

Am 13.09.2012 durften wir Apache Solr als Suchplattform für Enterprise Search im Rahmen eines Vortrages in Stuttgart bei der dort ansässigen Java User Group (JUGS) vorstellen. In diesem Beitrag möchten wir einige interessante Aspekte des Vortrags aufgreifen und eine Zusammenfassung über die Antworten auf die aufgetauchten Fragen geben.
Skalierbarkeit von Solr
Hat Solr Grenzen, wenn es um die Anzahl der Dokumente bzw. die Größe der Daten geht? Auf diese Frage gibt es nicht „die richtige“ Antwort. Generell ist festzuhalten, dass Solr die Möglichkeit bietet Daten zu skalieren. Wenn es darum geht Daten zu indexieren, gibt es die Möglichkeit sogenanntes Sharding einzusetzen, d.h. die zu indexierende Datenmenge auf mehrere Shards (unabhängige Indexe) zu verteilen. Suchen werden auf allen Shards durchgeführt, die Ergebnisse danach zusammengefasst.
Bei der Verarbeitung von einem großen Volumen von Suchanfragen bietet sich der Einsatz von Replication an. Hier wird die Indexierung von einem Master durchgeführt und dieser dann auf mehrere Slaves repliziert.
Natürlich können Sharding und Replication auch miteinander kombiniert werden. Das ergibt bildlich folgende Architektur:
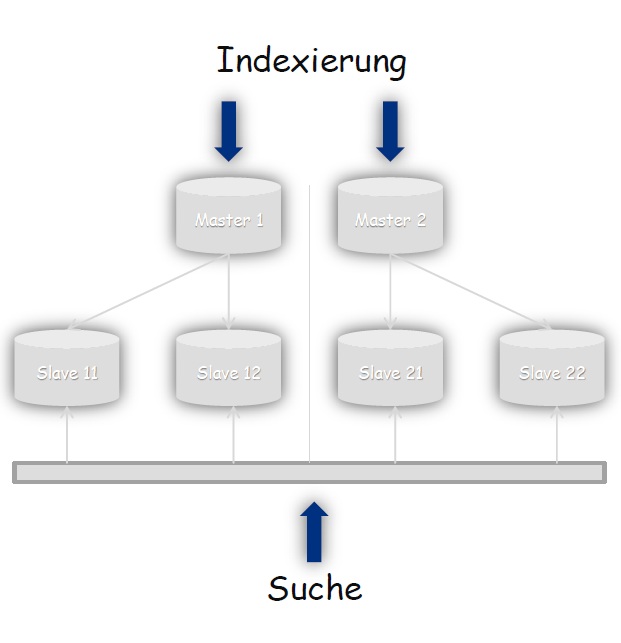
Natürlich gibt es weiterhin die Möglichkeit Software einzusetzen, die mit großen Datenmengen umgehen kann. In diesem Blog wird beschrieben, wie Hadoop und Behemoth zusammen mit SolrCloud dazu benutzt werden können Dokumentenmengen größer 1 Milliarde zu indexieren.
Indexierung von Datenbanken mit dem DataImportHandler
Der DataImportHandler ist ein RequestHandler, der dahingehend konfiguriert werden dann, dass Daten direkt aus einer Datenbank indexiert werden können. Dazu muss in der solrconfig.xml ein RequestHandler für jede DataImportHandler-Konfiguration definiert werden. Hier eine einfache Beispielkonfiguration:
In dem Parameter „config“ wird angegeben, wie der DataImportHandler agieren soll. Nachfolgend ein Bild, welches eine JDBC Datenbank als Datenquelle indexiert.

In der datasource wird die Datenquelle festgelegt, samt Ort der Datenquelle, Benutzername, Passwort, Treiber. Nachfolgend wird festgelegt, was einem Solr-Dokument entspricht. Hier besteht ein Dokument aus den Feldern id und name. Hier wird auch der select-Befehl definiert, mit welchem die Daten aus der Datenbank gezogen werden sollen.
Diese Konfigurationsdatei wird im conf-Ordner von Solr abgelegt. Über die entsprechende Admin-Seite hat man dann Zugriff auf den Datenimport mit dieser Konfiguration.
Mehrsprachigkeit
Solr bietet „out of the box“ die Möglichkeit, die Sprache zu indexierender Dokumente zu identifizieren. Diese Ergebnisse können dann für die Darstellung von Sprachen als Facetten benutzt werden. Wie man die Sprachenidentifizierung in Solr einbaut und welche Parameter Solr bietet können Sie in diesem Blogbeitrag nachlesen.
Ab Solr 4.0 werden schon viele sprachspezifische Feldtypen vorkonfiguriert in der solrconfig.xml mitgeliefert, in denen schon passende Analyseprozesse eingebunden sind. Es sind beispielsweise schon vorgefertigte Stopwortlisten in mehreren Sprachen vorhanden, für einige Feldtypen sind passende Stemming-Filter eingebunden etc.
Behandlung von Fehlern, die sehr häufig vorkommen
Manche Fehler können unter Umständen sehr häufig in einem Dokumentenbestand vorkommen. Ein Beispiel hierfür wäre eine Suche auf dem internen E-Mail-Verkehr. Buchstabendreher in Firmen- oder Personennamen, Tippfehler in Begrüßungs- oder Abschiedsfloskeln können durchaus relativ häufig auftreten. Dies ist problematisch, wenn man eine Spellcheck- oder Autosuggest-Komponente einbauen möchte. In der Regel sind falsch geschriebene Wörter nicht erwünscht, wenn alternative Suchbegriffe zu vermeintlich falsch geschriebenen Suchanfragen vorgeschlagen werden sollen oder fehlerhafte Begriffe beim Tippen angeboten werden.
In der Spellcheck-Komponente bietet sich der Parameter spellcheck.onlyMorePopular an. Dieser Parameter verhindert, dass Wörter vorgeschlagen werden, die seltener im Index sind, als der Suchbegriff selbst.
Die Autosuggest-Komponente hat einen Parameter, der einen Schwellenwert festlegt, über dem jeder Begriff liegen muss, der über diese Komponente vorgeschlagen wird. Der Parameter threshold akzeptiert eine Gleitkommazahl, die zwischen 0 und 1 liegen muss. Bei einem Schwellenwert von 0.1 muss jeder Begriff, der vorgeschlagen wird, in mindestens 10% der Dokumente vorhanden sein.
Diese beiden Parameter können helfen ein Problem häufig falsch geschriebener Wörter in den Griff zu bekommen.
Abschließend möchten wir uns dafür bedanken, diesen Vortrag halten zu dürfen und für die interessanten Fragen und angenehme Diskussionsrunde bedanken.
Weiterführende Links
DataImporthandler – Solr Wiki
SpellCheckComponent – Solr Wiki
Suggester – Solr Wiki
Apache Solr
Java User Group Stuttgart


