

Anfangen, die Kunden kennen zu lernen
Die Customer Journey ist ein in Marketingkreisen häufig genannter Begriff, der den Weg eines Kunden bis zum Kaufabschluss beschreibt.

Nicht nur Global Player wie Amazon analysieren diese, um ihre Kunden besser zu verstehen und dieses Wissen gewinnbringend einsetzen zu können. Es handelt sich hierbei um ein zentrales Thema, sodass nicht nur die ganz Großen davon profitieren können.
Viele Unternehmen wandeln sich derzeit zu datengetriebenen Unternehmen. Ein Grund dafür ist sicherlich, dass das in der heutigen Zeit aus technologischer Sicht keine derart hohe Hürde mehr darstellt wie noch vor einigen Jahren. Hingegen hat sich gerade im E-Commerce-Bereich die Konkurrenzsituation stark verändert, sodass bisher etablierte Mittel einfach nicht mehr ausreichen, um am Markt bestehen zu können. Den Preis zu senken, weil ein Konkurrent günstiger ist als man selbst, kann nicht mehr allein als passende Lösung für Probleme angesehen werden, möchte man nicht in einer endlosen Spirale münden, die einen immer wieder zu Preissenkungen zwingt, bis nichts mehr an Marge übrig bleibt oder man sogar noch etwas drauflegen muss.
Sich immer innovativere und kreativere Marketing-Maßnahmen einfallen lassen, ist auch nicht beliebig lange möglich. Besonders deren Wirksamkeit zu messen, zeigt sich oftmals als Herausforderung, wie bereits der Marketing-Pionier John Wanamaker (1838-1922) festgestellt hat: „Half the money I spend on advertising is wasted; the trouble is I don’t know which half.“ (https://en.wikipedia.org/wiki/John_Wanamaker)
Und hier kommen Customer Journey Analytics ins Spiel, die eine 360°-Sicht des Kunden ermöglichen, alle Kanäle, auf denen der Kunde unterwegs ist, miteinander verbinden und so wichtige Rückschlüsse genauso wie gezielte Entscheidungen erlauben.
Die Customer Journey ist vereinfacht gesagt der Weg, den ein Kunde genommen hat, bis er sich zum Kauf eines Produkts bzw. zur Bestellung einer Leistung entschlossen hat. Üblicherweise findet man die Begrifflichkeit der Customer Journey im Marketing wieder, da innerhalb dieser alle Berührpunkte des Kunden mit einem Produkt, einer Marke oder auch einer Marketingmaßnahme wie einer Bannerplatzierung oder einer bei Google geschalteten Adwords-Kampagne umfassen. Anstelle von Berührpunkten ist auch oft von sogenannten Touchpoints die Rede, mit denen ein Kunde interagieren kann. Da nicht jeder dieser Touchpoints bzw. die Interaktionen mit diesen elektronisch oder digital erfassbar ist oder einem konkreten Kunden zuzuordnen ist, ist die Analyse der Customer Journey kein triviales Unterfangen. Stellen Sie sich diesbezüglich das Betreten eines Geschäfts vor. Zu erfassen, dass jemand den Laden betreten hat, ist durch Sensoren wie einer Lichtschranke erfassbar, ebenso wenn jemand den Laden wieder erfasst. Wer genau den Laden betritt, ob es sich um einen wiederkehrenden Kunden handelt, wie viel dieser gekauft hat, über was er sich informiert hat, welche Fragen er an den Verkäufer gestellt hat sind an dieser Stelle aber Fragen, die nicht durch einfache Sensoren erfassbar sind.

Teilweise sind derartige Daten nicht erfassbar oder einer Person zuzuordnen. Bei der Betrachtung eines Online-Shops gestaltet sich zumindest die Erfassung der Daten einfacher: Sobald sich ein User einloggt, ist er identifiziert. Ihm können dann alle Aktionen, die er im Laufe seines „Besuches im Online-Laden“ eindeutig zugeordnet werden. Hier zeigt sich schon ein Kernpunkt der Customer Journey und deren Analyse: Es gibt mehrere Touchpoints auf unterschiedlichen Kanälen, mit denen Interkationen stattfinden können.
Handel ist Omni-Channel
Im jetzigen Zeitalter ist mittlerweile nicht mehr vom Multi-Channel Commerce, sondern vom Omni-Channel Commerce die Rede. Online trifft offline, Marketing findet nicht nur in Form von Newslettern und Werbebannern, sondern auf allen verfügbaren Kanälen statt, Kunden hinterlassen bei jeder Interaktion mit einem Online-Shop Spuren, und all diese Informationen können dabei helfen, mehr Potenzial zu erschließen, gezieltere Marketing-Maßnahmen durchzuführen, höhere Newsletter-Öffnungsraten zu schaffen et cetera.
Doch wie schafft man es, alle Kanäle miteinander zu verbinden und alle Daten, die bei einer Customer Journey produziert werden, zu messen und sinnvoll auszuwerten?
Silos auflösen
Ein Problem, das branchenübergreifend allgegenwärtig ist, ist die Tatsache, dass sich die Daten in unterschiedlichen Systemen befinden. So kommt vielleicht eine Anwendung wie Google Analytics zum Einsatz, um die User auf den eigenen Plattformen zu tracken und die Konversionsrate zu messen. Wenn ein Kunde die Ware jedoch wieder zurückschickt, wird das System davon aber kaum etwas mitbekommen, da dies in der Regel nicht online, sondern offline geschieht und in einem anderen System erfasst wird. Ein weiteres Tool wird für das Gestalten von Newslettern verwendet: Die Öffnungsrate lässt sich in der Regel messen, ob sich daraus jedoch ein Kaufabschluss entwickelt, bleibt oftmals verborgen. Natürlich gibt es noch weitere Datenquellen, in denen unterschiedliche Informationen gehalten werden, wie den Produktkatalog, Transaktionen im stationären Handel, Transaktionen auf der Online-Plattform, Warenwirtschaftssysteme und CRM (Customer Relationship Management).
In solchen Fällen spricht man von sogenannten Datensilos, die unabhängig und ohne Zusammenhang nebeneinander existieren und jeder für sich wichtige Informationen enthalten, aber die Daten aus unterschiedlichen Silos lassen sich nicht miteinander verknüpfen. Die Lösung liegt hier auf der Hand: Jedes System hat für sich gesehen seine Berechtigung, die Daten sind jedoch zentral zu sammeln, um sie auch zentral und gesamtheitlich analysieren zu können.
Art und Beschaffenheit der Daten
Doch welche Daten sind relevant? Kurz gesagt: Alle Arten von Daten [–] egal, wie sie beschaffen sind. Von System-Log-Dateien, die aussagen, ob Fehler im System vorliegen, über Clickthrough-Daten von Usern bis hin zu Retouren und Newsletter-Kündigungen. Egal, ob strukturiert (CRM, ERP), unstrukturiert (Kundenrezensionen, Tweets) oder semistrukturiert (Logs): Daten sind da, um ausgewertet zu werden. Und hier trifft man auf eine weitere Herausforderung: Daten liegen nicht nur in unterschiedlichen System, sondern auch in unterschiedlichen Formen vor.

Um den Bogen anhand eines Beispiels zurück zur Customer Journey zu schlagen: Ein Kunde hinterlässt Daten in mehreren Systemen: Über eine Google-Suchanfrage ist er in einem Online-Shop gelandet, dort browst er durch das Angebot, führt Suchen aus, navigiert durch Trefferlisten, sieht sich Produkte an, legt etwas im Warenkorb ab, legt einen weiteren Artikel sowie einen von der Recommender Engine empfohlenen Zubehörartikel in den Warenkorb und schließt den Warenkorb ab, indem er Adresse, Zahlungsart und dergleichen hinterlegt. Der Kunde erhält seine Bestellung nach fünf Tagen und schickt diese am darauf folgenden Tag, ohne einen Grund zu nennen, wieder zurück.
Über Tools wie Google Analytics ließe sich nun hervorragend nachvollziehen, wie der User auf den Online-Shop gekommen ist, wie er sich bewegt hat und dass er letztlich zum Kunden geworden ist. Dass die Bestellung retourniert wurde, bleibt jedoch verborgen, ebenso, dass er über die Recommender Engine ein weiteres Produkt gekauft hat.
Fragestellungen folgender Art lassen sich also nicht beantworten: Wie viele User, die einen Warenkorbwert von 500 Euro oder höher hatten und erst nach fünf Tagen ihre Ware erhalten haben, haben ebenfalls ihre Bestellung wieder zurückgeschickt? Ist diese Zahl vergleichbar mit den Kunden, die ihre Ware innerhalb von zwei Werktagen erhalten haben? Gibt es Kunden, die ihre Bestellung zurückgegeben haben, die aus ähnlichen oder identischen Produkten bestand?
Somit ließe sich nachvollziehen, ob die Lieferzeiten oder vielleicht eher die Produkte selbst Grund für die Retoure waren. An dieser Fragestellung sieht man bereits, dass das Erstellen eines Datenmodells, das solche Fragestellungen erlaubt, nicht trivial ist, nachdem es schwierig ist vorherzusehen, wie mögliche Fragestellungen einmal aussehen werden beziehungsweise welche Daten miteinander zu kombinieren sind, um aufkommende Fragen beantworten zu können. Man benötigt also ein flexibles System.
Um alle Daten der Customer Journey für Abfragen nutzen zu können, wird tendenziell ein großer Datenspeicher benötigt, Skalierung ist also das nächste Stichwort. Es wird ein System benötigt, das mit dieser Datenmenge und zukünftig zur Verarbeitung eintreffender Daten zurechtkommt und zusätzlich noch etwas, das diese Daten auch verarbeiten kann. Hierfür eignen sich Apache Hadoop und dessen Ökosystem hervorragend. Mit dem Big-Data-Framework ist es möglich, große Datenmengen verteilt abzuspeichern sowie zentral (zumindest nach außen hin) zu verarbeiten.
Bezüglich des Erstellens eines Datenmodells muss man sich hier keine Sorgen machen, denn mit Hadoop erhält man die Möglichkeit, ein Schema bei der Abfrage der Daten über diese Daten zu legen. Ein Hadoop-Cluster kann mit der Zeit auch stetig wachsen. Das heißt, klein anzufangen und mit der erfolgreichen Anzahl an Business Use Cases zu wachsen, ist mit der Einführung von Hadoop in Unternehmen nicht nur möglich, sondern in der Praxis auch immer wieder zu beobachten.
Ein Weg, in dieses Thema einzusteigen, ist, sich einen gut definierten und strukturierten Use Case auszusuchen und diesen umzusetzen. Das kann zum Beispiel die Bewegung der User auf der Online-Plattform beziehungsweise dem Online-Shop sein.
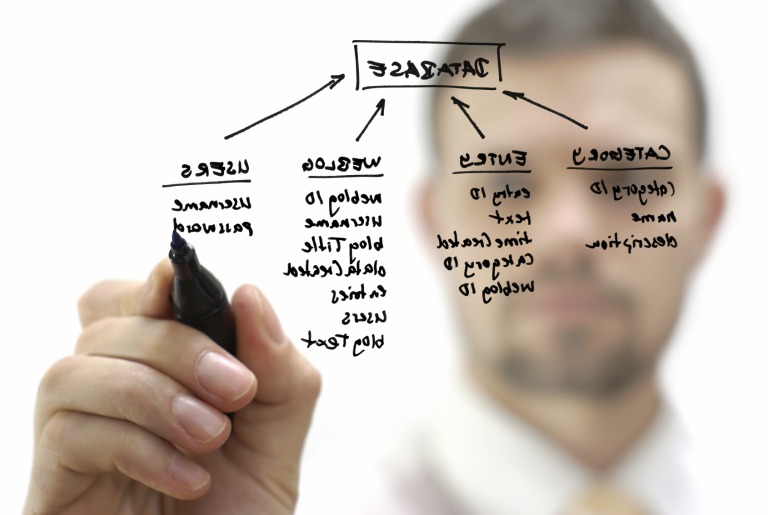
Man definiert gängige User-Aktionen (Suche, Navigation auf Trefferliste, Aufruf Produktdetailseite, Platzierung in Warenkorb, Warenkorbabschluss, Warenkorbabbruch) und schneidet diese mit.
Jede der User-Aktionen wird mit einigen Zusatzinformationen gespeichert, natürlich unter Berücksichtigung des Datenschutzgesetzes: Session, Timestamp, User-ID, Produkt-ID, Filter und so weiter. Solche Datensätze sind klein und handlich; dazu ist nicht unbedingt ein Hadoop-Cluster nötig, selbst wenn die Daten über einen längeren Zeitraum gespeichert werden. Der Autor setzt hierzu gerne Apache Solr ein, um Daten zu speichern, und Banana, um diese Daten interaktiv zu visualisieren.
Das lässt sich auf einen User einschränken, um zu sehen:
- auf welcher Seite des Online-Shops er sich befunden hat, als er seinen Warenkorb abgebrochen hat,
- wie viele Schritte und wie viel Zeit er benötigt hat, um den Warenkorb abzuschließen, und
- wie viele Suchanfragen er abgesetzt hat, bevor er gefunden hat, was er wollte.
Das lässt sich auf den Zeitraum eines bestimmten Tages einschränken, um:
- herauszufinden, wie viele Warenkorbabschlüsse es gegenüber Warenkorbabbrüchen gab,
- herauszufinden, wie viele Aktionen insgesamt im Shop ausgeübt wurden, und
- zu analysieren, was derzeit am häufigsten gesucht wird (Stichwort Trenderkennung) und
- welche Suchanfragen aktuell am häufigsten zu null Treffern führen.
Jegliche Analysen dieser Art lassen sich über einen beliebigen Zeitraum durchführen und untereinander vergleichen. Solche Daten können nicht nur für Standardabfragen und -analysen verwendet werden, die Shop-Verantwortliche in Echtzeit abrufen können, sondern zum Beispiel auch als Input für Recommender Engines dienen, die dann Produktempfehlungen berechnen können. Mit einem solchen kleinen Use Case ist sicherlich noch kein Cluster notwendig, der die Daten hält, da die Menge zu diesem Zeitpunkt noch überschaubar ist [–] selbst wenn pro Monat mehrere Millionen User-Aktionen für Analysen gespeichert werden.
Interessant wird es, wenn diese Daten dann mit anderen verknüpft werden sollen. Dann kann es sein, dass Solr durch die flache Datenstruktur ohne relationale Informationen an seine Grenzen stößt und auch die Datenmenge so steigt, dass ein verteiltes System zur Datenverarbeitung sinnvoll ist. Dadurch wird die Umsetzung des ersten Use Case keinesfalls entwertet, durch das Entstehen neuer Abfragen und neuer Use Cases ist ein Suchserver wie Solr nicht mehr das richtige Tool, um alles realisieren zu können.
Anwendungsfälle aus den Daten der Customer Journey
Aus den Daten der Customer Journey lassen sich nicht nur Erkenntnisse hinsichtlich des User-Verhaltens gewinnen. Es gibt viele weitere Anwendungsfälle, deren Grundlage diese Daten beziehungsweise Teile der Daten sind. Dazu gehören wie erwähnt Produktempfehlungen und Personalisierungsfunktionen in vielen Teilen eines Online-Shops, Reports für Händler, die auf Ihrer Plattform verkaufen, dynamische Preisgestaltung, gezieltere Marketingmaßnahmen, Optimierung von Call-Center-Prozessen, Sentiment Analyse und Verbesserung der Usability. Der Einstieg in dieses Themengebiet lohnt sich also in jedem Fall.
Fazit

Die Customer Journey zu verfolgen und auszuwerten ist keine triviale Herausforderung, was nicht nur allein daran liegt, dass Kunden auf vielen Kanälen mit Anbietern interagieren beziehungsweise Berührungspunkte mit diesen haben: Werbung auf unterschiedlichen Kanälen (Print, Online, soziale Netze), stationäre Point of Sale, Online-Shop et cetera. Doch jede einzelne Interaktion hinterlässt Spuren, und diese gilt es auszuwerten und zu analysieren. Während einfache Use Cases mit einfachen und bewährten Tools zu bewältigen sind, erschließt sich das volle Potenzial erst, wenn sich alle Daten miteinander verknüpfen und kombinieren lassen.
Und dafür ist Hadoop eine geeignete Grundlage, was in mehreren Tatsachen begründet liegt: Die Beschaffenheit und Menge der Daten spielt eine untergeordnete Menge, da quasi beliebige Skalierbarkeit gewährleistet ist und ein Schema erst zur Anfragezeit auf die Daten gelegt werden kann. Es ist keine hochperformante Hardware notwendig, um anspruchsvolle Anwendungen und Analysen auf den Daten zu betreiben. Das reichhaltige Ökosystem erlaubt die Umsetzung jeglicher Use Cases – im Open Source Umfeld gar lizenzkostenfrei.
In einem weiteren Artikel wird anhand eines Fallbeispiels gezeigt, wie Tools aus dem Hadoop-Umfeld bei einer Umsetzung helfen können.


