reihe von Stufen. Anders als beim Parser werden aber für jedes Dokument nacheinander alle Stufen der Index-Pipeline ausgeführt. Jede Stufe der Index-Pipeline führt jeweils eine andere Transformation der Daten durch.
Beispielsweise kann man mit der „Detect Language Index Stage“ die Sprache eines Textes bestimmen, mit der „Regex Field Replacement Index Stage“ den Inhalt eines Feldes basierend auf einer Regex erweitern oder überschreiben oder mit der „Machine Learning Index Stage“ ein Machine Learning Modell auf die Daten anwenden. Sind alle Transformationen abgeschlossen, indexiert schließlich die finale Stufe die Daten in Solr. Damit ist die Erfassung der Daten abgeschlossen und diese stehen in Fusion bereit, um durchsucht zu werden.
Hands-on Demo
Damit das Thema noch etwas besser verständlich wird, möchte ich das Indexieren von Daten nun auch hands-on demonstrieren. Zu Demozwecken und damit es gut nachvollzogen werden kann, habe ich als Datenquelle ein CSV-Dokument gewählt, nämlich das folgende:
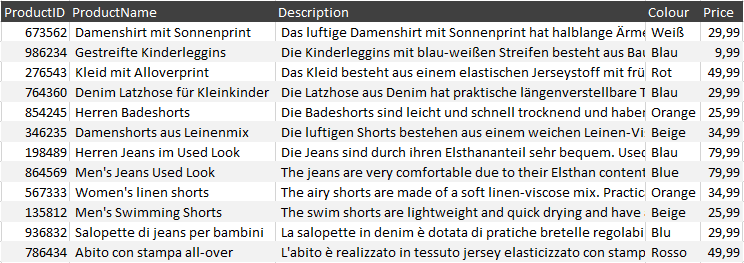
Übrigens: Sollten Sie die folgende Anleitung gerne selbst ausprobieren wollen, aber Fusion (noch) nicht in Betrieb haben, können Sie den Fusion Playground nutzen. Dies ist ein kostenloses Angebot Lucidworks, mit dem man für eine Stunde lang eine Fusion-Instanz nutzen kann.
Alle folgenden Schritte der Anleitung werden über die Fusion UI vollzogen. Zunächst müssen wir eine App in Fusion erstellen:
- Unter „Add new app“ wähle „Create new App“.
- Wir geben hier einen Namen ein (ich wähle „Demo“) und bestätigen.
- Eine Kachel für die neue App erscheint. Mit einem Doppelklick darauf gelangen wir in die App.
Im zweiten Schritt erstellen wir einen Parser:
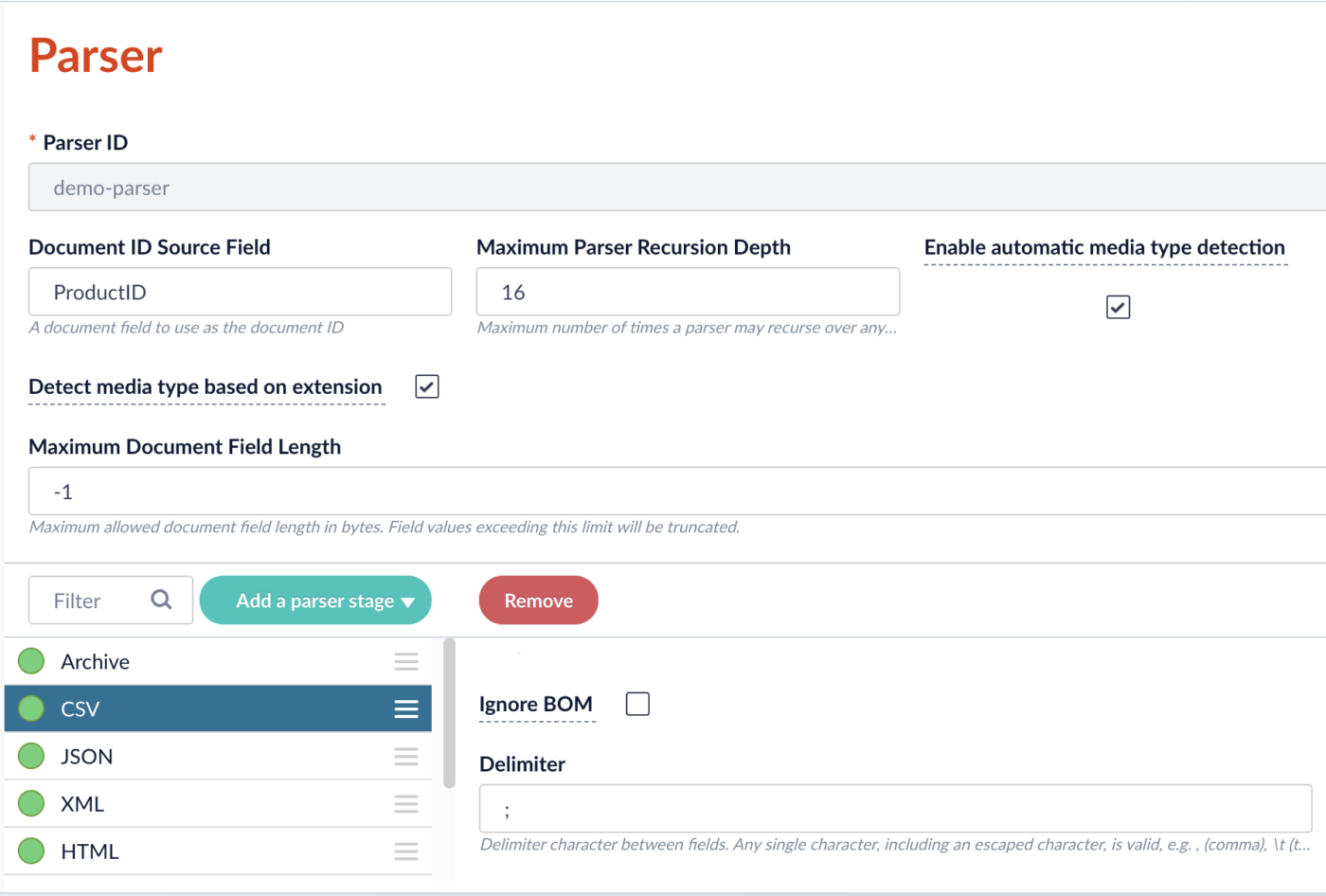
- Im Hauptmenü an der linken Leiste wählen wir „Indexing“ > „Parsers“ und klicken dann auf den Button „Add +“. Es öffnet sich ein Fenster, in dem der neue Parser konfiguriert werden kann.
- Wir vergeben hier zunächst eine Parser-ID, z. B. „demo-parser“.
- Unter „Document ID Source Field“ tragen wir die Spalte ein, die die ID (in Solr Fachsprache der „unique Key“) der Dokumente sein soll. In unserem Fall ist das „ProductID“. Tragen wir hier nichts ein, würde Fusion eine eigene ID generieren.
- Standardmäßig sind schon einige Stufen im Parser enthalten. Wir belassen diese einfach, wie sie sind. Nur die CSV-Stufe schauen wir uns näher an.
- In der CSV-Stufe setzen wir den „Delimiter“ auf „;“. Strichpunkte sind nämlich die Trennzeichen in unserer CSV-Datei.
- Wir bestätigen mit „Save“ und erstellen so den Parser.
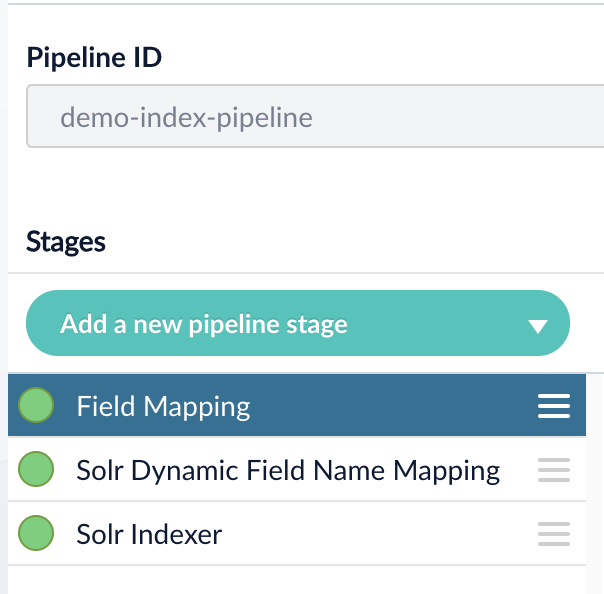
Als Nächstes erstellen wir die Index-Pipeline:
- Im Hauptmenü wählen wir „Indexing“ > „Index Pipelines“ und klicken dann auf den Button „Add +“. Es öffnet sich ein Fenster, in dem die neue Index-Pipeline konfiguriert werden kann.
- Wir vergeben eine Pipeline-ID, z. B. „demo-index-pipeline“.
- Per Default hat die neu erstellte Index-Pipeline folgende Stages: „Field Mapping“, „Solr Dynamic Field Name Mapping“ und „Solr Indexer“.
- Wir lassen die Konfiguration fürs Erste unverändert und bestätigen mit „Save“.
Die letzte Komponente, die uns fehlt, ist eine sogenannte Datasource. Durch sie wird festgelegt, mit welchem Konnektor-Typ, welchem Parser und welcher Index-Pipeline Daten aus einer bestimmten Quelle indexiert werden.
- Wir navigieren wieder im Hauptmenü zum Punkt „Indexing“ und wählen dort diesmal den Unterpunkt „Datasources“. Durch das Klicken auf „Add +“ öffnet sich ein Dropdown mit einer Liste an möglichen Konnektoren.
- Wir tippen in die Suchleiste „File“. Dadurch sollte unter „not installed“ der Konnektor „Fileupload (classic)“ gelistet werden. Wir klicken darauf, um ihn zu installieren.
- Nach etwa einer Sekunde wird der File-Uploader dann unter „Installed“ angezeigt. Wir klicken darauf und es öffnet sich ein Fenster, in dem die Datasource konfiguriert werden kann.
- Hier vergeben wir eine ID für die Datasource, beispielsweise „demo-datasource“, und geben die Index-Pipeline-ID („demo-index-pipeline“) und die Parser-ID („demo-parser“) der eben erstellten Objekte an. Wenn gewünscht, kann auch eine Beschreibung ergänzt werden.
- Unter dem Punkt „File Upload“ klicken wir auf „Datei auswählen“. Hier müssen wir zur gewünschten Datei navigieren, auswählen und bestätigen. Anschließend nicht vergessen, mit „Upload File“ die Datei tatsächlich auch hochzuladen. Im Feld rechts unter „File ID“ sollte der Dokumentname erscheinen.
- Mit „Save“ bestätigen.
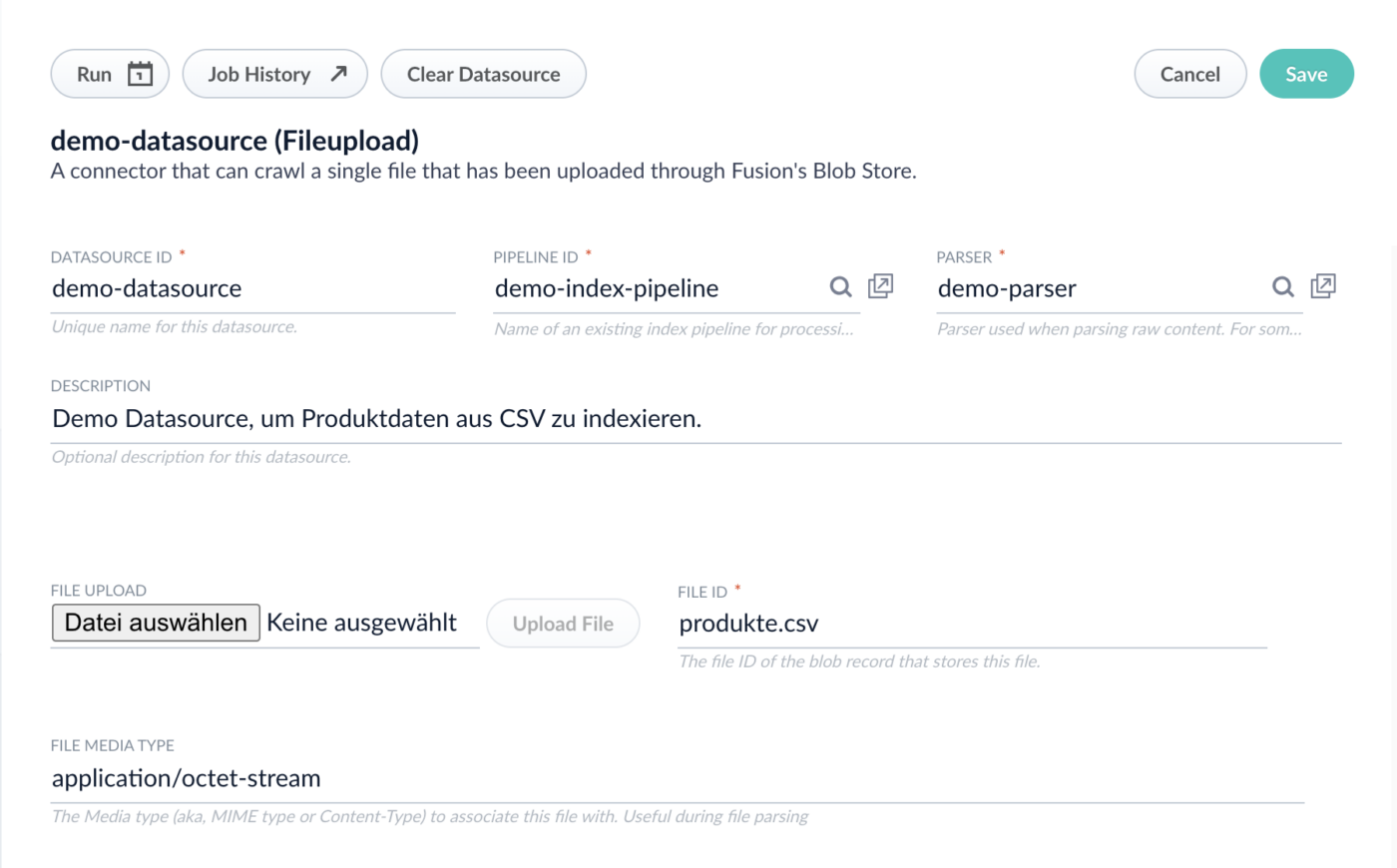
Die Datasource in Lucidworks Fusion ausführen
Nun ist schon alles bereit, um das Indexieren zu starten. Dafür müssen wir die Datasource ausführen. Eine Datasource kann man zu einem beliebigen Zeitpunkt manuell anstoßen. Alternativ kann man auch ein automatisches Ausführen, beispielsweise jede Nacht um 2 Uhr, konfigurieren.
Für diese Demo werden wir sie folgendermaßen manuell starten:
- Wir befinden uns weiterhin im Fenster der „demo-datasource“. Hier wählen wir „Run“, wodurch sich ein kleines Fenster öffnet. Hier klicken wir auf „Start“.
- Nach kurzer Zeit sollte die Meldung „Success“ und ein kleines Sonnensymbol erscheinen. Dies zeigt an, dass der Indexierungsprozess erfolgreich ausgeführt wurde.
Lucidworks Fusion: Query Workbench
Nun können wir die Daten durchsuchen. Eine praktische Oberfläche zu Testzwecken ist Fusions sogenannte Query Workbench:
- Im Hauptmenü links wählen wir unter „Querying“ den Punkt „Query Workbench“.
- Im Normalfall wird bereits automatisch eine Query-Pipeline geladen und eine sogenannte Match-All-Query (*:*) ausgeführt. Diese listet alle Dokumente im Index auf.
- Natürlich kann auch ein oder mehrere beliebige Suchbegriffe in die Suchleiste eingegeben werden.
- Möchten wir die Darstellung der Suchergebnisse ändern, können wir unter „Display Fields“ bestimmte Felder als Anzeigename und –beschreibung setzen. Ich wähle hier „ProduktName_t“und „Description_t“.
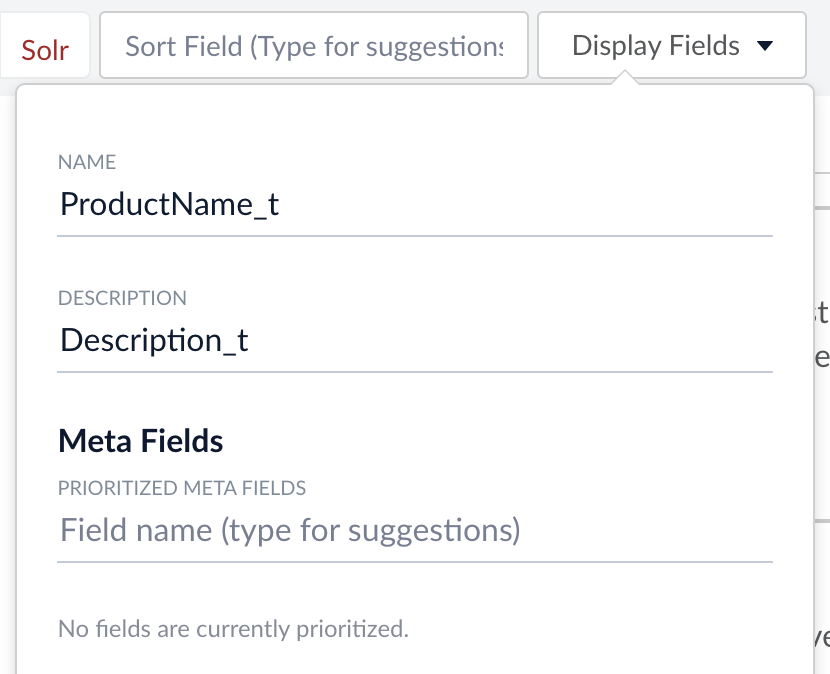
Übrigens können wir mittels „show fields“ bzw. „hide fields“ alle indexierten Felder zeigen oder verbergen. Auch sieht man am unteren Rand der Suchergebnisse die Anzahl der Treffer. Hier sind es 12, es wurden also alle Zeilen der CSV-Datei erfolgreich indexiert.
Spracherkennung in Lucidworks Fusion durchführen
Wir haben also mit geringem Konfigurationsaufwand unsere Daten erfolgreich in Fusion geladen und sie so durchsuchbar gemacht. Natürlich können wir unseren Indexierungsprozess noch verfeinern oder „aufpeppen“. Vielleicht ist Ihnen ja zu Beginn aufgefallen, dass das CSV-Dokument sowohl deutsche, englische als auch italienische Artikelbeschreibungen enthält. Daher möchte ich im Folgenden zeigen, wie man die Index-Pipeline erweitern kann, um die Sprache der Dokumente zu bestimmen.
Dazu müssen wir zunächst unsere Index-Pipeline anpassen:
- Im Hauptmenü wählen wir „Indexing“ > „Index Pipelines“.
- Hier wählen wir die vorhin erstellte „demo-index-pipeline“. Es öffnet sich ein Fenster, in dem wir die Pipeline anpassen können.
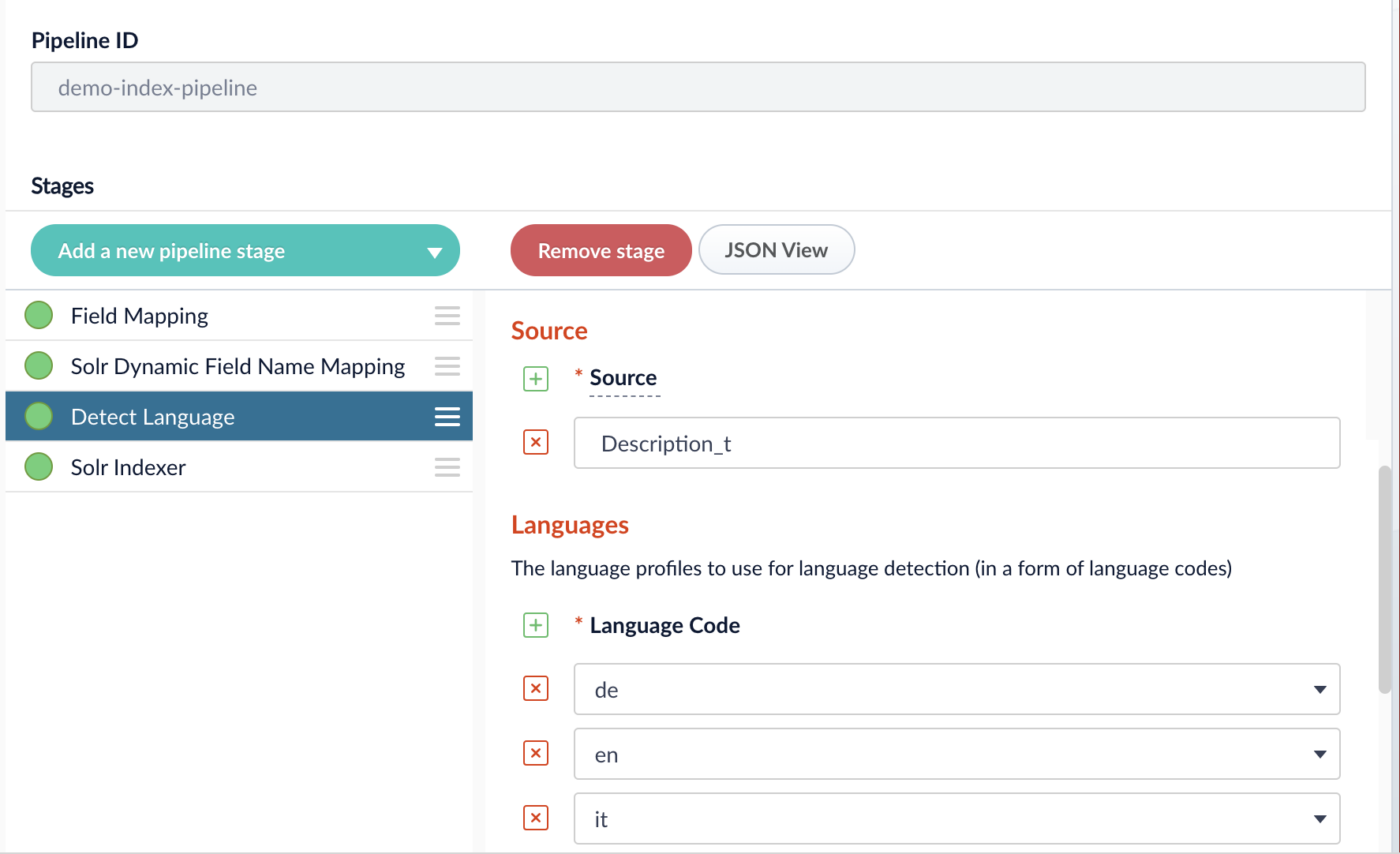
- Wir wählen „Add a new pipeline stage“ und wähle die „Detect Language“ Stage.
- Unter „Source“ setzen wir „Description_t“. Dies ist nämlich das Feld, in dem unsere Produktbeschreibungen indexiert wurden.
- Bei „languages“ wählen wir die Länderkürzel der erwarteten Sprachen aus dem Dropdown: „de“, „en“ und „it“.
- Wir verschieben die „Detect Language“ Stage vor die „Solr Indexer“ Stage. Dies geht mittels Drag&Drop.
- Abschließend bestätigen wir mit „Save“.
Um die Spracherkennung durchzuführen, müssen wir unsere Daten mit der neuen Index-Pipeline-Konfiguration noch einmal neu indexieren. Wir starten dazu einfach genau wie vorhin die Datasource. Die Daten müssen vorher nicht gelöscht werden, da Fusion die Dokumente durch die Produkt-ID zuordnen kann und beim Neuindexieren einfach überschreibt. Wir führen also folgende Schritte durch:
- Im Hauptmenü navigieren wir zu „Indexing“ > „Datasources“.
- Wir wählen die vorhin erstellte Datasource „demo-datasource“.
- Wir klicken auf „Run“ und „Start“.
- Wieder sollte nach kurzer Zeit eine Erfolgsmeldung erscheinen.
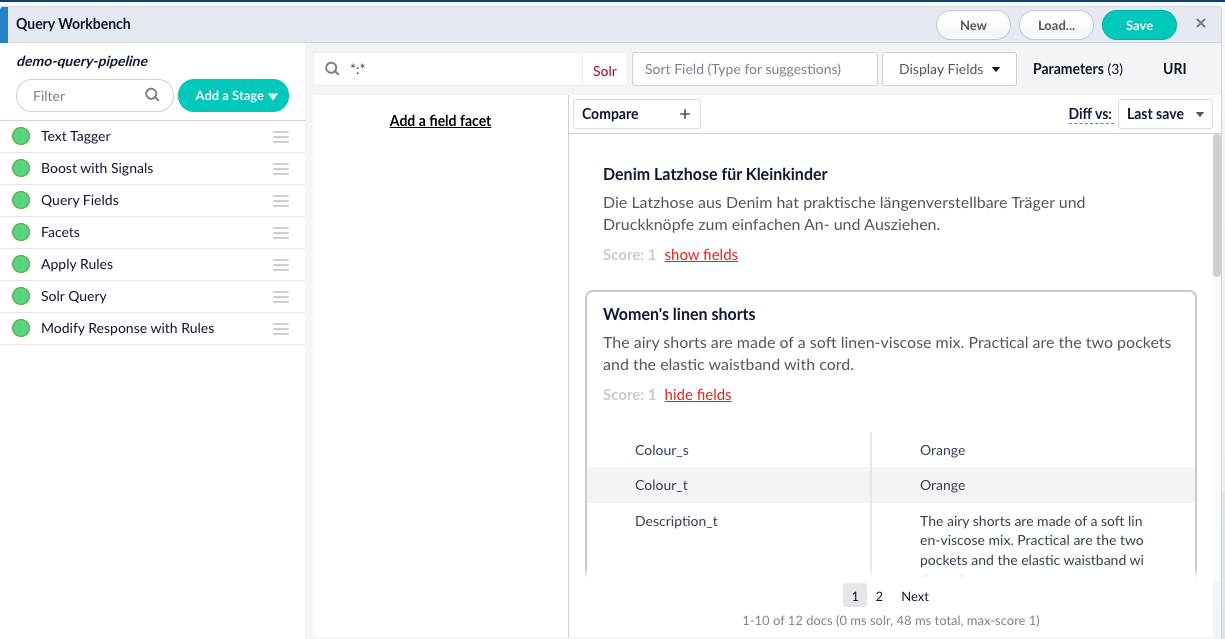
Dass die Spracherkennung geklappt hat, können wir in der Query Workbench nachvollziehen:
- Im Hauptmenü links wählen wir unter „Querying“ den Punkt „Query Workbench“.
- Durch die automatisch ausgeführte Match-All-Query (*:*) erscheint die Liste alle Dokumente im Index.
- Wir können nun als Beschreibungsfeld unter „Display Fields“ den Wert „attr_Description_t_lang_“ setzen. Dies ist nämlich der Name des Feldes, das durch die „Language Detection“ Stage erzeugt und mit der erkannten Sprache befüllt wurde.
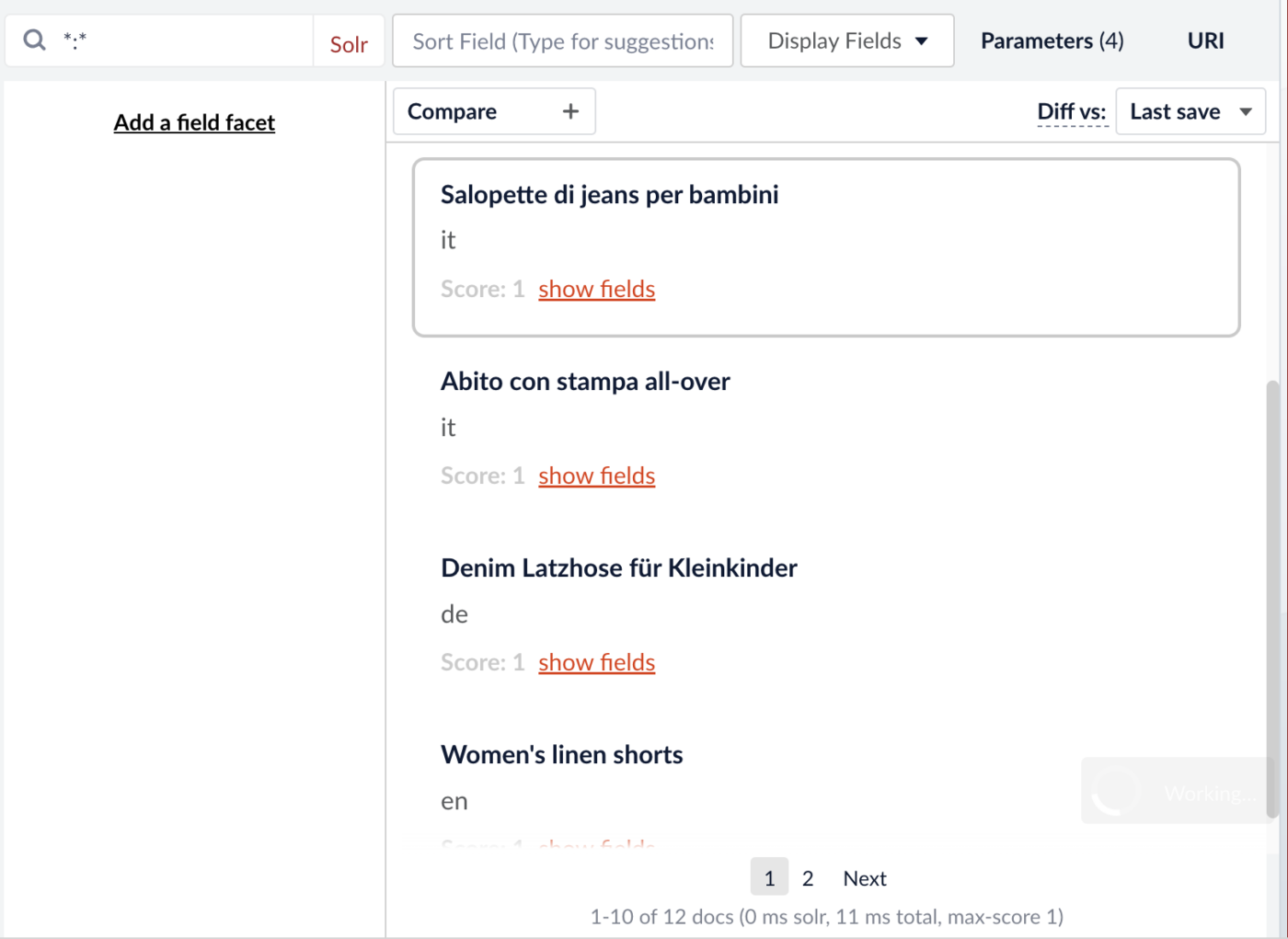
Die Ergebnisliste zeigt uns nun übersichtlich, dass alle Dokumente der richtigen Sprache zugeordnet wurden.
Ich hoffe, ich konnte Ihnen in diesem Blogbeitrag zeigen, dass die Datenindexierung in Fusion durch die vorgefertigten Konnektoren und Parser- bzw. Index-Pipeline-Stufen einerseits sehr einfach ist, andererseits aber auch stark auf die eigenen Daten und Bedürfnisse angepasst werden kann.


