

Teil 2 der BLOGSERIE:
„Data-Driven Marketing: Wie die kundenzentrierte Ansprache in Zukunft gelingt.“
Erscheinungsintervall: alle 6 Wochen
Lesedauer: 5 Min.
Lesen Sie hier die anderen Beiträge dieser Blogserie:
- Teil 1 „Herausforderung Customer Centricity: Wie etabliert ist Datenanalyse im E-Commerce?„
- Teil 3 „Langfristige Kundenbindung mit Hilfe von „Advanced Analytics“
- Teil 4 „Wann bleiben die Kunden vor der Tür stehen? – Predictive Analytics mit Maschinellem Lernen“
- Teil 5 „Gezielte Kundenansprache dank KI“
- Teil 6 „Auf Interessen der Kunden reagieren: Intelligente Recommendations“
- Teil 7 „Data-Driven Marketing: Wie kundenzentrierte Ansprache in Zukunft gelingt in 3 Schritten“
Im letzten Blogbeitrag „Herausforderung Customer Centricity: Wie etabliert ist Datenanalyse im E-Commerce?“ haben wir über das Thema Customer Centricity gesprochen und wie gut Sie Ihre Kunden kennen. Aber welche Daten müssen Sie betrachten und welche Tools können Sie zur Auswertung verwenden?
Data-Driven Marketing in der Praxis
Technische Grundlegung und Erste Datenerkundung
Auf welchem Weg kommt ein Besucher auf meine Website? Wie verhält er sich dort? Welche Inhalte interessieren ihn besonders? Das ist nur ein Bruchteil der Fragen, die Sie mithilfe von Datenanalyse beantworten können, um ihre Kunden besser kennenzulernen oder den Erfolg ihrer Marketingaktivitäten zu bewerten.
Aber Datenanalyse kann noch sehr viel mehr! Anhand eines Fallbeispiels aus dem E-Commerce zeigen wir Ihnen, welche Daten Sie dafür betrachten müssen und welche Tools Sie zur Auswertung verwenden können. Schritt für Schritt wird veranschaulicht, wie Datenexploration und erste Analysen durchzuführen sind – vom Einlesen der Daten bis hin zur Visualisierung spezifischer Informationen.
Damit befähigen wir Sie, mithilfe von Open Source Tools wie Apache Spark eigene Reports zu erstellen. Gleichzeitig schaffen Sie damit die technische Grundlage für eine Analyse, die über das standardisierte „Klickraten-Monitoring“ hinausgeht.
Welche Daten sollte man nutzen?
Um die Nutzung der Unternehmensseite durch Internet-Besucher zu erfassen, kann man auf weitverbreitete Lösungen von Anbietern wie Google, Matomo, etracker und anderen zurückgreifen, oder durch eine eigene Implementierung die Events auf der Seite mitverfolgen. Daten zur Nutzung der Webpräsenz sind daher in vielen Unternehmen vorhanden, werden aber oft nur sehr oberflächlich genutzt, wie eine gemeinsame Studie von SHI und ibi research zeigt. Dabei bilden diese Daten durch unterschiedliche Arten der Analyse die Grundlage für verschiedene Anwendungen, wie die Optimierung der Webpräsenz, die Verbesserung der Suche, die Generierung von Empfehlungen, usw. Welche konkreten Möglichkeiten sich hierbei zur Unterstützung von Marketingaktivitäten ergeben, beleuchten wir in den Folgebeiträgen.
Damit wir die Vorgehensweise mit echten Daten zeigen können, greifen wir auf frei verfügbare Nutzungsdaten eines existierenden Online-Stores zurück, nämlich des Google Merchandise Store, in dem Fan-Produkte wie Tassen, T-Shirts, usw. verkauft werden. Diese dienen Google als Testdaten für die Google Analytics 360 Oberfläche, um die verschiedenen Visualisierungen, Analysen und Möglichkeiten zur Berichterstellung zu demonstrieren.
Wir werden jedoch direkt mit den Rohdaten arbeiten, da wir uns die Möglichkeit offen halten wollen, andere Analysen als die von Google Analytics angebotenen durchzuführen, z.B. indem wir die Webdaten mit anderen Daten z.B. aus dem CRM kombinieren, um zu zeigen, dass die Vorgehensweise auf eigene Daten oder Daten anderer Anbieter gleichermaßen anwendbar ist.
Die Google Analytics Demodaten lassen sich nicht direkt herunterladen, stehen aber als öffentliches Dataset als BigQuery-Data Warehouse auf der Google Cloud zu Verfügung. Hat man einen entsprechenden Account und Storage auf der Google Cloud bezogen, lassen sich die Daten aus dem Big-Query Dienst in den Google Storage exportieren, und können von dort aus auf die eigene Maschine heruntergeladen werden.
Das passende Tool für aussagekräftige Analytics: Apache Spark
Für den Start benötigen wir ein Tool, um die Daten einzulesen und zu analysieren. Wir haben Apache Spark ausgewählt, das für die verteilte Verarbeitung großer Datenmengen als Alternative zu Map-Reduce konzipiert wurde und über eine umfangreiche Bibliothek von Machine-Learning-Algorithmen verfügt. Der Einstieg in die Analyse und die Entwicklung von Prototypen wird in Spark stark durch das SQL Modul erleichtert, das mit den sog. DataFrames eine tabellenartige Datenstruktur mit einer SQL-artigen Schnittstelle zur Abfrage und Transformation der Daten zur Verfügung stellt. Darüber hinaus lassen sich mit Spark Programme schreiben, die in Produktion sehr große Datenmengen analysieren, indem sie auf der Cloud deployed und nach Bedarf skaliert werden. Hierfür muss man jedoch beim Schreiben des produktiven Spark-Programms darauf achten, dass man nicht unnötige Berechnungsschritte einbaut, die sich nicht parallelisieren lassen.
Um zunächst mit Spark die Daten zu erkunden und einfache Analysen durchzuführen, bietet sich an, in Jupyter ein sogenanntes Notebook zu erstellen. Dadurch sind wir in der Lage, das Programm Schritt für Schritt interaktiv zu entwickeln und im selben Zuge zu dokumentieren, um bspw. wichtige Ergebnisse zu visualisieren. Aus diesem Grund sind im Bereich Data Science Notebooks als Mittel für den Austausch und Dokumentation von Projekten sehr verbreitet.
Sowohl Spark als auch Jupyter lassen sich auf einem Laptop problemlos installieren und nutzen, siehe Referenzen.
Einlesen der Daten
Wir haben im Vorfeld ein Notebook geschrieben, in dem wir mit Hilfe von Spark die Daten erkunden, s. Abb. 1. Das komplette Notebook kann hier runtergeladen werden. Im Folgenden gehen wir die wesentlichen Schritte durch.
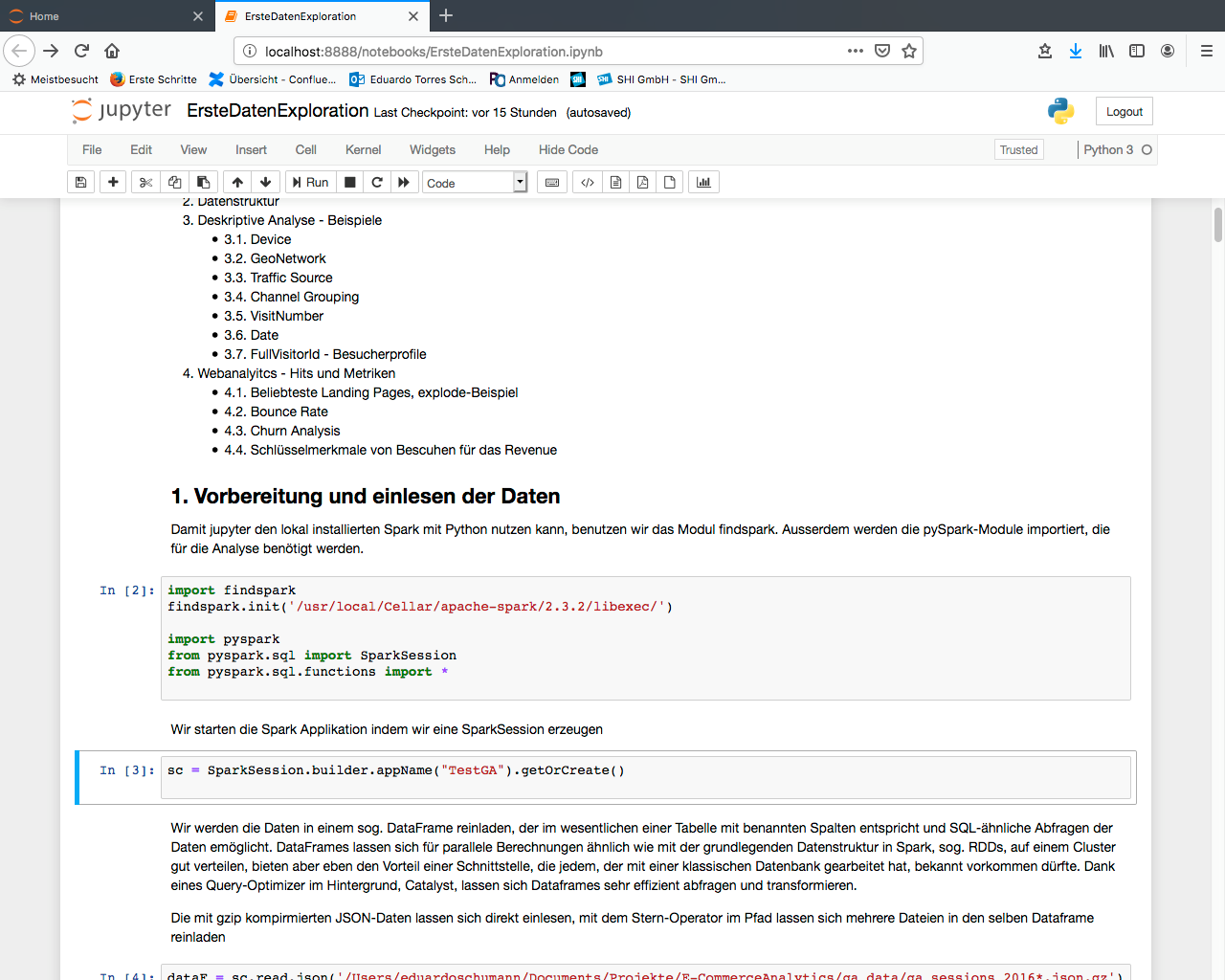
Datenexploration und erste Analysen
Ein Spark-Programm kann in Python, Java und Scala geschrieben werden, wobei sich je nach verwendeter Programmiersprache unterschiedliche Vor-und Nachteilen ergeben. Das Notebook ist in Python mit Hilfe von pyspark geschrieben.
Damit Jupyter den lokal installierten Spark nutzen kann, laden wir das Modul findspark und geben den Pfad zur lokalen Installation von Spark an. Außerdem werden die pySpark-Module importiert, die für die Analyse benötigt werden.

Wir starten die Spark-Anwendung indem wir eine SparkSession erzeugen:

Damit haben wir über verschiedene Schnittstellen Zugang zur Spark-Engine, die in diesem Fall auf der lokalen Maschine ausgeführt wird. Unter anderem sind wir in der Lage, ein sog. DataFrame zu erzeugen, in das wir die Daten hineinladen. Damit erhalten wir im Wesentlichen eine Tabelle mit benannten Spalten, die sich mit SQL abfragen lässt. DataFrames eignen sich gut für parallele Berechnungen, ähnlich wie die grundlegende Datenstruktur in Spark, sog. RDDs, bieten aber im Gegensatz dazu den Vorteil einer Schnittstelle, die jedem, der mit einer klassischen Datenbank vertraut ist, bekannt vorkommen dürfte. Dank eines Query-Optimizer im Hintergrund (Catalyst) lassen sich DataFrames ebenfalls sehr effizient abfragen und transformieren.
Die mit gzip komprimierten JSON-Daten lassen sich direkt einlesen, mit dem Stern-Operator im Pfad lassen sich mehrere Dateien in denselben DataFrame laden. Die Daten umfassen den Zeitraum 01.08.2016 – 01.08.2107, pro Tag ist eine separate Datei vorhanden.

Nachdem mit Hilfe des obigen Befehls alle Daten von 2016 in einem DataFrame vorhanden sind, können wir uns z.B. die Anzahl der Zeilen bzw. Spalten angeben lassen:

Datenschema
Jede Zeile des DataFrame stellt einen Besuch dar, während dessen ein Benutzer mit der Webseite interagiert hat.
Sehr hilfreich ist, dass Spark das Schema direkt von den Daten ableitet. Wir können uns dieses anzeigen lassen, um mehr über die 13 Spalten zu erfahren, die einen Besuch näher beschreiben:

Das Ergebnis ist in Abb. 2 in abgekürzter Form dargestellt:
Als Erstes fällt auf, dass die meisten Spalten ihrerseits eingebettete Strukturen mit einem eigenen Schema haben. Außerdem werden alle Werte als String eingelesen.
Einfache Spalten lassen sich leicht anhand ihres Namens interpretieren: date, fullVisitorId, visitId, visitStartTime, visitNumber
Andere Spalten haben jedoch Unterspalten (Typ struct), um verwandte Merkmale zusammenzufassen, so z.B. die Spalte device mit Eigenschaften des für den Besuch verwendeten Geräts. Verschiedene geographische Informationen werden hingegen in geoNetwork gesammelt, Details zur Herkunft des Besuchs unter trafficSource.
Die Spalte hits weist die komplexeste Struktur auf, um die Folge der im Prinzip beliebig vielen Interaktionen mit der Webseite innerhalb einer Sitzung zu erfassen. Daher ist sie von Typ array. Jedes Element in dieser Liste, ein hit, ist wiederum ein strukturiertes Objekt, das Informationen zu jeder Interaktion erfasst, etwa die besuchte Seite (page), vordefinierte Content-Gruppen (content), angezeigte Produkte (product), getätigte Käufe (transaction), usw.
Die Spalte totals fasst verschiedene Statistiken über die hits des Besuchs zusammen: Anzahl, die Gesamteinnahmen aller Transaktionen (totalTransactionRevenue), Anzahl der besuchten Seiten, usw.

Spark bietet verschiedene Funktionen, um den Datentyp einer Spalte anzupassen und mit den verschiedenen Arten von Verschachtelungen in einem DataFrame umzugehen. Damit können Abfragen ausgewertet werden, ohne dass dafür eine Denormalisierung nötig wäre, wie die kommenden Beispiele zeigen.
Exploration einzelner Dimensionen
Mit SQL-ähnlichen Abfragen können DataFrames leicht ausgewertet werden, um bspw. die Vorkommen einzelner Werte in einer Spalte zu zählen. Mit der Punkt-Notation lässt sich auf eine Unterspalte zugreifen. Das Ergebnis einer Abfrage ist wiederum ein DataFrame, der mit Hilfe von show() ausgegeben werden kann.

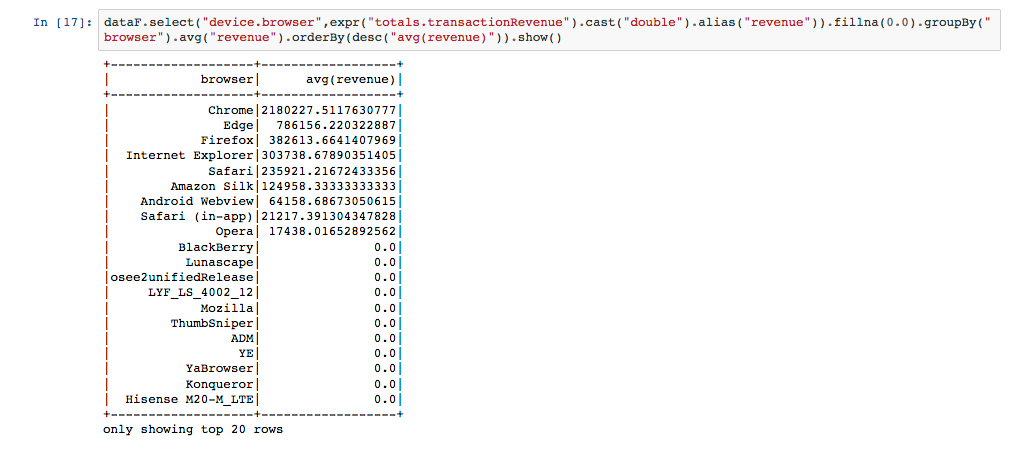
Da Daten als String eingelesen werden, müssen die Spalten konvertiert werden, bevor man numerische Werte wie das durchschnittliche Revenue berechnen kann. Hierfür nutzt man die Funktion cast(), mit fillna() werden null-Werte durch etwas geeignetes ersetzt.
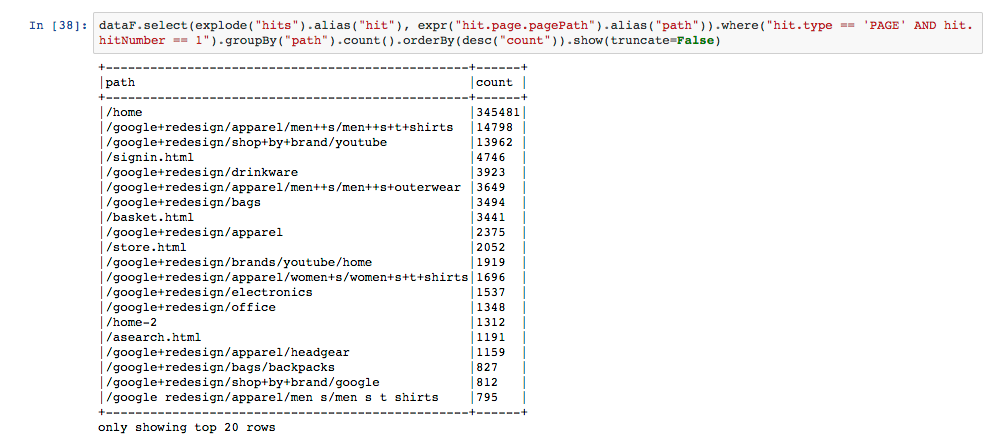
Wenn uns bspw. die häufigsten Landing Pages des Stores interessieren, muss in der Liste der hits von jedem Besuch die erste Interaktion gefunden werden, um anschließend die jeweils besuchten Seiten zusammen zu zählen. Dabei hilft uns die Funktion explode(), die eine neue Spalte und für jedes Element in hits eine neue Zeile im DataFrame erzeugt, sodass wir dann die üblichen Filter- und Aggregationsfunktionen über der neuen Spalte mit den „auseinander gefalteten“ hits nutzen können.
Die Funktion describe() ist nützlich für numerische Werte:
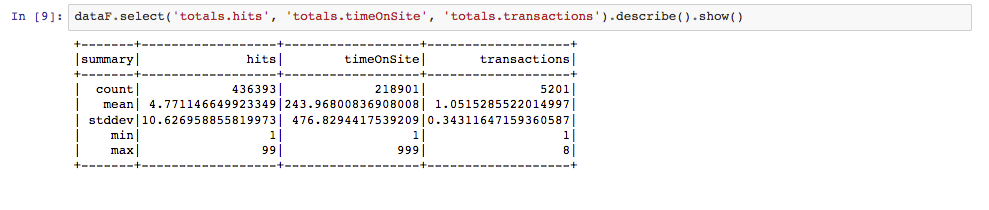
Mit Hilfe dieser Abfragen können wir im Prinzip für jedes Merkmal oder jede Spalte eine solche Statistik erzeugen, um die Daten zu erkunden und eine Idee über die Verteilung der Werte zu bekommen.
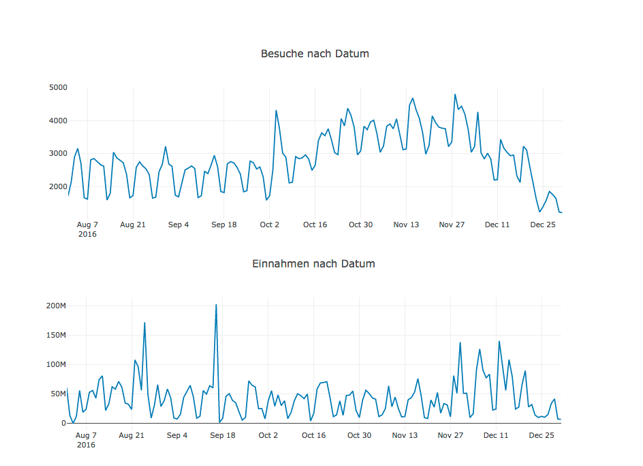
Anschaulicher ist es, in einem Notebook die Daten als Graphik darzustellen. Der übliche Weg hierfür geht in pyspark darüber, dass man das DataFrame mit Hilfe der Funktion toPandas() zu einem Pandas-Objekt konvertiert, das als Input für eine der weitverbreiteten python Graphik-Bibliotheken wie matplolib oder plotly dient. Beispiele finden sich im vorbereiteten Notebook. Aber Vorsicht: mit Spark kann man prinzipiell sehr große Datenmengen verarbeiten, dieser Weg der Visualisierung eignet sich jedoch nur für kleinere Datenmengen. Ansonsten werden sehr große Pandas-Objekte erzeugt, die in Spark nicht parallelisiert verarbeitet werden können und einen Flaschenhals in der Berechnung darstellen.
Zur deskriptiven Beschreibung der Daten haben wir mit Hilfe dieser Methode einzelne Dimensionen visualisiert.
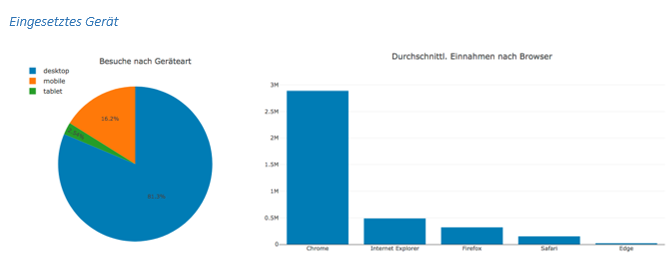
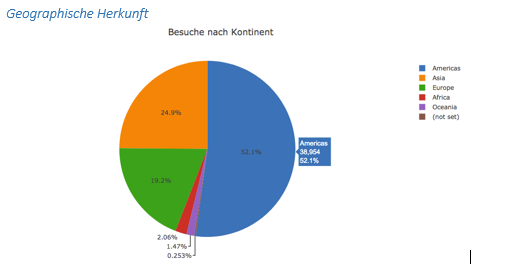
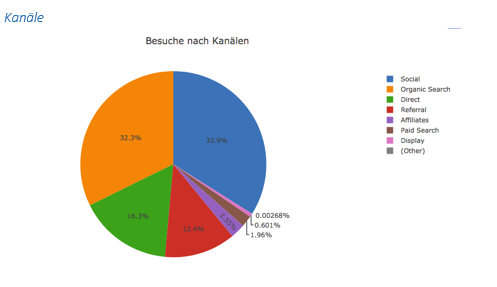
Die verschiedenen Quellen werden in Kanälen zusammenfasst, je nach Ursprung des Besuchs:
- Organic Search: Ergebnisse von Suchmaschinen
- Direct: Direkte Eingabe der Adresse im Browser, Bookmark
- Referral: Links auf einer fremden Seite
- Paid Search: Anzeige in der Google Suche
- Affiliates: Affiliate-Marketing Partner
- Display: Werbeanzeigen wie Banner
- Social: Soziale Netzwerke
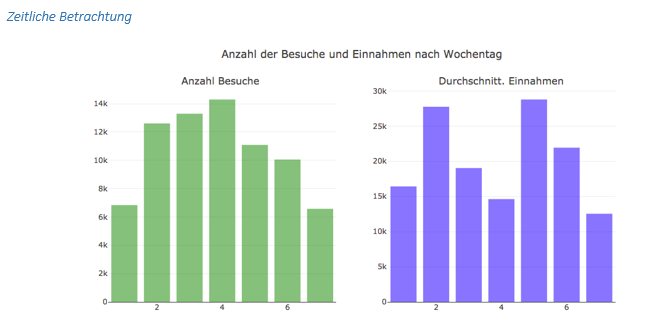
Bounce Rate
Eine einfache Analyse ist die Berechnung der Bounce Rate. Ein „Bounce“ ist ein Besuch, bei dem eine einzige Seite gesichtet wurde, um anschließend die Webpräsenz des Unternehmens zu verlassen, und wird daher als nicht erfolgreicher Besuch interpretiert.
Die Bounce Rate gibt den Anteil der Besuche an, die einen Bounce darstellen. Sie lässt sich mit einer Abfrage an das DataFrame berechnen, indem nach Besuchen gefiltert wird, die in der Spalte totals einen einzigen Hit und einen Bounce aufweisen, um anschließend die Besuche nach der Quelle zu aggregieren. Die Ergebnisse für die Top Quellen nach Anzahl der Besuche sind in Abb. 8 dargestellt.
Mit Hilfe von Open Source Tools wie Spark und Jupyter haben wir mit wenig Aufwand eine erste Exploration von Web Analytics Daten durchführen können, die sogar die Erstellung von einfachen Reports ermöglicht. Damit haben wir sowohl einen Überblick darüber gewonnen, wie Besuche der Unternehmensseite anhand von Web Analytics Daten beschrieben werden, als auch die technische Grundlage für tiefergehende Auswertungen gelegt.
Im nächsten Beitrag blicken wir deswegen auf verbreitete Analysen von Web Daten, die im Marketing Bereich eingesetzt werden, um unterschiedliche Kundengruppen zu identifizieren, sinnvolle Maßnahmen abzuleiten und sogar Voraussagen über die Zukunft zu treffen.
Referenzen:
- Google Merchandise Store: https://www.googlemerchandisestore.com/
- Google BigQuery: https://cloud.google.com/bigquery/?hl=de
- Apache Spark: https://spark.apache.org/
- Downloading Spark and Getting Started: https://intellipaat.com/blog/tutorial/spark-tutorial/downloading-spark-and-getting-started/
- Jupyter: https://jupyter.org/
- Installing Jupyter Notebook: https://jupyter.readthedocs.io/en/latest/install.html
- Notebook Erste Datenexploration
- findspark: https://pypi.org/project/findspark/
- Pandas: https://pandas.pydata.org/
- matplolib: https://matplotlib.org/
- plotly: https://plot.ly/
Sie wollen wissen wie es weitergeht? Hier geht´s zum 3. Teil der Blogserie „Langfristige Kundenbindung mit Hilfe von „Advanced Analytics“.


