

Teil 7 der BLOGSERIE:

„Data-Driven Marketing: Wie kundenzentrierte Ansprache in Zukunft gelingt in 3 Schritten“
Lesen Sie hier die anderen Beiträge dieser Blogserie:
- Teil 1 „Herausforderung Customer Centricity: Wie etabliert ist Datenanalyse im E-Commerce?“
- Teil 2 „Mit Open Source Tools individuelle Reports erstellen“
- Teil 3 „Langfristige Kundenbindung mit Hilfe von „Advanced Analytics“
- Teil 4 „Wann bleiben die Kunden vor der Tür stehen? – Predictive Analytics mit Maschinellem Lernen“
- Teil 5 „Gezielte Kundenansprache dank KI“
- Teil 6 „Auf Interessen der Kunden reagieren: Intelligente Recommendations“
Drei Schritte zu mehr Erfolg im Marketing
Das Verhalten der Kunden wandelt sich andauernd, und die wachsende Anzahl an Kanälen und Berührungspunkten hat ambivalente Folgen. Auf der einen Seite ist es schwieriger denn je, den Kunden zu verstehen, das passende Angebot zu machen und zu entscheiden, welche Maßnahmen wirklich mehr Kunden in den Online-Shop bringen. Die Vielzahl an Daten, die an den verschiedenen Touchpoints entsteht, bietet andererseits aber die Chance, diese Fragen besser denn je zu beantworten.
Dieser Blog-Beitrag ist der letzte in unserer Serie zum Data-Driven-Marketing und eine Art Rückblick: Welche drei Schritte sind erforderlich, um mit Hilfe von Daten für mehr Erfolg im Marketing zu sorgen?
Schritt 1: Daten verfügbar machen
Eine der großen Herausforderungen beim fundierten Planen von Marketing-Maßnahmen ist es, die richtige Datengrundlage dafür zu schaffen. Je nach Fragestellung – zum Beispiel: Was suchen unsere Kunden im Online-Shop? – werden oft keine Daten erhoben, oder sie stecken in einem System, aus dem man sie nur schwer wieder herausholt.
Um mit Hilfe von Daten Erkenntnisse zu gewinnen, ist es in einem so dynamischen Umfeld wie im Marketing essenziell, Daten unternehmensweit verfügbar zu machen, sodass sie bei Bedarf jederzeit für eine bestimmte Analyse herangezogen werden können. Der Aufwand für den alternativen Weg – nämlich unterschiedliche Plattformen und einzelne Systeme miteinander zu integrieren – ist zu groß, um immer wieder neu entstehende Fragen schnell genug zu beantworten. Eine Grundvoraussetzung bei jeder längerfristigen datenbasierten Strategie ist eine zentrale Datenablage wie ein Data-Ware-House oder ein Data-Lake. Dort landen regelmäßig alle relevanten Daten in ausreichender Qualität und Aktualität, und alle können auf diese zugreifen.
Bei der Umsetzung eines zentralisierten, leicht zugänglichen Datenpools sollte man aber nicht nach dem Motto vorgehen: „Erstmal alle Daten sammeln. Wenn genügend Daten da sind, werden die Erkenntnisse von alleine kommen“. Bei diesem Ansatz dauert es gegebenenfalls sehr lange, bis die Daten genutzt werden können, der eigentliche Nutzen für das Marketing erst dann erkannt wird und das Vorhaben in Misskredit gerät.
Strategisch sinnvoller ist es, zunächst eine konkrete Fragestellung zu identifizieren; beispielsweise „Welche Interessen haben unsere längerfristigen Kunden?“. Davon ausgehend kann zielgerichtet nach Daten gesucht werden, die Licht in diese spezifische Dunkelheit bringen, und deren Qualität überprüft werden. Gleichzeitig entsteht dabei ein viel kleineres technisches Projekt als nach dem besagten Motto. Dieses lässt sich viel leichter handeln und rechtfertigen. Aus den Daten den gewünschten Nutzen zu ziehen, ist dann eine klar definierte Aufgabe mit abschätzbaren Aufwand. Die einzelnen Schritte werden im Folgenden beschrieben.
Der Start kann wie am Anfang unserer Serie denkbar einfach sein: Die Daten werden aus dem entsprechenden System regelmäßig exportiert und an bekannter Stelle zentral abgelegt. In unserem Fall wurden die Daten aus dem Web-Analytics-System extrahiert und auf unseren File-System-Data-Lake abgelegt.
Durchläuft man diesen Prozess mit neuen Fragestellungen immer wieder, lassen sich Schritt für Schritt alle relevanten Daten für das Marketing verwertbar machen und eine längerfristig angelegte Datenstrategie erarbeiten.
Schritt 2: Mit Daten die Realität betrachten
Stehen die relevanten Daten zur Verfügung, lässt sich die Ausgangs-Fragestellung schon mit einfachen Statistiken etwas näher beleuchten. Das können beispielweise eine Liste der meist gekauften Produkte und beliebten Kategorien oder andere spezielle KPIs wie durchschnittliche Warenkorbgröße sein.
Technisch lässt sich diese initiale Analyse, wie wir in Teil 2 der Serie gezeigt haben, ohne viel Aufwand und mit Open-Source Komponenten durchführen. Eine erste Datenexploration und einfache Analysen erfolgen mit Python und Apache Spark, wobei jupyter als Entwicklungsumgebung und erstes Report-Tool dient.
Sobald man dadurch ein Gefühl dafür bekommen hat, welche Statistiken und Metriken die Fragestellung am besten beleuchten könnten, veranschaulicht man diese am besten anschließend in Form eines Dashboards. Damit bekommen alle einen Einblick in die Daten. Durch die Visualisierung und zusätzliche Filtermöglichkeiten kann im Prinzip jeder Marketing-Mitarbeiter den Ist-Zustand und die Historie verfolgen und erste mögliche Zusammenhänge erfassen. Auch regelmäßige Reports kann er auf Basis eines Monitoring-Tools leicht erstellen, sodass eine Grundlage für erste datenbasierte Entscheidungen entsteht.
Die Analytics-Infrastruktur, die wir im Laufe der Blog-Serie aufgebaut haben, lässt sich sehr leicht ergänzen, um die relevanten Kennzahlen dauerhaft zu monitoren. Dafür setzen wir einfach Kibana ein, eine weitere Komponente des Elastic Stack, den wir in unserem Beitrag zum Thema Recommendations kennengelernt haben. Dort haben wir Elasticsearch genutzt, um dem Kunden bei seiner Suche in unserem Webshop passende Artikel zu empfehlen. Die Web-Analytics-Daten hatten wir dafür mit Hilfe von Apache Spark transformiert und anschließend in Elasticsearch abgespeichert, um dann mit den dort vorhandenen Analytics-Funktionen intelligente Recommendations auszuspielen.
Um das Monitoren von Produktverkäufen zu realisieren, verfolgen wir im Prinzip denselben Ansatz. Abbildung 1 gibt einen Überblick über die Architektur. Wir lesen wieder die Web-Analytics-Daten in Spark ein, transformieren diese, um die wichtigsten Merkmale von Produktbestellungen zu extrahieren, und speichern das Ergebnis in Elasticsearch ab. Diesmal greifen wir jedoch mit Kibana auf die Daten in Elasticsearch zu, um dessen vielfältige Möglichkeiten zur Visualisierung für einen Dashboard zu nutzen.
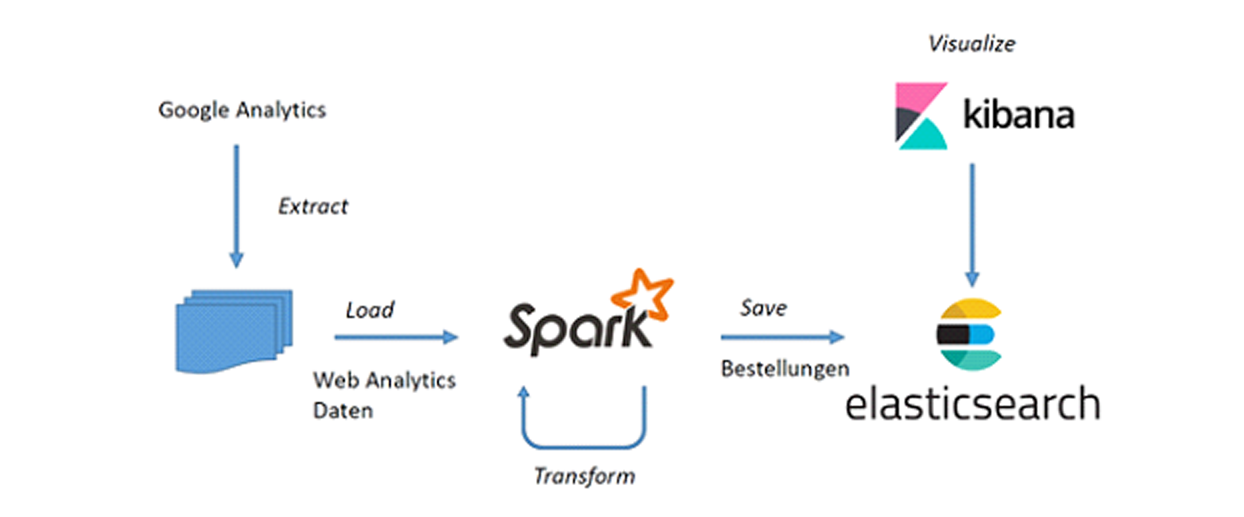
Die Konfiguration eines Dashboards erfolgt mit wenigen Clicks. Die Visualisierung führt auf Anhieb die wichtigsten Kanäle für Verkäufe (Abbildung 2) oder saisonale Trends vor Augen (Abbildung 3, Abbildung 4). Weitere Exploration mit Hilfe von Filtern erlaubt es, bestimmte Zusammenhänge zu erkennen (Abbildung 4, Abbildung 5). Damit gewinnen wir ein präzises Bild von Historie und Ist-Zustand und können neue Fragestellungen entwickeln, die unsere Marketing-Aktivitäten unterstützen.
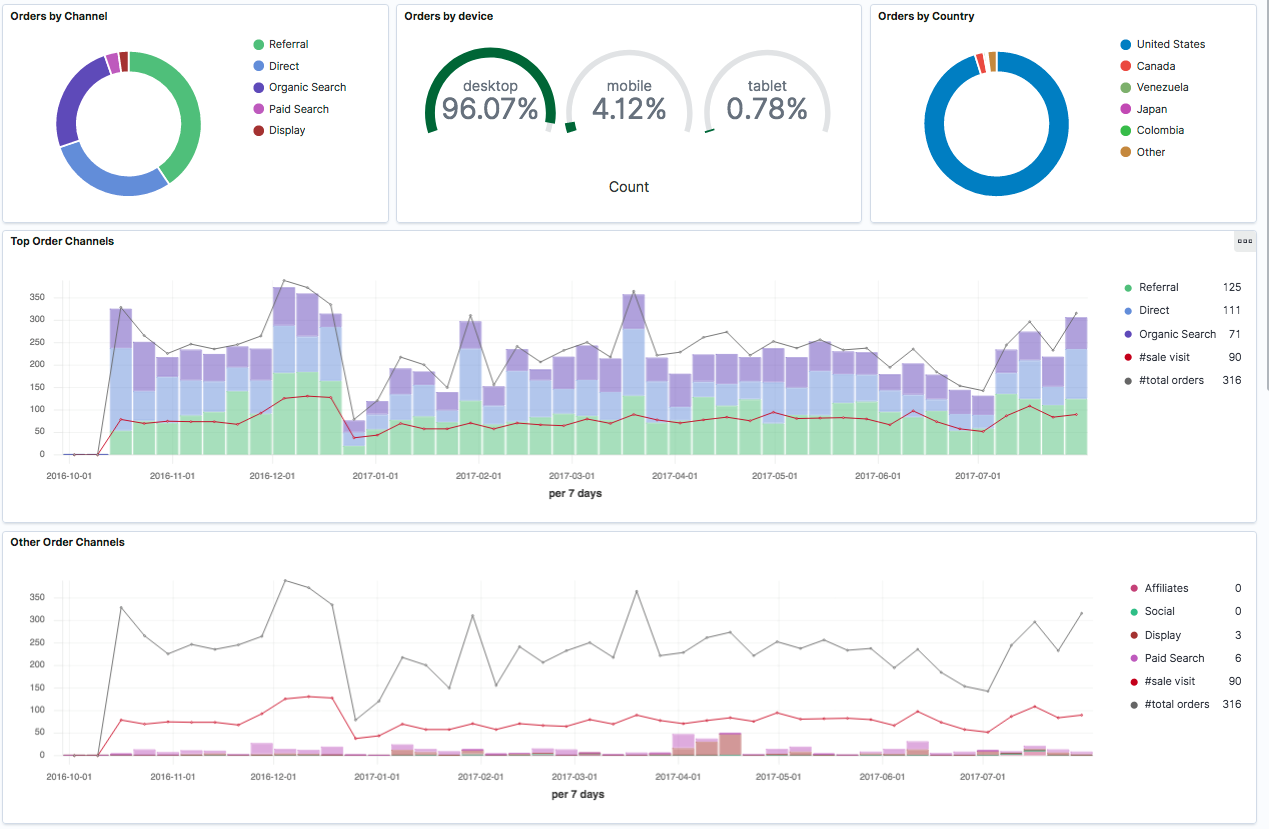
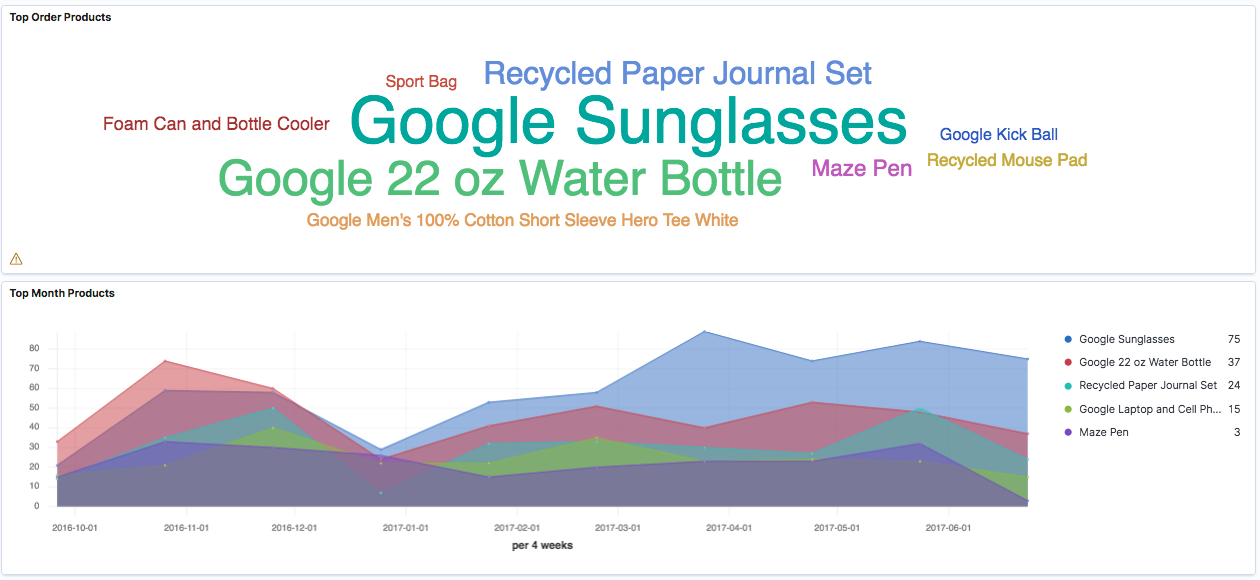
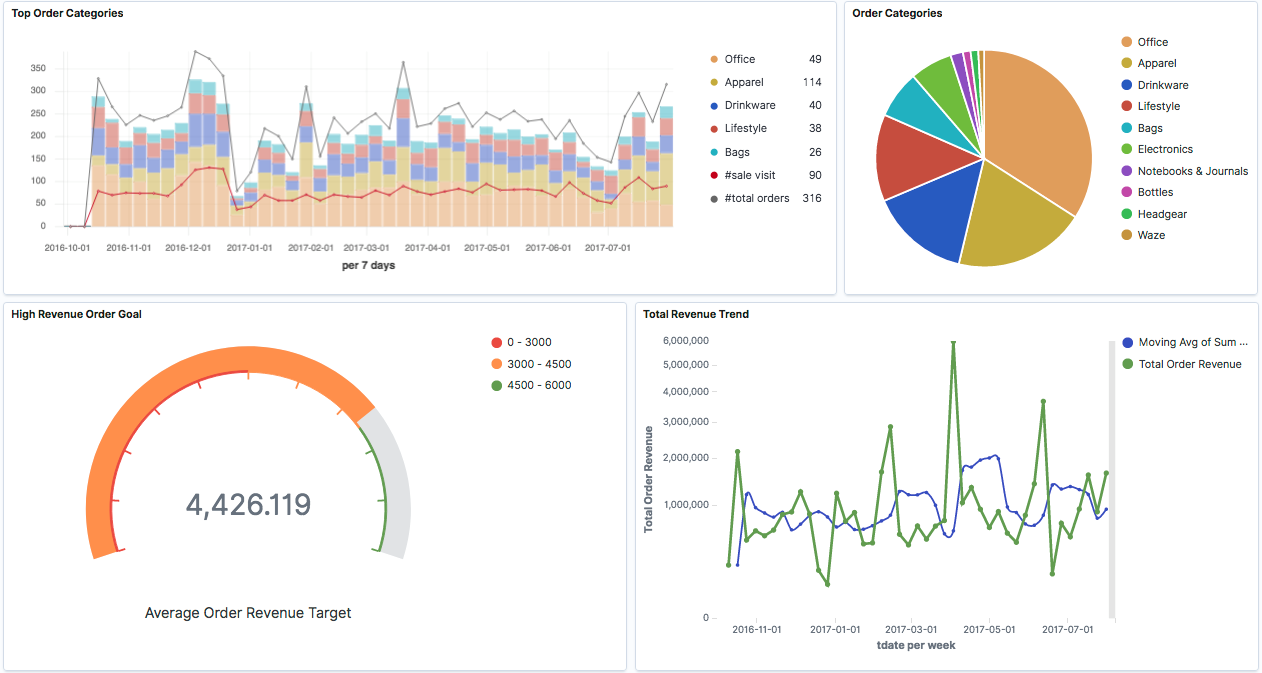
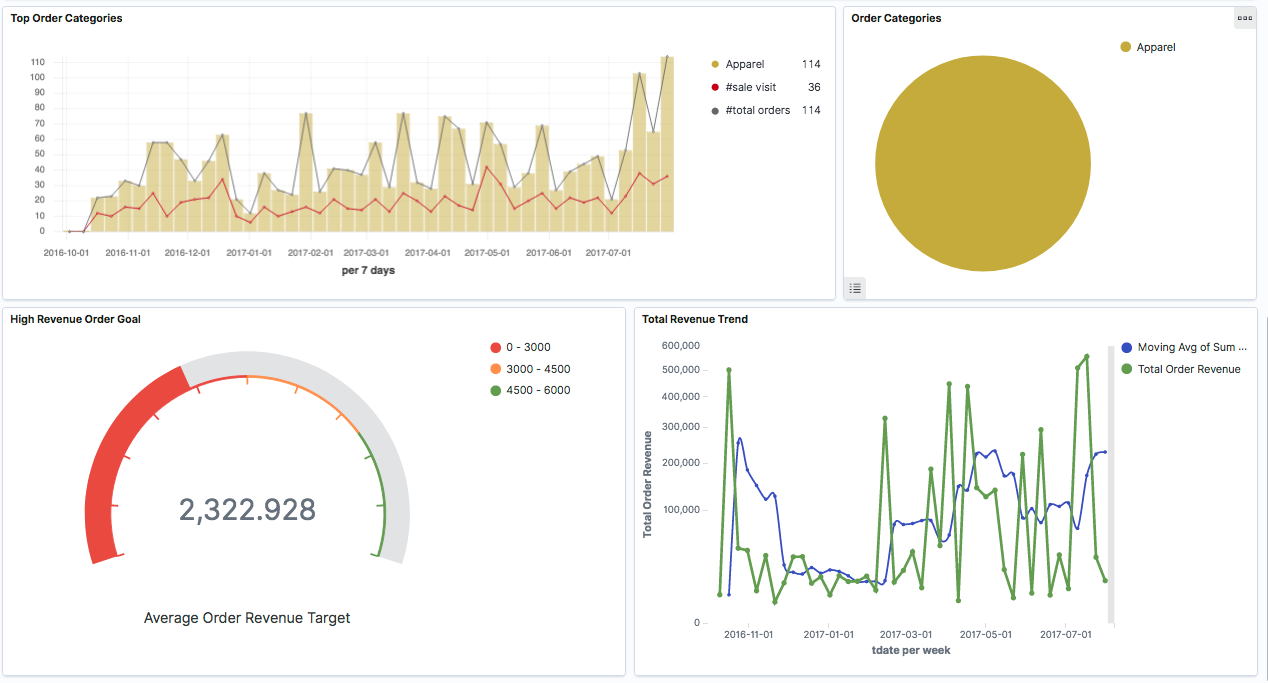
Sobald man die relevanten Daten erfasst und in einer grundlegenden Analytics-Infrastruktur bereitgestellt hat, ist man technisch seinem Ziel bereits ein großes Stück nähergekommen – dem Ziel, den vollen Nutzen der Daten abzuschöpfen. Wird die Realität mit Hilfe von Daten abgebildet, so können sich schon erste Lerneffekte für das Unternehmen einstellen und der datengetriebene Ansatz insgesamt leichter etabliert werden. Damit ist man bestens vorbereitet für den nächsten Schritt.
Schritt 3: Marketing Aktivitäten effektiv steuern – dank Advanced-Analytics und Künstlicher Intelligenz
Wie kommt man von der datengestützten Betrachtung der Realität zu konkreten Handlungen, die unsere Marketing-Aktivitäten erfolgreicher machen? Dafür brauchen wir Methoden, die uns sagen, was wahrscheinlich passieren wird, wenn wir die eine oder andere Maßnahme ergreifen. Oder was wir am besten tun, wenn eine bestimmte Situation eintritt. Oder Möglichkeiten, um Hypothesen zu verifizieren und unerkannte Zusammenhänge zu Tage zu fördern.
Genau das leisten Maschinelles Lernen und der Künstliche Intelligenz. Verschiedene Methoden versetzen uns in der Lage, anhand unserer Daten Voraussagen zu machen und, wenn wir das wollen, sogar Prozesse zu optimieren und automatisch steuern zu lassen. Die Anwendungen dafür im Marketing sind vielfältig. Es gibt eine Reihe von etablierten Use-Cases für Advanced-Analytics im Marketing, von denen wir einen Teil bereits in früheren Beiträgen behandelt haben:
- Abwanderung vermeiden und Kundentreue erhöhen: Eine Reihe von Verfahren lassen uns Merkmale erkennen, um die treuen Kunden von den Kunden zu unterscheiden, die kurz davor sind, uns zu verlassen. Dies ermöglicht es, sowohl kurzfristige Maßnahmen abzuleiten, um einzelne Kunden stärker zu binden, als auch grundlegende Faktoren zu erkennen, die die Abwanderung generell bedingen. Die grundlegende Technik haben wir in Teil 3 der Reihe vorgestellt.
- Recommendation-Engines wie wir sie im vierten Beitrag vorgestellt haben, konfrontieren den Kunden mit Produkten, die er sonst wahrscheinlich nicht gefunden hätte, und eröffnen Cross- und Up-Sellingmöglichkeit, die das Engagement steigern können. Grundlegend leiten sog. Kollaborative Systeme Empfehlungen aus dem Gesamtverhalten aller Kunden ab, wohingegen Content-basierte Empfehlungssysteme sich auf die Ähnlichkeit zwischen Produkten und Inhalten und die Historie des einzelnen Kunden stützen.
- Hyper-Personalisierung bezeichnet allgemein die Anpassung des Einkaufserlebnisses an die Bedürfnisse des einzelnen Kunden. Dies kann in Form von kundenspezifischen Empfehlungen, von speziell zugeschnittenen Funktionen auf der Webseite oder von proaktiven Aktionen oder Support erfolgen, die auf die spezifische Situation des Kunden eingehen. Prinzipiell möglich ist proaktiv
o den Kunden zu beraten, bspw. hinsichtlich Produkte, die bei ihm in der engen Auswahl stehen.
o ihn zu informieren, z.B. über bestimmte Leistungen, die er scheinbar nicht kennt.
o ihn mit seiner Kaufentscheidung zufriedener zu machen, etwa durch einen Hinweis auf weitere Verwendungsmöglichkeiten des gekauften Produkts.
o Abläufe für den Kunden zu vereinfachen, z.B. durch eine automatische Erinnerung oder automatische Vorauswahl für den regelmäßigen Einkauf.
o Ihn zu belohnen bspw. durch exklusive Vorteile oder Angebote.
So umfassend und in diesem Umfang auf den einzelnen Kunden einzugehen, ist normalerweise manuell nicht zu leisten. Voraussetzung dafür ist ein einheitliches Bild der Kundeninteressen, das durch das Erfassen der Kundeninteraktion über die verschiedenen Berührungspunkte wie Online-Shop, CRM, usw. hinweg zu gewinnen ist.
- Personalisierte Werbung: Automatisierte Schaltungen von Anzeigen stellen bei vielen Unternehmen den Kern der Marketing-Aktivitäten dar. Advanced-Analytics hilft durch die gleichzeitige Betrachtung vielfältiger Informationen wie Kundensegment, Kundenvorlieben und Einstellung gegenüber Anzeigen, die Werbung zielgenau zu platzieren und Ausgaben möglichst effektiv einzusetzen. Gleichzeitig muss darauf geachtet werden, Kunden nicht durch zu persönlichen Einblendungen abzuschrecken.
- Mit Marketing Attribution wird der Effekt einzelner Kampagnen auf das Kaufverhalten der Kunden bewertet. Durch die wachsende Anzahl an Kanälen wird diese Bewertung besonders erschwert. Mit Hilfe von Advanced-Analytics kann bemessen werden, welche Kampagnen wirklich erfolgreich sind und sich letzten Endes lohnen.
- Bei der Kundensegmentierung ermöglicht Maschinelles Lernen, einen 360°-Blick auf Kundendaten in Echtzeit zu werfen und Kundengruppen auszumachen, die Interessen, Merkmale oder Bedürfnisse teilen. Wie wir in Teil 5 gesehen haben, können dabei mehrere Datenquellen berücksichtigt werden, um ein feingranulares Bild unserer Kunden zu gewinnen. Zu wissen, wer unsere Kunden sind, ermöglicht eine gezielte Ansprache und ist die Grundlage für eine erfolgreiche Marketing-Strategie.
- Beim dynamischen Pricing muss das richtige Gleichgewicht zwischen Zahlbereitschaft der Kunden und Marge in Abhängigkeit der Situation gefunden werden. Maschinelles Lernen ermöglicht das Aufstellen von dynamischen Modellen, die eine Vielzahl von Faktoren wie z.B. saisonale Trends berücksichtigen.
- Real-Time-Forecasting: Die Nachfrage präzise vorauszusagen, ermöglicht die genaue Planung von Personal, Umsatz und Warenwirtschaft. Durch Advanced-Analytics ist es möglich geworden, mehr Datenquellen heranzuziehen und auf veränderte Bedingungen in Echtzeit zu reagieren, sodass eine höhere Planungssicherheit bestehen kann und strategische Entscheidungen fundiert getroffen werden können.
Für die Realisierung dieser Anwendungsfälle muss unsere Analytics-Architektur dank der Vorbereitung durch die vorangegangen zwei Schritte nicht wesentlich geändert werden: Mit den verschiedenen ML-Bibliotheken von Apache-Spark sind bereits die fortgeschrittenen Analytics-Fähigkeiten vorhanden. Auch Elastiscsearch stellt einige Methoden des Maschinellen Lernen bereit, um bspw. Anomalien zu erkennen oder überwachtes Lernen zu ermöglichen. Wie beim zweiten Schritt empfiehlt es sich hier strategisch, die Entwicklung von Advanced-Analytics anhand einzelner, klar umrissener und einschätzbare Business-Cases zu steuern.
Ausblick
Mit Advanced-Analytics erhalten die Verantwortlichen im Marketing einen starken Hebel, um den Durchblick zu behalten, die richtigen Maßnahmen herauszuarbeiten und effektiv einzusetzen. Die Grundlage dafür sind die Daten. Der Weg zur Umsetzung bedeutet auf technischer Ebene einige Veränderungen. Auf der Organisationsebene sind ein entsprechender Know-How-Aufbau und Änderungen in der Arbeitsweise nötig. Dieser Weg lässt sich jedoch mit dem richtigen Fokus in kleinere, übersichtliche Schritte zerlegen und so auf jeden Fall bewältigen. Damit legen sie den Grundstein für Ihren langfristigen Erfolg.
Elasticsearch and Kibana are trademarks of Elasticsearch BV, registered in the U.S. and in other countries.
Elastic and Beats are trademarks of Elasticsearch BV.


