

Im ersten Teil dieses Beitrags haben wir uns damit beschäftigt, wie das Grundgerüst einer Architektur für Cross Analytics aussieht, in der Daten aus unterschiedlichen Datenquellen zusammengebracht und verfügbar gemacht werden, um sie miteinander kombiniert verarbeiten zu können. Damit diese Architektur auf Dauer die Durchführung von Advanced Analytics Projekten unterstützt und dadurch der Wert der eigenen Daten ausgeschöpft werden kann, sind jedoch noch weitere Komponenten nötig, auf die wir in diesem zweiten Teil des Beitrags eingehen.
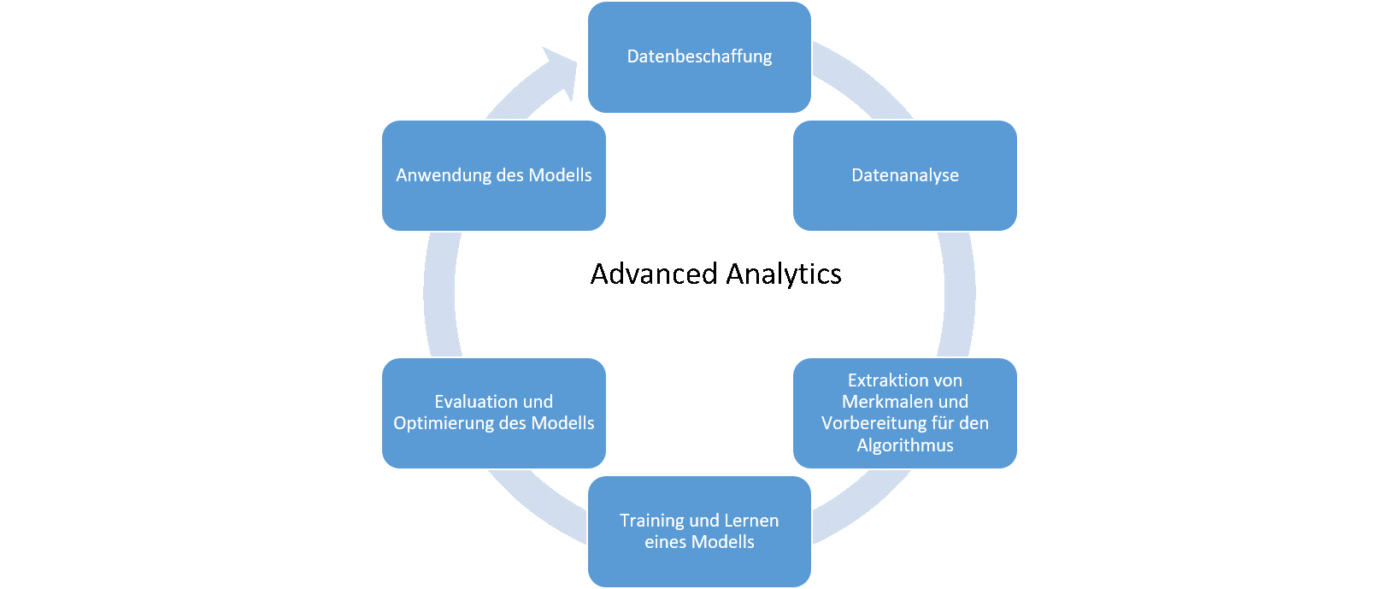
Die Anwendung von Advanced Analytics soll je nach Cross Analytics Strategie dazu dienen, in einem ersten Experiment mit überschaubarem Aufwand zu überprüfen, ob ein konkretes Business-Ziel realisiert werden kann. Das kann bspw. die Personalisierung von Kaufempfehlungen für mehr Umsatz sein oder Vorhersagen und Vermeiden von Retouren. Will man einen solchen Proof of Concept tatsächlich umsetzen, durchläuft man in dem Projekt verschiedene Phasen, die typisch für die Anwendung von Advanced Analytics sind. Als Erstes müssen die Daten beschaffen werden, die die relevanten Zusammenhänge beschreiben können (sh. Abbildung 1).
Den Data Lake überblicken
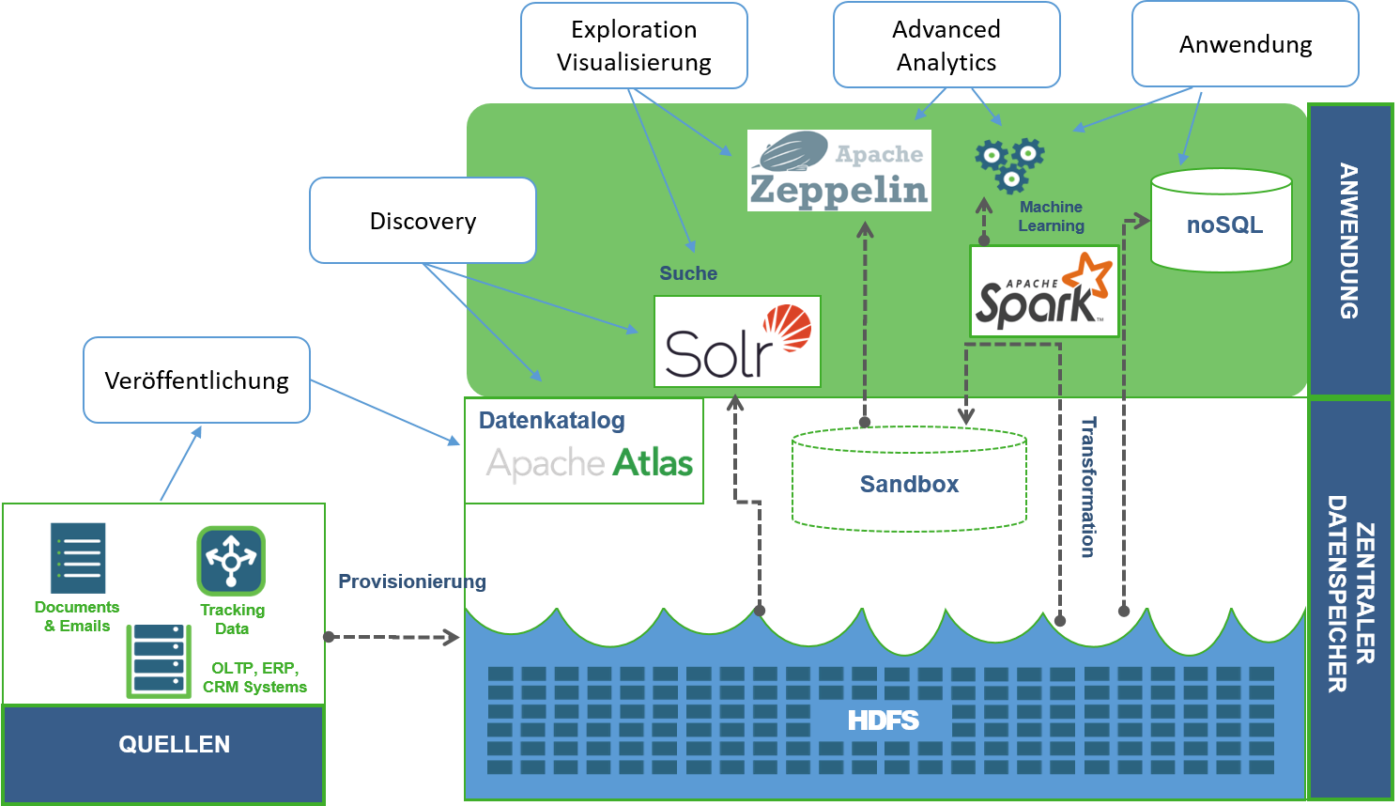
Wichtiger als ein möglichst großer Datenpool ist es, für qualitative Daten zu sorgen und sie so aufzubereiten, dass sie potenziell verschiedenen Zwecken dienen können. Blindes Zusammenführen von Daten endet schnell in einer wertlosen Datenmüllhalde, die keiner mehr überblickt. Neben der zentralen Datenhaltung benötigen wir daher Tools, welche die Daten im Lake erst wiederverwendbar und nachvollziehbar machen.
Hierzu gehört sicherlich ein Datenkatalog, in dem man zunächst die verschiedenen Daten veröffentlicht und mit Hilfe von Metadaten beschreibt und klassifiziert. Eine entsprechende Suchfunktion innerhalb des Datenkatalogs erleichtert dann die Aufgabe, die relevanten Daten für ein Projekt zu finden und zu interpretieren (s. Abbildung 1). Ein Beispiel einer solchen Komponente ist Apache Atlas, das die Funktionalität eines Datenkatalogs für das HDFS zu Verfügung stellt. Ein Datenkatalog spielt auch eine wichtige Rolle, wenn es darum geht, für die Sicherheit der Daten und die Einhaltung von Datenschutzvorgaben zu sorgen, da man darin Richtlinien für den Zugriff und die Länge der Speicherung definieren kann.
Eine weitere Möglichkeit, die Exploration im Data Lake zu unterstützen, besteht darin, die Daten in einer Suchmaschine wie Apache Solr zu indexieren, die eine Vielzahl von Datenformaten und -arten unterstützt. So kann man zentral – zumindest für konkrete Datensätze – recherchieren, in welchen Quellen sie überall vorkommen und welche Bezüge zu anderen Daten bestehen.
Die Daten verstehen
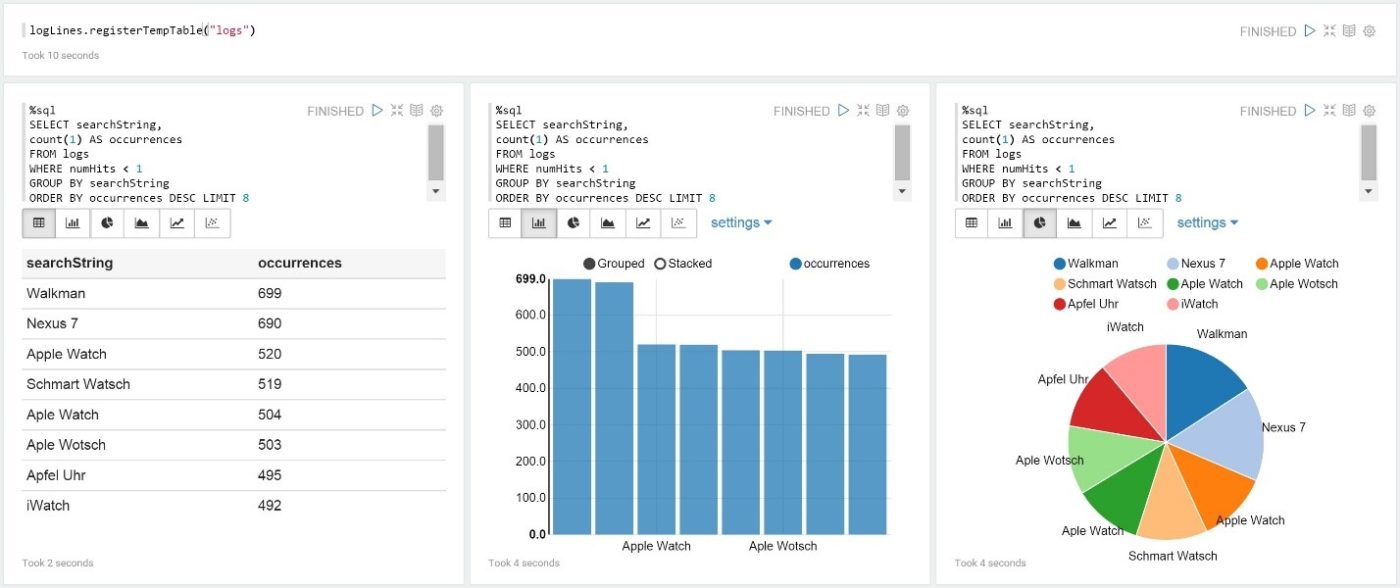
Wurden die rohen Daten beschaffen, die relevant für das Projekt sind, werden erste Erkenntnisse gewonnen, in dem diese erkundet und visualisiert werden. So kann man sicherstellen, dass die Daten die relevanten Zusammenhänge für geplante Anwendung abbilden, und z.B. Korrelationen zwischen Dimensionen der Daten erkennen, die man später bei der Anwendung von Machine Learning Algorithmen berücksichtigen sollte. Eine erste Analyse kann mit Hilfe spezieller Funktionen der Suchmaschine für das Data Lake erfolgen wie etwa die Streaming Expressions von Solr. Ein visueller Eindruck der Daten wird in der Regel jedoch in einer Notebook-Anwendung wie Apache Zeppelin oder Jupyter geboten. Ein Notebook ist im Prinzip eine Webanwendung, mit der Reports, verfasst und geteilt werden können. Die Reports enthalten dabei eingebetteten Programm-Code, Graphiken und Beschreibungen. Das Notebook kann sehr flexibel über übliche Programmiersprachen wie Python, SQL, Scala, usw. auf die Daten zugreifen und ermöglicht somit mit wenig Programmieraufwand auf einer Art interaktiven Spielwiese deren Exploration und Visualisierung. Beide erwähnten Notebook-Anwendungen unterstützen Apache Spark, das wir bereits aus der Anwendungsschicht der Grundarchitektur kennen.
Aus der Exploration der Daten ergibt sich manchmal schon eine erste Analytics-Anwendung in Form von Dashboards, mit denen man bspw. bestimmte Kenngrößen live verfolgen kann. Außerdem ist es üblich, eine spezielle Sicht auf die Daten in Form einer noSQL Datenbank wie Apache Cassandra oder MongoDB zu realisieren, mit der sich die speziellen Anforderungen für den Betrieb einer solchen Anwendung erfüllen lassen.
Advanced Analytics anwenden
Nach dem die Daten untersucht und verstanden wurden, geht es um die Anwendung von Advanced Analytics Methoden, sprich von Maschinellem Lernen (ML). Hier kann man grob drei weitere Phasen unterscheiden (sh. Abbildung 1):
- Vorbereitung der Daten für den ML-Algorithmus: Ausgehend von den ersten Erkenntnissen aus der Exploration der Daten werden diese transformiert, um sinnvolle Merkmale zu erzeugen, anhand denen der Algorithmus lernen soll. Hierbei werden bspw. numerische Daten skaliert, Angaben zu einer Kategorie normalisiert, oder Texte als Menge von Wörtern dargestellt.
- Anwendung des Algorithmus und Trainieren eines Modells: Die transformierten Daten werden in eine Training- und eine Testmenge aufgeteilt, der oder die ausgewählten Algorithmen werden mit Hilfe der Trainingsdaten trainiert. Das Ergebnis ist ein Modell, das das anvisierte Problem für die Art der eingespeisten Daten löst. Bsp.: Klassifikation von Nachrichtentexten nach vorgegebenen Kategorien. Mit Hilfe der Testdaten kann die Qualität des Modells für Datenpunkte, die nicht beim Training verwendet wurden, überprüft werden. Die Qualität des Modells hängt im Wesentlichen von den verwendeten Daten und der Wahl der Parameter für den Algorithmus ab und wird mit Hilfe verschiedener Maße ausgedrückt.
- Die Optimierung des Modells: Hierbei versucht man die optimale Einstellung der Parameter des Algorithmus für die ausgewählten Merkmale zu finden, um die Qualität des Modells zu maximieren.
Die Umsetzung dieser Phasen kann mit Hilfe spezieller Bibliotheken und Frameworks für Maschine Learning wie z.B. SciKit-Learn, H20, Apache Singa unter vielen anderen erfolgen, oder eben auch mit Apache Spark. Neben vielen Features für die robuste Datentransformation, bringt Spark umfangreiche eigene ML-Bibliotheken für die parallele Verarbeitung von Daten mit. Als offenes Framework können andere Bibliotheken wie SciKit-Learn ebenfalls eingebunden werden, sodass es wenige Einschränkungen in der Wahl der Methoden gibt.
Speziell in Spark fällt das Programm in der Regel sehr kompakt aus, so dass es sich gut als Notebook-Report dokumentieren lässt und somit leicht zu teilen und für spätere Anpassungen gut nachvollziehbar bleibt.
Die Früchte ernten … oder neu pflanzen
Wenn der Test mit Maschinellem Lernen zufriedenstellend ist, hat man die ursprüngliche Idee validiert und man kann die gewonnenen Erkenntnisse für das eigene Geschäft nutzen oder das Modell eingebettet in einer Anwendung in Produktion bringen. Dann ist es essentiell, das Verhalten des Modells fortlaufend zu beobachten und zu bewerten, denn nicht zuletzt durch die Verwendung des Modells wird sich das Geschäft und die ursprünglichen Annahmen ändern. Dann muss die ursprüngliche Idee neu geprüft werden und der ganze Prozess geht von vorne los. Und dann ist es gut, wenn unsere Architektur den Advanced Analytics Zyklus unterstützt.
Wenn man die ursprüngliche Idee nicht validieren konnte, erlangt man dadurch ebenfalls neue Erkenntnisse, die üblicherweise zu einer neuen These führen. Und wenn man diese überprüfen möchte, geht der ganze Prozess ebenfalls von vorne los…
Fazit
Mit Hilfe von weiteren Open Source Komponenten wie ein Datenkatalog oder Notebook-Anwendungen lässt sich die Architektur zur Integration verschiedener Datenarten zu einer echten Advanced Analytics Architektur ausweiten, die die spezifischen Schritte bei der Anwendung von Machine Learning Methoden unterstützt. Das ist unbedingt nötig, da dieser Prozess immer wieder durchlaufen werden muss, sobald es darum geht, die eigenen Datenschätze gewinnbringend zu nutzen.
Weiterführende Beiträge
Architektur für Advanced Analytics – Teil I
In diesem ersten Teil des Beitrags sprechen wir darüber, wie man die verschiedenen Komponenten in einer Architektur am besten miteinander kombiniert.
Apache Zeppelin – einfach und schnell zu explorativen Auswertungen
Es gibt heutzutage eine Fülle an Tools und Werkzeugen für Data Science oder Data Analytics. Typischerweise nützen wir Apache NiFi und Apache Solr zur Verarbeitung von kontinuierlichen Daten oder Datenströmen und zum Durchsuchen von riesigen Datenmengen.
Apache Spark – Einheitliche Analyse-Engine für Big Data
Die Grundeigenschaft von Spark kommt uns bereits sehr entgegen, da Spark nicht für einen konkreten Zweck, sondern allgemeingültig für schnelle Datenverarbeitung entwickelt wurde.
Weder müssen Daten in einem bestimmten Format vorliegen, noch müssen diese gezwungenermaßen in einer bestimmten Art und Weise verarbeitet werden. Der Kern von Spark liefert bereits gängige Möglichkeiten Daten einzulesen und diese zu transformieren, auszuwerten und auch zu analysieren.
Sie sehen sich vor einem Berg kryptisch formulierter Log-Daten stehen, aus denen Informationen nur schwer zu extrahieren sind? Sie haben eine Idee zur Optimierung Ihrer Systeme, aber wissen nicht, wie Sie diese verifizieren und präsentieren können? Oder wollen Sie einfach mal herausfinden, welche Features Sie in Ihren Online-Shop einbauen könnten? Dann schnappen Sie sich eine Banana, springen Sie in den Zeppelin, browsen Sie durch Graphen und sehen Sie Garbage aus einer anderen View! Wie das geht, was das bringt und wem das hilft, erfahren Sie hier.


