

Die SolrCloud bietet eine Reihe von Mechanismen, um die Ausfallsicherheit des Clusters zu erhöhen. Dazu gehört zum einen die Verteilung der indexierten Daten auf mehrere Solr-Knoten und zum anderen das Management des Clusters durch ZooKeeper. Vor Allem aber die Möglichkeit, Indexe auf andere Knoten zu replizieren, schützt vor Fehlern und Nicht-Erreichbarkeiten der Daten bei einem Ausfall. Sollte einer der Solr-Knoten ausfallen, ist durch die Replikation sichergestellt, dass die bereits indexierten Daten weiterhin durchsuchbar sind und neue Indexierungsanfragen wie gewohnt angenommen werden können. Auf diese Weise können n-1 Ausfälle (wobei n die Anzahl an Repliken einer Shard sei) von der SolrCloud verschmerzt und aufgefangen werden. Das neueste Solr-Release 7.1.0 bietet darüber hinaus nun die Möglichkeit, Ausfälle nicht nur zu tolerieren, sondern weggebrochene Repliken automatisch zu ersetzen.
Das Setup
Stellen wir uns folgendes Szenario vor: In unserer SolrCloud befinden sich drei Solr-Knoten (host1:8983_solr, host2:8983_solr, host3:8983_solr) auf drei verschiedenen physischen Servern. Es existiert eine Collection mit einer Shard, die auf zwei Solr-Knoten (host1:8983_solr und host2:8983_solr) repliziert ist. Das Anlegen einer solchen Collection könnte über den folgenden API-Aufruf geschehen sein: https://host1:8983/solr/admin/collections?action=CREATE&name=testcollection&numShards=1 &replicationFactor=2
Der Ausfall
Durch einen Stromausfall in dem Gebäude, in dem Server host2 beheimatet ist, fällt der Server – und damit der Solr-Knoten host2:8983_solr – aus. Der Ausfall hat vorerst keine fehlerproduzierenden Auswirkungen, da sowohl alle Indexierungsprozesse als auch alle Suchanfragen weiterhin korrekt abgearbeitet werden. Dennoch beeinflusst der Ausfall die Antwortzeiten auf Suchanfragen negativ, da nunmehr lediglich einer statt zwei Solr-Knoten die hohe Anzahl an Suchanfragen an die eine Shard der Collection bearbeiten kann.
„ Da wir eine Solr-Version vor 7.1.0 für die SolrCloud verwenden, müssen wir entweder die verschlechterte Performanz akzeptieren oder eigene Mechanismen einbauen, welche die nicht mehr erreichbaren Indexe auf intakte Solr-Knoten replizieren.“
Wäre es nicht angenehmer, wenn sich das System selbst um diese Replikation kümmern würde, sodass ein Ausfall beinahe unbemerkt an uns vorüberzieht? Diese Frage haben sich die Entwickler der Suchmaschine offenbar auch gestellt und in die Version 7.1.0 einen Mechanismus integriert, der genau solche Szenarien automatisch abfängt und so für noch mehr Ausfallsicherheit sorgt.
Der Einfall
Ab Solr 7.1.0 steht nun allen Solr-Anwendern der zusätzliche Parameter autoAddReplicas zur Verfügung, welcher vorher exklusiv HDFS-Nutzern vorbehalten war. Dieses Feature und der damit verbundene Trigger-Mechanismus sorgen nun für automatisches Replizieren, sobald ein Solr-Knoten aus dem Cluster fällt. Lediglich zwei Schritte sind notwendig, um diese mächtige Funktionalität zu nutzen:
- Beim Anlegen einer Collection muss der Parameter replicationFactor gesetzt werden. Dieser gibt die minimale Anzahl an Repliken an, die für eine Shard der Collection aktiv sein sollen. Sinkt die Anzahl unter den Wert von replicationFactor, so sorgt der neue autoAddReplicas-Mechanismus für die Erzeugung neuer Repliken.
- Der Parameter autoAddReplicas muss für die Collection aktiviert werden. Die Aktivierung kann über die Collections-API durchgeführt werden:
https://host1:8983/solr/admin/collections?action=MODIFYCOLLECTION &collection=testcollection&autoAddReplicas=true
Was nun bei einem Ausfall von host2:8983_solr passiert, kann über den SolrCloud-Graphen auf der Administrationsseite verfolgt werden:
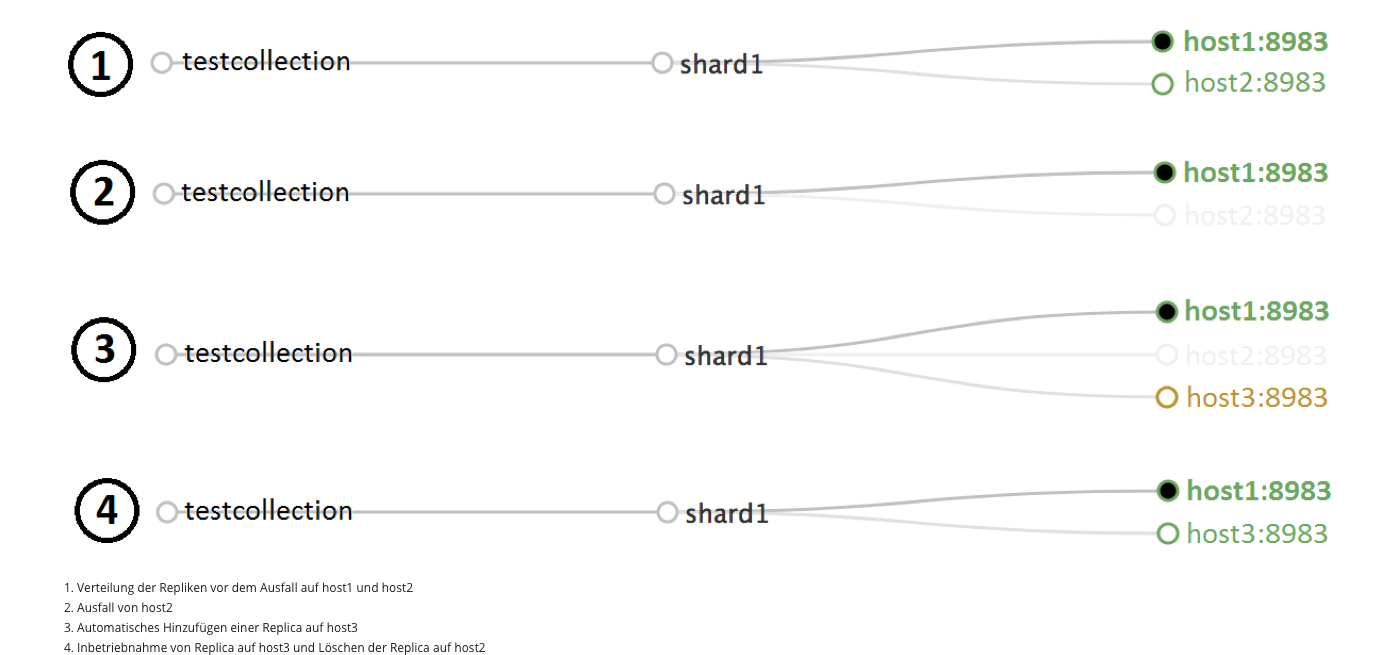
Das Fazit
Mit der neuen Möglichkeit autoAddReplicas kann die SolrCloud noch stärker und automatisierter vor dem Ausfall eines Solr-Servers geschützt werden. Das Feature bietet damit zusätzlichen Schutz vor Nicht-Erreichbarkeit der Daten und Performanz-Verlusten.


