

Teil 5 der BLOGSERIE:

„Data-Driven Marketing: Wie die kundenzentrierte Ansprache in Zukunft gelingt.“
Erscheinungsintervall: alle 6 Wochen
Lesedauer: 7 Min.
Lesen Sie hier die anderen Beiträge dieser Blogserie:
- Teil 1 „Herausforderung Customer Centricity: Wie etabliert ist Datenanalyse im E-Commerce?“
- Teil 2 „Mit Open Source Tools individuelle Reports erstellen“
- Teil 3 „Langfristige Kundenbindung mit Hilfe von „Advanced Analytics“
- Teil 4 „Wann bleiben die Kunden vor der Tür stehen? – Predictive Analytics mit Maschinellem Lernen“
- Teil 6 „Auf Interessen der Kunden reagieren: Intelligente Recommendations“
- Teil 7 „Data-Driven Marketing: Wie kundenzentrierte Ansprache in Zukunft gelingt in 3 Schritten“
Bisher haben wir in dieser Blog-Serie mit Hilfe von Analytics vorranging das Verhalten der Kunden näher betrachtet: Abwanderungsraten, Verhalten nach dem Erstkauf, Bounce-Rates. Aber wie sieht der typische Kunde aus? Was haben Kunden gemeinsam und welche Kundengruppen lassen sich erkennen? Je besser wir unsere Kunden kennen, desto genauer können wir auf ihre Bedürfnisse eingehen und sie entsprechend gezielt ansprechen.
Wie Maschinelles Lernen und Künstliche Intelligenz dabei helfen können, typische Kundengruppen zu erkennen, zeigen wir anhand unseres Google Analytics Beispiel-Datensatzes zum Google Merchandise Store.
Kunden beschreiben, um Fragen zu beantworten
Um Kunden sinnvoll nach Ähnlichkeit zu gruppieren, müssen wir sie zunächst beschreiben. Hierfür bieten uns in der Regel die vorhandenen Daten verschiedene Möglichkeiten.
Im Fall der Google Analytics Daten stehen uns verschiedene Informationen über die Kunden zur Verfügung, etwa zum geographischen Ursprung, zum eingesetzten System, zum Herkunftskanal und zum Verlauf des Besuchs. Viele dieser Informationen haben wir in vorherigen Teilen der Blog-Serie bereits genutzt. Diesmal interessiert uns, welche Arten von Produkten ein Kunde bevorzugt kauft und wie viel Geld er im Schnitt dafür ausgibt. Dies wird uns später ermöglichen, Kundensegmente nach Produktinteressen und Umsatz auszumachen, und so beispielsweise besonders umsatzstarke Kunden mit den richtigen Angeboten näher an uns zu binden.
In unserer Open Source Analytics Architektur setzen wir Apache Spark ein, um die Google Analytics Daten zu transformieren. Damit erhalten wir eine große Tabelle, in der für jeden Kunden die relevanten Merkmale wie Ausgaben je Produktart, mittlere Warenkorbgröße, usw. aufgeführt sind.
Das Schema der Daten haben wir bei unserer ersten Datenexploration kennengelernt. Um daraus die gewünschte Tabelle mit Spark zu berechnen, werden die Daten als DataFrame eingelesen. Dann stehen uns SQL-ähnliche Methoden zur Verfügung, um folgende Schritte durchzuführen:
- Extraktion von Produkttransaktionen aus den einzelnen Besuchen: Auffächern der Hits in den Besuchen mit der explode-Funktion, Filterung der Transaktionen
- Bildung von Produktkategorien und Aufsummierung der Ausgaben pro Kunde nach Kategorien; Pivotierung des DataFrame nach den Kategorien
- Berechnung der Kunden-Eckdaten zur Warenkorbgröße und Zeit bis zum Wiederkauf
- Zusammenführung mittels join der Ergebnisse aus Schritt 2 und 3 zur finalen Kunden-Matrix
Die Details zu den einzelnen Schritten können dem beigefügten Jupyter-Notebook mit dem vollständigen Programm entnommen werden.
Am Schluss der Berechnungen liegt eine Tabelle vor, die etwa so aussieht:
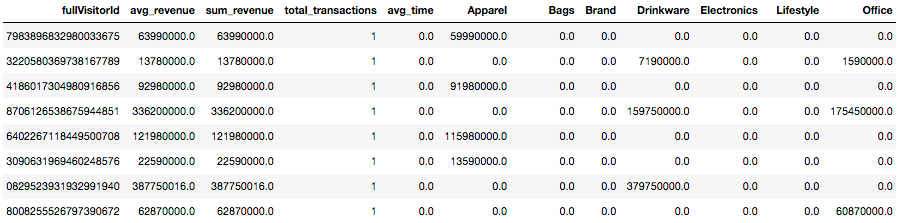
Darin wird jeder Kunde mit einer fullVisitorId identifiziert. Die Spalten mit dem durchschnittlichen Warenkorbwert (avg_revenue), dem Wert aller Einkäufe (sum_revenue), der durchschnittlichen Produktanzahl pro Kauf (total_transactions) sowie der mittleren Zeit bis zum Folgekauf in Tagen (avg_time) wurde in Schritt 3 berechnet. Der durchschnittliche Umsatz je Produktkategorie Apparel, Bags, Brand, Drinkware, Electronics, Lifestyle und Office stammen aus Schritt 2.
Gemeinsamkeiten finden: Clustering Algorithmen
Das Finden der Gemeinsamkeiten zwischen den Kunden überlassen wir einem geeigneten Algorithmus. Clustering-Algorithmen gruppieren Objekte nach einer bestimmten, vordefinierten Art der Ähnlichkeit. Je nach gewähltem Verfahren haben die daraus resultierenden Gruppen, die sogenannten Cluster, unterschiedliche Eigenschaften: Sie überlappen sich oder sind getrennt, sind hierarchisch oder flach aufgebaut, usw. Clustering-Verfahren sind sehr verbreitet und werden zum Beispiel in der Bioinformatik verwendet, um Abstammungsbäume zu berechnen, oder bei Deep-Learning und Computer-Vision, um Merkmale zu generieren.
Ein Klassiker unter den Clusterverfahren ist der K-Means-Algorithmus, von dem es wiederum verschiedene Abwandlungen gibt. Der Name kommt zum einen daher, dass die Anzahl der Ergebnis-Cluster mit dem Parameter K vorgegeben werden muss. Zum anderen versucht der Algorithmus, zu jedem Cluster einen Schwerpunkt zu finden, sodass der mittlere Abstand („Means“) der Datenobjekte im Cluster zum Schwerpunkt minimal ist. Die zu gruppierenden Objekte werden in einem mehrdimensionalen Raum dargestellt; K-Means ordnet dann effektiv jedes Objekt dem nächstgelegenen (nach Euklidischer Distanz) Clusterschwerpunkt zu. Ein Beispiel ist in Abbildung 2 dargestellt.
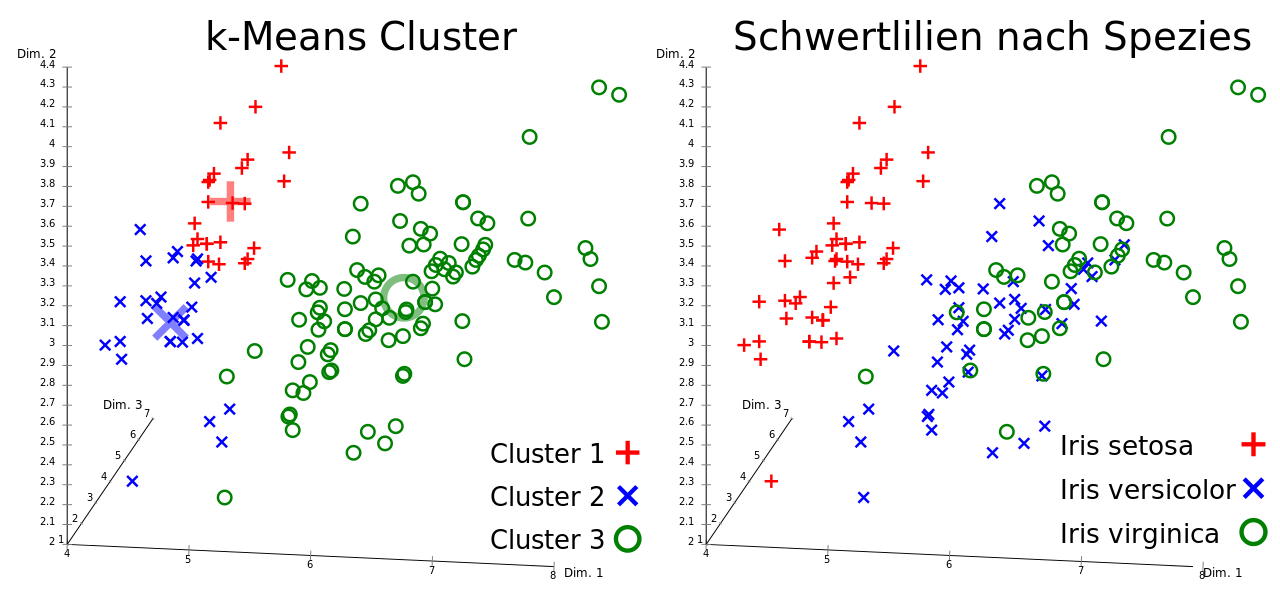
In unserem Fall bilden die Spalten in der Kundenmatrix die Dimensionen des mehrdimensionalen Raums.
Automatische Gewinnung von Kundensegmenten mit Spark ML
Um K-Means auf unsere Beispieldaten anzuwenden, verwenden wir wie bisher die Spark ML Bibliothek. Die Vorgehensweise ist dieselbe, die wir in Teil 4 der Blog-Serie vorgestellt haben. Nachdem wir die Rohdaten in einem Spark DataFrame eingelesen und zur finalen Kunden-Matrix transformiert haben, bauen wir eine Pipeline auf, in der zunächst die Merkmale extrahiert und als Eingabe für den Algorithmus vorbereitet werden. Anschließend wird das eigentliche K-Means Verfahren darauf „trainiert“. Im Gegensatz zum Klassifikationsansatz in Teil 4, verwenden wir hier einen unüberwachten ML-Algorithmus: K-Means kann keine vorhandenen Testdaten zu Rate ziehen, um die richtige Clusterzugehörigkeit zu lernen – welche Cluster es gibt, ist ja unbekannt. Daher fällt der Evaluationsschritt anhand eines Testdatensatzes hier weg.
Da es sich bei der vorberechneten Kunden-Matrix um numerische Werte handelt, ist die Spark Pipeline diesmal einfach aufgebaut: die einzelnen Matrix Reihen werden als Vektoren umgewandelt und die Werte skaliert, sodass die Wertebereiche in den unterschiedlichen Spalten vergleichbar werden (Abbildung 3).
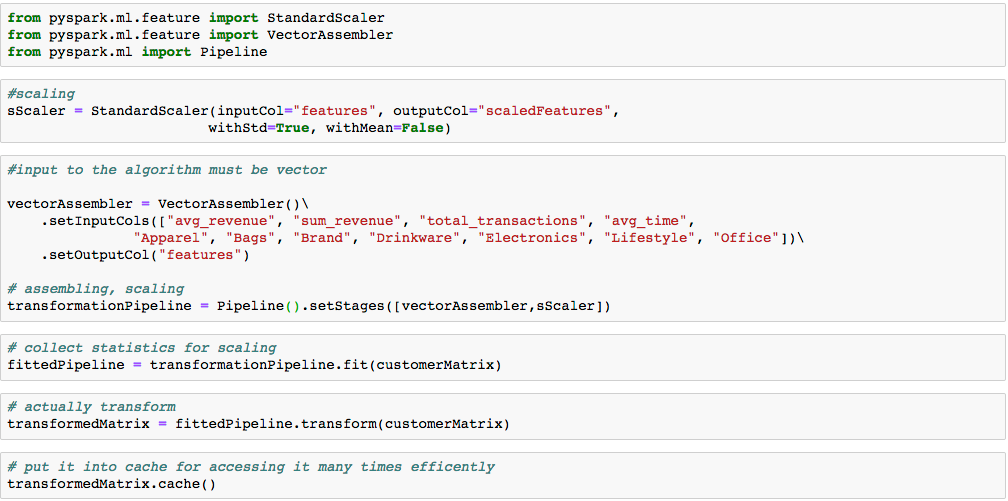

Aber woher sollen wir wissen, wie viele Cluster am besten den Datensatz beschreiben? Wir können nicht mit einem Test-Datensatz vergleichen. Der Silhouettenkoeffizient liefert jedoch eine vom Wert von K unabhängige Bewertung eines Clustering-Ergebnis. Hierbei wird nicht nur geprüft, wie weit ein Punkt vom eigenen Clusterschwerpunkt entfernt ist, sondern es gehen auch die Entfernungen von anderen Clusterschwerpunkten in die Bewertung des Clustering mit ein. Der Silhouettenkoeffizient bewegt sich zwischen -1 und 1, je näher der Wert bei 1 liegt, desto besser „strukturiert“ wurde der Datensatz durch die Ergebniscluster.
Um den optimalen Wert für K in unseren Daten zu finden, führen wir mehrere Experimente durch, wobei wir K zwischen 5 und 15 wählen. Das K mit dem besten Silhouettenkoeffizient halten wir dann fest (Abbildung 5).
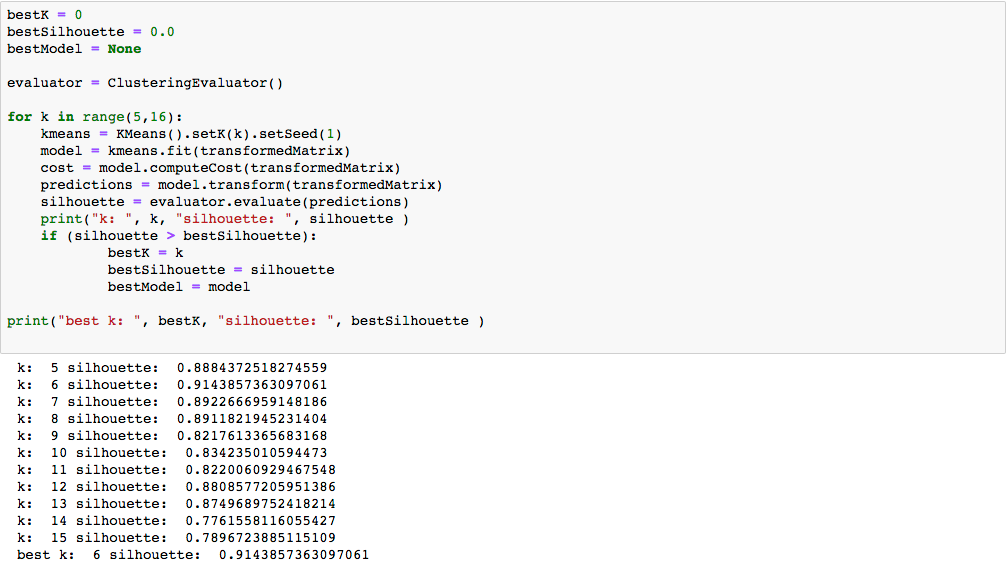
Es stellt sich heraus, dass unser Datensatz optimal durch sechs Kundensegmente beschrieben wird.
Ergebnisse interpretieren und Aktionen definieren
Da eine graphische Darstellung der Cluster-Verteilung in unserem 11-dimensionalen Raum wenig anschaulich wäre, wählen wir eine andere Mittel, um die Ergebnisse zu interpretieren.
Die Größe der verschiedenen Cluster 0 bis 5 ist in Abbildung 6 dargestellt.
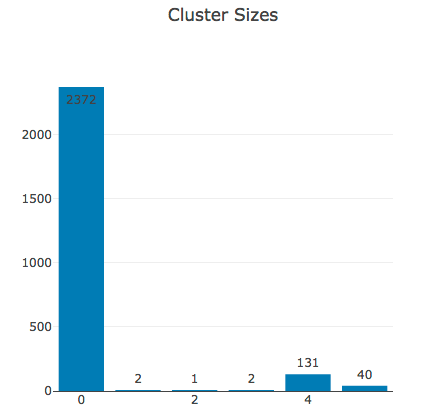
Was die Kunden in einem von diesen Clustern gemeinsam haben, lässt sich gut anhand der typischen Warenkorbgröße, der typischen Ausgaben für die unterschiedlichen Produktkategorien, usw. nachvollziehen. Hierfür haben wir von jeder Dimension den Durchschnitt für alle Kunden innerhalb eines Clusters berechnet und als Strahlendiagrammen in Abbildung 7 dargestellt.
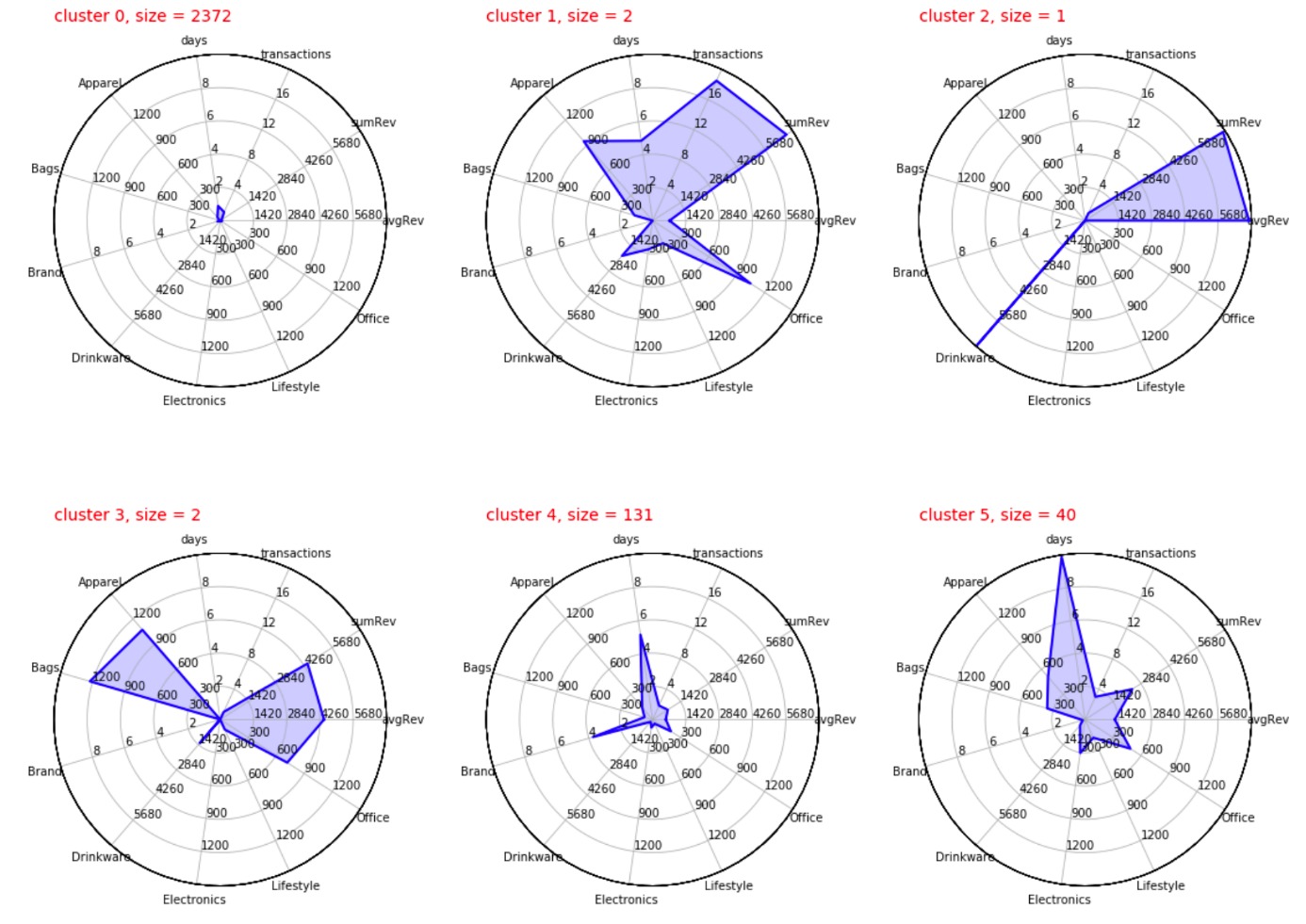
Auffällig sind die Cluster 1, 2 und 3, die mehr oder weniger einzelne, spezielle Kunden darstellen. Diese lassen sich offenbar in keine andere Gruppe einordnen. Diese speziellen Kunden haben im Laufe der Kundenbeziehung insgesamt für einen hohen Umsatz von 4000$ und mehr gesorgt – das jedoch anhand von Produkten aus einer bis maximal drei verschiedenen Produktkategorien.
Die große Mehrheit der Kunden sind die „Gelegenheitskunden“ aus Cluster 0, die einmalig kommen und für wenig Geld einzelne Produkte kaufen.
Cluster 4 fasst circa 130 Kunden zusammen, die mit einer gewissen Frequenz vorranging Office- und Electronics-Produkte kaufen und im Schnitt einen Gesamtumsatz von an die 750 U$ generieren. Sind das vielleicht Google-Mitarbeiter, die für sich oder als Prämie für ihre Kollegen einkaufen?
Ähnlich stellt Cluster 5 wiederkehrende Kunden dar, die neben Office- und Electronics-Produkten ebenfalls Bags kaufen und deren Wert gemessen am Gesamtumsatz etwa doppelt so hoch liegt wie bei Cluster 4. Haben diese Kunden vielleicht einen eigenen Shop?
Diese Erkenntnisse ermöglichen uns, Kunden gezielt anzusprechen. Die „Gelegenheitskunden“ lassen sich vermutlich anders zu einem Zweitkauf bewegen als die ohnehin wiederkehrenden „Großeinkäufer“, die spezielle Interessen haben. Hierbei können wir uns vielleicht auf die Einsichten stützen, die wir bei der Analyse vom Folgekäufen gewonnen haben.
Darüber hinaus könnten wir neue Kunden automatisch einer dieser Gruppen zuteilen und ihnen entsprechend auf der Shop-Seite oder über einen speziellen Newsletter gleich die für sie richtigen Angebote präsentieren. Das bedeutet, dass wir eine Grundlage für automatische „Recommendations“ haben.
Ausblick
Selbst mit einer relativ einfachen Beschreibung unserer Kunden sind wir in der Lage, mit Hilfe von Maschinellem Lernen Gemeinsamkeiten zwischen Kunden auszumachen. Damit sind wir in der Lage, unser Angebot je nach Kundensegment optimal zu präsentieren und gezielte Marketing-Aktivitäten zu definieren.
Mit zusätzlichen Daten, etwa aus dem CRM, dem Bestellsystem, demographischen und anderen Daten lässt sich das Bild weiter schärfen. Je differenzierter unser Blick, desto besser lässt sich auf die Kunden eingehen – bis hin zur personalisierter Ansprache.


