

In einem früheren Beitrag bin ich bereits etwas näher auf das Thema Stemming in der Analysekette von Solr (https://www.shi-gmbh.com/blog/solr-analysekette-stemming/) eingegangen. Neben der Bedeutung von Stemming für die Suchtechnologie habe ich auch den Einsatz des Porter-Stemmers in Solr beschrieben, ebenso wie die Erweiterungen durch den KeywordMarkerFilter (Wörter als Keywords markieren, um Stemming zu vermeiden) und den StemmerOverrideFilter (eigene Stemming-Regeln definieren).
In diesem Artikel möchte ich den Hunspell Stemmer inklusive dessen Stärken und Schwächen etwas näher beleuchten und wie Sie mit diesen umgehen können.
Während der Porter-Stemmer rein algorithmisch Endungen von Wörtern löscht und somit recht starr und für die Deutsche Sprache aufgrund ihrer starken Flexion nur mäßig geeignet ist, ist der Hunspell Stemmer ein hybridischer Ansatz, der einerseits auf Regeln und andererseits auf einem oder mehreren Wörterbüchern basiert. Für diese Regeln und Wörterbücher können Sie auf diejenigen zugreifen, die auch bei Open Office zur Rechtschreibkorrektur verwendet werden bzw. wurden. Die Wörterbuchdateien konnten Sie früher über https://wiki.openoffice.org/wiki/Dictionaries herunterladen. Seit jedoch Open Office in den aktuellen Versionen über sogenannte Extensions erweiterbar ist, können Sie die Wort- und Regellisten nicht mehr dort herunterladen. Wir stellen sie Ihnen am Ende dieses Beitrags jedoch bereit. Die Datei de_DE_frami.dic beinhaltet 220.000 Wörter, de_DE_frami.aff beinhaltet über 500 Regeln.
Wie funktioniert der Hunspell Stemmer?
Damit eine Vollform, d.h. eine flektierte Form einer Grundform (billiger vs. billig), auf deren Stamm reduziert wird, sind mehrere Voraussetzungen notwendig. Es muss eine Regel vorhanden sein, die besagt, dass die Endung er „abgeschnitten“ werden muss, um von einer Vollform zu einer Grundform zu gelangen. Und dieser Regel müssen natürlich auch Wörter zugeordnet sein, denn diese Regel gilt ja nicht für alle Wörter. Ausnahmen für diese Regel sind unter anderem: besser, Messer, Leuchter, Computer.
Erstellen einer Wörterbuch- und Regeldatei
Eine zulässige Wörterbuchdatei besteht aus mehreren Teilen: Dem Encoding, einem zulässigen Zeichensatz und den Regeln.
Das Encoding bildet die erste nicht-leere und nicht-auskommentierte Zeile:
SET ISO8859-1
Es folgt der zulässige Zeichensatz. Nachfolgend ein für die deutsche Sprache zulässiger Zeichensatz:
TRY esijanrtolcdugmphbyfvkwqxzäüößESTJANRTOLCDUGMPHBYFVKWQXZÄÜÖ-.
Schließlich der interessante Teil: Die Regeln. Regeln bestehen aus zwei Teilen. Die erste Zeile jeder Regel definiert, ob es sich um ein Präfix (PFX) oder ein Suffix (SFX) handelt, legt einen Identifier fest (z.B. ein Buchstabe) und ob diese Regel mit anderen Präfixen bzw. Suffixen kombiniert werden kann. Als letztes Element wird noch die Anzahl der Ausprägungen dieser Regel genannt. An einem Beispiel erläutert:
SFX S Y 2
Es handelt sich um eine Suffix-Definition(SFX), die durch den Identifier S referenziert wird, mit anderen Präfixen oder Suffixen kombiniert werden kann (Y) und zwei konkrete Ausprägungen hat (2).
Es folgen im Anschluss genau so viele Ausprägungen dieser Regel wie definiert wurden. Diese Ausprägungen bestehen aus fünf Elementen. Die ersten beiden (PFX oder SFX, Identifier) müssen mit der Regeldeklaration übereinstimmen. Danach wird eine Zahl angegeben. Diese Zahl steht für die Zeichen, die vom Präfix bzw. Suffix übrig gelassen werden sollen. An vierter Stelle kommt das tatsächliche Präfix bzw. Suffix. Abschließend noch eine Einschränkung, die zutreffen muss, damit diese Regel auch angewandt wird. Zu obiger Regeldeklaration habe ich die beiden folgenden Regelausprägungen in eine Wörterbuchdatei test.aff zusätzlich zum Encoding und Zeichensatz geschrieben:
SFX S 0 sten SFX S 0 er
Die beiden Regeln sollen dazu dienen, Steigerungsformen wie billiger und billigsten auf ihre Grundformen zu reduzieren, also in diesem Beispiel zu billig. Die Einschränkung am Ende besagt, dass das Suffix in keinem der beiden Fälle den Buchstaben im Array (y) folgen darf. Ohne den Zirkumflex müsste das Suffix auf diesen Buchstaben (y) folgen.
Die Datei sieht also folgendermaßen aus:
SET ISO8859-1 TRY esijanrtolcdugmphbyfvkwqxzäüößESIJANRTOLCDUGMPHBYFVKWQXZÄÜÖ-. SFX S Y 2 SFX S 0 sten SFX S 0 er
Als Nächstes muss ein Wörterbuch vorhanden sein, damit diese Regeln auch angewendet werden können. Dazu erstellen Sie eine Datei namens test.dic, welche Ihr Wörterbuch darstellen soll. In der ersten Zeile geben Sie die Anzahl der Einträge an, in den darauf folgenden Ihre Einträge:
1 #Beginn Wörterbucheinträge billig
Anwendung in Solr
Die beiden Dateien test.aff und test.dic legen Sie im conf-Verzeichnis Ihres Cores bzw. Ihrer Collection ab. Um diese beiden kleinen Wörterbuchdateien zu testen, können Sie folgende Feldtypen in Ihrem Schema anlegen:
fieldtype name="hunspell" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.HunspellStemFilterFactory" dictionary="test.dic" affix="test.aff" ignoreCase="true" /> </analyzer> </fieldtype>
Wenn Sie Solr anschließend erfolgreich gestartet haben, gehen Sie auf die Analyseseite, wählen als Feldtypen hunspell aus, geben in das Analysefeld billig billiger billigsten ein und lassen diesen Input analysieren. Sie sollten nun feststellen, dass alle drei Wörter des Inputs zu billig werden und so im Index abgelegt würden. Nachfolgende Abbildung zeigt Ihnen, wie Ihr Bildschirm aussehen sollte.
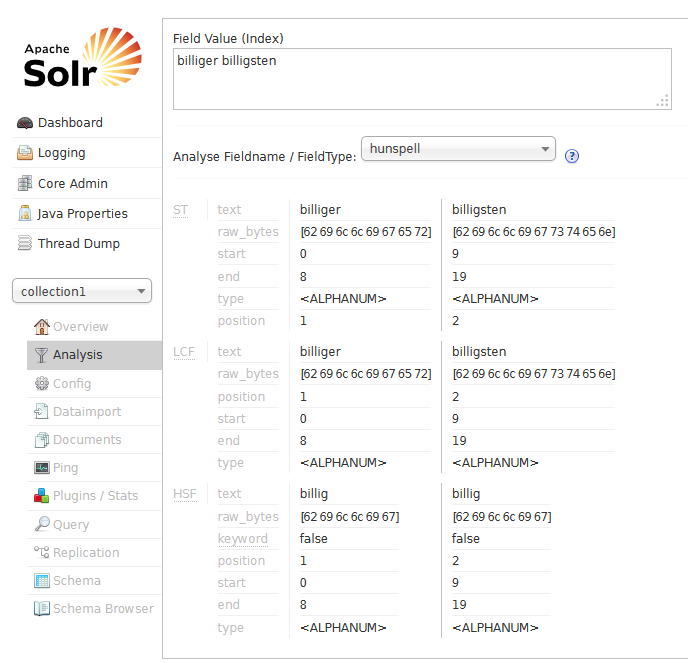
Fazit
Ein Stemming für Ihre Applikation einzurichten, ist insgesamt eine hochkomplexe Aufgabe. Im Moment haben wir für ein Wort zwei Regeln definiert. Die deutsche Sprache ist unfassbar komplex, weswegen ein perfektes Stemming eigentlich nicht möglich und ein sehr gutes recht aufwendig sein kann. Die Open Office Dateien können einen guten Einstieg geben und sind erweiterbar. Sie finden Sie etwas weiter unten zum herunterladen.
Natürlich gibt es den Hunspell Stemmer als Filter auch in Elasticsearch. Sie sind auch hier also technologisch frei, was den Suchserver angeht. Ich habe mich hier nur auf Solr konzentriert, denn die Analyse-Seite ist schnell erreichbar und zeigt einem sofort im Browser an, ob alles funktioniert hat. Elasticsearch kommt bekanntlich ohne Oberflächen und hat diese Prototyping-Möglichkeit also nicht.


