

Solr und das Datenformatierungsproblem
Wer schon einmal mit Solr gearbeitet hat, wird festgestellt haben, dass Solr dazu in der Lage ist, mit verschiedenen Datenformaten umzugehen. Sei es XML, CSV oder JSON – es ist für jeden was dabei. Es dauert nur wenige Klicks und die Daten sind erfolgreich in Solr indexiert und die Suche kann beginnen. In der Praxis ist es jedoch äußerst selten der Fall, dass Daten exakt in dem Format vorliegen, mit dem das Zielsystem, in diesem Beispiel Solr, arbeiten kann. Doch was tut man, wenn die vorhandenen Daten in einem Format vorliegen, welches für den Benutzer, in Anbetracht eines bestimmten Use Cases, unbrauchbar ist? Wie kann man schnell seine Daten in das gewünschte Format überführen? Ein geläufiges Tool, das diese und weitere ähnliche Fragestellungen zügig und simpel beantworten kann, ist Apache NiFi.
Was ist NiFi und wie funktioniert es? – Ein einführendes Beispiel ins Record Processing
Apache NiFi ist eine Open-Source Software, die dabei hilft den Datenfluss zwischen unterschiedlichen Systemen zu konfigurieren. Es beherbergt viele verschiedene Funktionen, unter anderem die der Datentransformation. Dieser Beitrag soll hierbei einen Überblick darüber verschaffen, wie man einen XML-Datensatz mittels NiFi in JSON umwandelt, um es anschließend in Solr zu indexieren. Wir verwenden an dieser Stelle die Version 1.9.2 von NiFi.
Ausgangssituation:
Es liegt eine Datei namens test im XML-Format mit folgendem Inhalt vor:
<id>SP2514N</id>
<name>Samsung SpinPoint P120 SP2514N – hard drive – 250 GB – ATA-133</name>
<manu>Samsung Electronics Co. Ltd.</manu>
<manu_id_s>samsung</manu_id_s>
<cat>electronics</cat>
<features>7200RPM, 8MB cache, IDE Ultra ATA-133</features>
<price>92.0</price>
<popularity>6</popularity>
<inStock>true</inStock>
<manufacturedate_dt>2006-02-13T15:26:37Z</manufacturedate_dt>
<store>35.0752,-97.032</store>
Des Weiteren liegt eine Solr Collection namens test vor. Folgender curl Befehl zeigt, dass die Collection aktuell keine Dokumente beinhaltet:
curl http://localhost:8983/solr/test/select?indent=on&q=*:*
Solr-Response:
{ "responseHeader":{ "zkConnected":true, "status":0, "QTime":1, "params":{ "q":"*:*", "indent":"on"}}, "response":{"numFound":0,"start":0,"docs":[] }}
An dieser Stelle sei angemerkt, dass hier die Solr-Version 8.1.1 in Gebrauch ist.
Ziel: Eine erfolgreiche Umwandlung von XML in JSON per Record Processing mit NiFi und anschließender Indexierung in Solr.
Vorgehensweise Record Processing
Variablen anlegen
Um einen späteren NiFi Workflow nicht jedes Mal neu anpassen zu müssen, wenn dieser auf ein anderes System übertragen wird, bietet es sich an, grundlegende Variablen anzulegen.
- Input_Directory (Ausgangsverzeichnis, welches den umzuwandelnden Datensatz enthält)
- Solr_ZK_Host (Zookeeper-Host & Port; localhost:9983 in diesem Beispiel)
- Solr_Collection (Name der Collection test, in die der Datensatz indexiert werden muss)
Mit Rechtsklick auf das NiFi-Canvas gelangt man zu einem Menü und wählt dann „Variables“. Hier kann man mit einem Klick auf das Plus Symbol die oben erwähnten Variablen hinzufügen, diese mit Namen versehen und sie im nächsten Schritt gleich mit den richtigen Werten ausstatten. Mit Apply werden die Variablen endgültig erstellt. In diesem Fall liegt die Beispieldatei im XML-Format auf dem Desktop im Ordner test vor. Die spätere Solr Collection soll ebenfalls test heißen. Der Wert für die Variable Solr_ZK_Host wird auf localhost:9983 festgelegt, da man davon ausgeht, dass Solr im Cloudmodus(!) gestartet wird. Bestimme die Variablen gemäß dieser Tabelle:
| Name | Wert |
| Input_Directory | /Users/SeHo/Desktop/test |
| Solr_Collection | test |
| Solr_ZK_Host | localhost:9983 |
Record Processing Workflow erstellen
Um die XML-Beispieldatei in JSON umzuwandeln und diese in Solr zu indexieren, benötigt man die folgenden Prozessoren:
- GetFile
- ConvertRecord
- PutSolrRecord
Die drei Prozessoren müssen außerdem folgendermaßen konfiguriert werden:[/shi_custom_list][shi_custom_list checkbox=““]
| Prozessor | Property | Wert |
| GetFile | Input Directory | ${Input_Directory} |
| Recurse Subdirectories | false | |
| ConvertRecord | Record Reader | XMLReader |
| Record Writer | JsonRecordSetWriter | |
| PutSolrRecord | Solr Type | Cloud |
| Solr Location | ${Solr_ZK_Host} | |
| Collection | ${Solr_Collection} | |
| Record Reader | JsonTreeReader |
Sowohl beim Record Reader als auch beim Record Writer werden im Hintergrund sogenannte Controller Services erstellt, die für das Lesen bzw. Schreiben der Records dienen. Diese sind für die „Magie“ der Datentransformation zuständig.
Folgende Relationships sind für dieses Beispiel auf Auto-Terminierung zu setzen:
| Prozessor | Automatically Terminate Relationships |
| ConvertRecord | failure |
| PutSolrRecord | connection_failure |
| failure | |
| success |
Last but not least: Zur Aktivierung der konfigurierten Controller Services muss nun mit Rechtsklick auf das NiFi-Canvas „Configure“ gewählt werden. Im Reiter „CONTROLLER SERVICES“ können nun Reader und Writer mit einem Klick auf das Blitz Symbol und anschließender Bestätigung durch ENABLE aktiviert werden.
Im Erfolgsfall sollte der Record Processing Workflow für eine Umwandlung von XML zu JSON und eine Indexierung in Solr diese Ansicht haben:
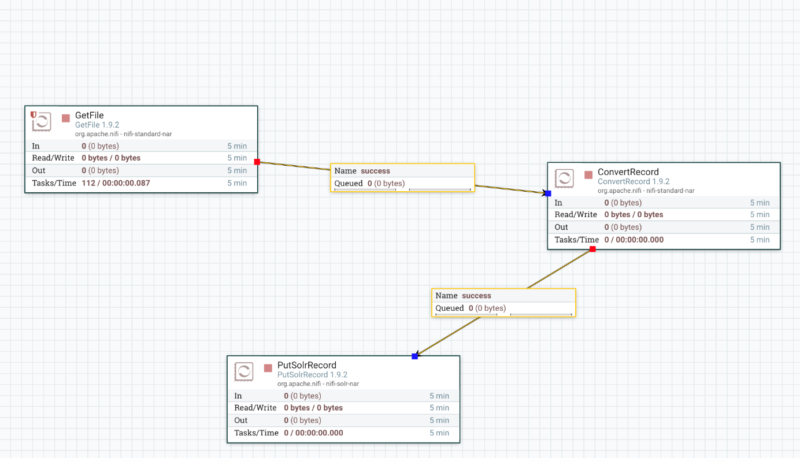
Führt man den Workflow nun mit allen drei Prozessoren aus, wird der Datensatz mit dem GetFile Prozessor eingelesen, mit ConvertRecord in JSON umgewandelt und PutSolrRecord schlussendlich in die Solr Collection indexiert. Mit dem obig erwähnten curl Befehl kann man erneut den Datenbestand der Collection test abrufen und sollte dabei diesen Output erhalten:
{ "responseHeader":{ "zkConnected":true, "status":0, "QTime":0, "params":{ "q":"*:*", "indent":"on"}}, "response":{"numFound":1,"start":0,"docs":[ { "id":"SP2514N", "name":["Samsung SpinPoint P120 SP2514N - hard drive - 250 GB - ATA-133"], "manu":["Samsung Electronics Co. Ltd."], "manu_id_s":"samsung", "cat":["electronics"], "features":["7200RPM, 8MB cache, IDE Ultra ATA-133"], "price":[92.0], "popularity":[6], "inStock":[true], "manufacturedate_dt":"2006-02-13T15:26:37Z", "store":["35.0752,-97.032"], "_version_":1645654424339611648}] }}
Die Datentransformation ist geglückt: die Collection test ist nicht mehr leer, sondern verfügt über das indexierte Dokument, welches den Inhalt des eingangs genannten Datensatzes hat.
Fazit
Die Record Processors von NiFi erlauben einem eine schnellere und formatunabhängigere Transformation und Verarbeitung von Daten als andere NiFi Elemente, wie zum Beispiel TransformXML. Würde man die Umwandlung in JSON und Indexierung in Solr mithilfe von TransformXML vornehmen, müsste programmintern erst ein neues FlowFile kreiert werden, welches dann mit transformiertem Gehalt indexiert und weitergeleitet wird, während ein Record Processor das vorhandene Orginalfile gleich umwandelt und im dargestellten Fall indexiert. Auch muss man kein extra Skript verfassen, um eine erfolgreiche Datentransformation von XML nach JSON durchzuführen, sondern kann auf dem NiFi-Canvas direkt loslegen. Record Processors erlauben auch die Verwendung eines Schemas, was weitere Kontrolle über die Datenverarbeitung erlaubt. Apache NiFi ist ein äußerst nützliches ETL-Tool, welches die Kommunikation mit Solr um Vielfaches erleichtert und die Arbeitsabläufe optimiert. Durch seine große Auswahl an Funktionen und Möglichkeiten, lässt sich auch das komplizierteste Data Processing Problem innerhalb angemessener Zeit lösen, wodurch NiFi auch außerhalb des Solr-Kontexts zu einem unverzichtbaren Werkzeug wird. Bedingt durch seine benutzerfreundliche graphische Oberfläche und die Tatsache, dass es schon fast spielerisch leicht zu erlernen ist, lohnt es sich auch für Neulinge und Quereinsteiger nicht nur auf dem Gebiet der intelligenten Volltextsuche, einen genauen Blick auf NiFi zu werfen, um nicht nur des schnellen Record Processing Herr zu werden, sondern auch in Zukunft komplexere Aufgaben zu übernehmen.


