

Wie bereits in vorangegangenen Blogbeiträgen vorgestellt, bietet Solr 6 einige neue Features. Außer der neuen SQL-Suchsyntax, dem neuen Scoring-Algorithmus und der Möglichkeit zur Graphentraversierung wurde auch die Streaming API um einige Befehle erweitert. Hinzugekommen sind unter anderem verteilte Joins und ein Ausdruck update zum Aktualisieren einer Collection in der SolrCloud.
Funktionalität und Vorteile
Über
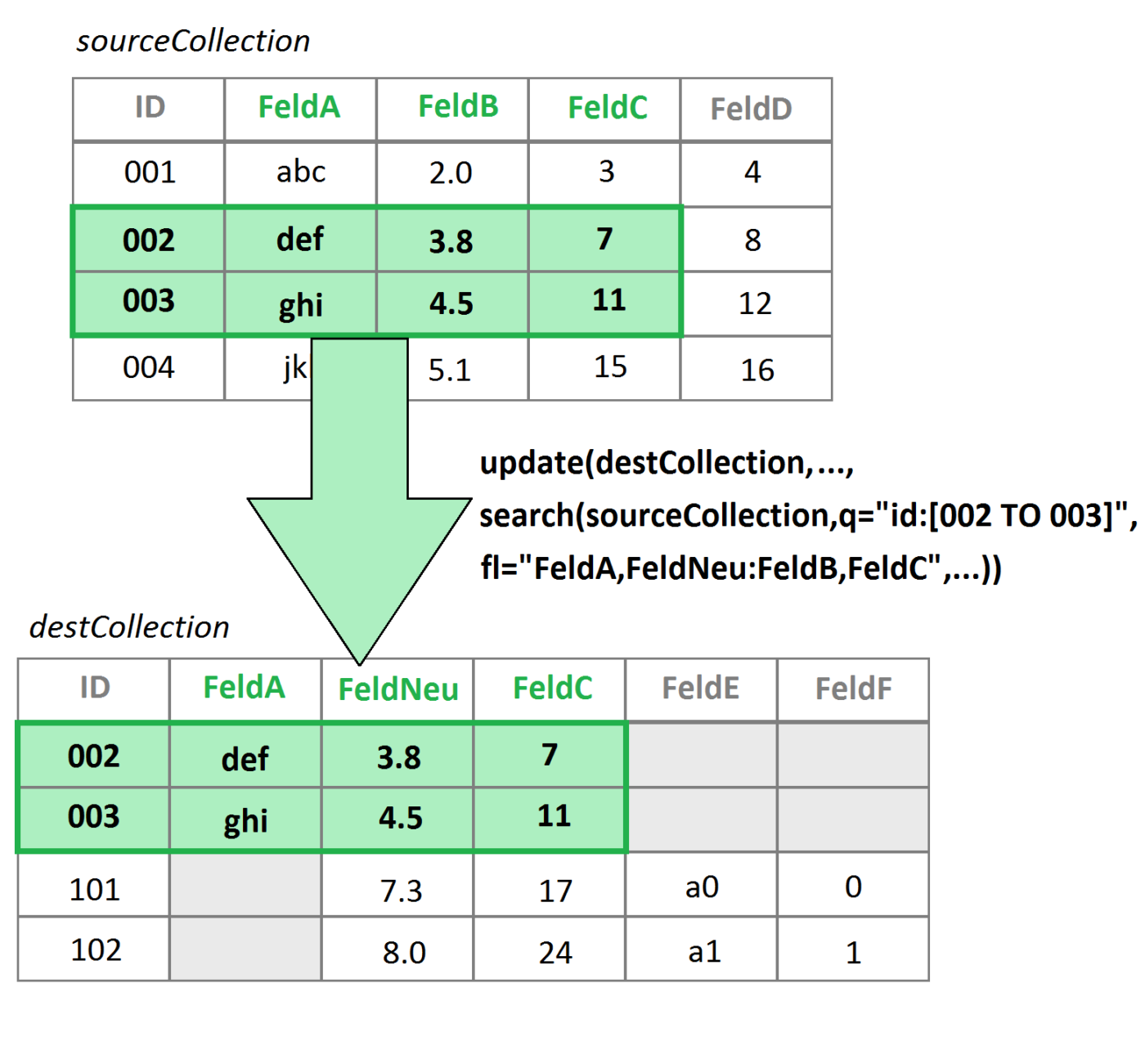
https://host:port/solr/stream?update(destCollection, batchSize=500, search(sourceCollection, q=*:*,fl=”feld1,feld2”, sort=“feld1 asc“))
können Dokumente von der Collection sourceCollection in eine andere Collection destCollection verschoben werden.
Diese Art der Dokumenten-Verschiebung bietet im Wesentlichen die folgenden Vorteile:
- Dokumentenmenge kann über eine Query eingeschränkt werden. Der Nutzer kann damit präzise bestimmen, welche Dokumente er verlagern möchte.
- Es werden nur diejenigen Felder des Dokuments übertragen, welche unter „fl“ aufgelistet sind. Es ergibt sich daraus folglich eine gute Möglichkeit, gewisse Felder zu ignorieren.
- Die übertragenen Felder müssen nicht in der Ziel-Collection vorhanden sein. Ihre Schemata werden automatisch mit dem Update-Kommando übertragen.
- Feldinhalte aus der sourceCollection können in der destCollection auch in Felder anderen Namens übertragen werden. Eine Angabe in der Form fl=“destFeld:sourceFeld“ würde beispielsweise den Inhalt von sourceFeld in ein Feld namens destFeld in der destCollection speichern.
Use Cases
Die Verwendung des update-Streams kann für mehrere Anwendungsfälle interessant sein. Im Folgenden sollen ein paar beispielhafte Use Cases erläutert werden:
- Die Einschränkung der zu übertragenden Dokumente über eine Suchanfrage ermöglicht das Verkleinern einer Collection anhand der angegebenen Suchkriterien.
Beispiel: In einem Online-Shop sind sowohl Bücher als auch DVDs käuflich zu erwerben. Die Daten beider Kategorien sind in derselben Collection gespeichert. Nun sollen die Daten zur besseren Sortierung auf zwei Collections aufgeteilt werden. Durch zwei Updates in der Form update(bookCollection, …, search(oldCollection,q=“Kategorie:Buch“,…)) bzw. update(dvdCollection,…,search(oldCollection,q=“Kategorie:dvd“,…)) ließen sich die Inhalte auf zwei neue Collections aufteilen.
- Die Möglichkeit, Felder bei der Übertragung der Dokumente umzubenennen, kann genutzt werden, um gleichartige Daten aus unterschiedlich benannten Feldern zu kombinieren.
Beispiel: In einem geschäftsinternen Verwaltungssystem sollen Mitarbeiterdaten von einer Collection in eine andere überführt werden. In der Bezugs-Collection ist die Adresse in dem Feld „Adresse“ gespeichert, in der Ziel-Collection in einem Feld namens „Anschrift“. Um die Konsistenz der Daten zu sichern kann das update-Kommando für das Übertragen der Mitarbeiterdaten mit update(neueCollection,…,search(alteCollection,…,fl=“Anschrift:Adresse,…“,…)) verwendet werden
- Eine Einschränkung der übertragenen Felder kann genutzt werden, um Details in den Daten auszublenden
Beispiel: Zu Analysezwecken sollen Kundendaten von einem Analytiker demographisch ausgewertet werden. Hierzu benötigt er lediglich Angaben zu Alter, Geschlecht und Wohnort des jeweiligen Kunden. Weder Käufe des Kunden noch seine Bankdaten sollen für den Analytiker zugänglich sein. Die Übertragung der notwendigen Dokumente kann also über das Kopieren der gesamten Ursprungs-Collection mit eingeschränkten Feldern realisiert werden: update(neueCollection,…,search(ursprungsCollection,q=“*:*“,fl=“Alter,Geschlecht,Wohnort“,…)).
Fazit
Das update-Kommando kann für einige Use Cases ein sinnvolles Werkzeug sein. Die erweiterte Streaming-API bietet allerdings noch viele weitere Funktionen, welche unter https://cwiki.apache.org/confluence/display/solr/Streaming+Expressions im Solr Reference Guide nachgeschlagen werden können.


